 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasy-IIL: Reducing Human Operational Burden in Interactive Imitation Learning via Assistant Experts
Mar 13, 2026Interactive Imitation Learning (IIL) typically relies on extensive human involvement for both offline demonstration and online interaction. Prior work primarily focuses on reducing human effort in passive monitoring rather than active operation. Interestingly, structured model-based imitation approaches achieve comparable performance with significantly fewer demonstrations than end-to-end imitation learning policies in the low-data regime. However, these methods are typically surpassed by end-to-end policies as the data increases. Leveraging this insight, we propose Easy-IIL, a framework that utilizes off-the-shelf model-based imitation methods as an assistant expert to replace active human operation for the majority of data collection. The human expert only provides a single demonstration to initialize the assistant expert and intervenes in critical states where the task is approaching failure. Furthermore, Easy-IIL can maintain IIL performance by preserving both offline and online data quality. Extensive simulation and real-world experiments demonstrate that Easy-IIL significantly reduces human operational burden while maintaining performance comparable to mainstream IIL baselines. User studies further confirm that Easy-IIL reduces subjective workload on the human expert. Project page: https://sites.google.com/view/easy-iil
Keyword Mamba: Spoken Keyword Spotting with State Space Models
Aug 10, 2025Keyword spotting (KWS) is an essential task in speech processing. It is widely used in voice assistants and smart devices. Deep learning models like CNNs, RNNs, and Transformers have performed well in KWS. However, they often struggle to handle long-term patterns and stay efficient at the same time. In this work, we present Keyword Mamba, a new architecture for KWS. It uses a neural state space model (SSM) called Mamba. We apply Mamba along the time axis and also explore how it can replace the self-attention part in Transformer models. We test our model on the Google Speech Commands datasets. The results show that Keyword Mamba reaches strong accuracy with fewer parameters and lower computational cost. To our knowledge, this is the first time a state space model has been used for KWS. These results suggest that Mamba has strong potential in speech-related tasks.
FUNCTO: Function-Centric One-Shot Imitation Learning for Tool Manipulation
Feb 17, 2025



Learning tool use from a single human demonstration video offers a highly intuitive and efficient approach to robot teaching. While humans can effortlessly generalize a demonstrated tool manipulation skill to diverse tools that support the same function (e.g., pouring with a mug versus a teapot), current one-shot imitation learning (OSIL) methods struggle to achieve this. A key challenge lies in establishing functional correspondences between demonstration and test tools, considering significant geometric variations among tools with the same function (i.e., intra-function variations). To address this challenge, we propose FUNCTO (Function-Centric OSIL for Tool Manipulation), an OSIL method that establishes function-centric correspondences with a 3D functional keypoint representation, enabling robots to generalize tool manipulation skills from a single human demonstration video to novel tools with the same function despite significant intra-function variations. With this formulation, we factorize FUNCTO into three stages: (1) functional keypoint extraction, (2) function-centric correspondence establishment, and (3) functional keypoint-based action planning. We evaluate FUNCTO against exiting modular OSIL methods and end-to-end behavioral cloning methods through real-robot experiments on diverse tool manipulation tasks. The results demonstrate the superiority of FUNCTO when generalizing to novel tools with intra-function geometric variations. More details are available at https://sites.google.com/view/functo.
Leveraging Semantic and Geometric Information for Zero-Shot Robot-to-Human Handover
Sep 26, 2024Human-robot interaction (HRI) encompasses a wide range of collaborative tasks, with handover being one of the most fundamental. As robots become more integrated into human environments, the potential for service robots to assist in handing objects to humans is increasingly promising. In robot-to-human (R2H) handover, selecting the optimal grasp is crucial for success, as it requires avoiding interference with the humans preferred grasp region and minimizing intrusion into their workspace. Existing methods either inadequately consider geometric information or rely on data-driven approaches, which often struggle to generalize across diverse objects. To address these limitations, we propose a novel zero-shot system that combines semantic and geometric information to generate optimal handover grasps. Our method first identifies grasp regions using semantic knowledge from vision-language models (VLMs) and, by incorporating customized visual prompts, achieves finer granularity in region grounding. A grasp is then selected based on grasp distance and approach angle to maximize human ease and avoid interference. We validate our approach through ablation studies and real-world comparison experiments. Results demonstrate that our system improves handover success rates and provides a more user-preferred interaction experience. Videos, appendixes and more are available at https://sites.google.com/view/vlm-handover/.
RTAGrasp: Learning Task-Oriented Grasping from Human Videos via Retrieval, Transfer, and Alignment
Sep 24, 2024Task-oriented grasping (TOG) is crucial for robots to accomplish manipulation tasks, requiring the determination of TOG positions and directions. Existing methods either rely on costly manual TOG annotations or only extract coarse grasping positions or regions from human demonstrations, limiting their practicality in real-world applications. To address these limitations, we introduce RTAGrasp, a Retrieval, Transfer, and Alignment framework inspired by human grasping strategies. Specifically, our approach first effortlessly constructs a robot memory from human grasping demonstration videos, extracting both TOG position and direction constraints. Then, given a task instruction and a visual observation of the target object, RTAGrasp retrieves the most similar human grasping experience from its memory and leverages semantic matching capabilities of vision foundation models to transfer the TOG constraints to the target object in a training-free manner. Finally, RTAGrasp aligns the transferred TOG constraints with the robot's action for execution. Evaluations on the public TOG benchmark, TaskGrasp dataset, show the competitive performance of RTAGrasp on both seen and unseen object categories compared to existing baseline methods. Real-world experiments further validate its effectiveness on a robotic arm. Our code, appendix, and video are available at \url{https://sites.google.com/view/rtagrasp/home}.
FoundationGrasp: Generalizable Task-Oriented Grasping with Foundation Models
Apr 16, 2024
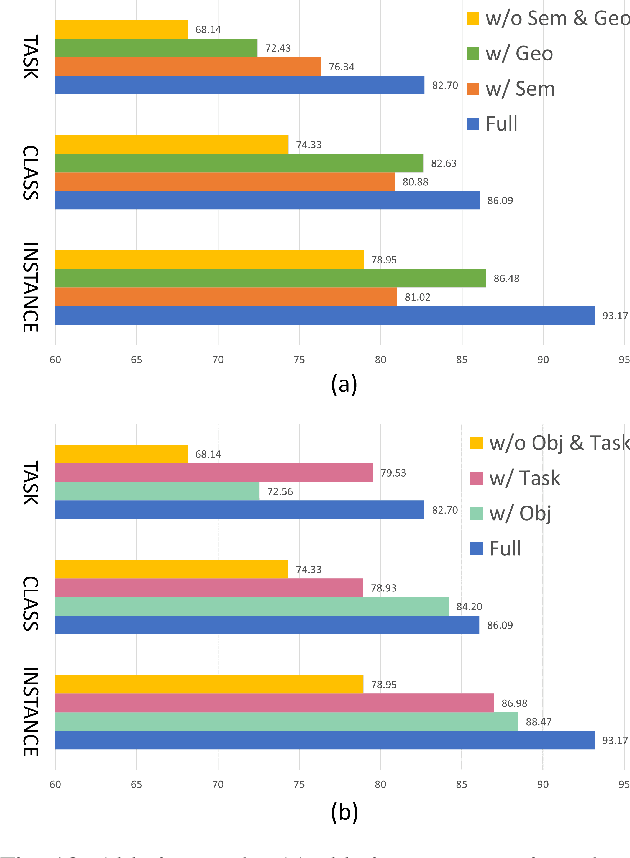


Task-oriented grasping (TOG), which refers to the problem of synthesizing grasps on an object that are configurationally compatible with the downstream manipulation task, is the first milestone towards tool manipulation. Analogous to the activation of two brain regions responsible for semantic and geometric reasoning during cognitive processes, modeling the complex relationship between objects, tasks, and grasps requires rich prior knowledge about objects and tasks. Existing methods typically limit the prior knowledge to a closed-set scope and cannot support the generalization to novel objects and tasks out of the training set. To address such a limitation, we propose FoundationGrasp, a foundation model-based TOG framework that leverages the open-ended knowledge from foundation models to learn generalizable TOG skills. Comprehensive experiments are conducted on the contributed Language and Vision Augmented TaskGrasp (LaViA-TaskGrasp) dataset, demonstrating the superiority of FoudationGrasp over existing methods when generalizing to novel object instances, object classes, and tasks out of the training set. Furthermore, the effectiveness of FoudationGrasp is validated in real-robot grasping and manipulation experiments on a 7 DoF robotic arm. Our code, data, appendix, and video are publicly available at https://sites.google.com/view/foundationgrasp.