 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularized Schrödinger Bridge: Alleviating Distortion and Exposure Bias in Solving Inverse Problems
Nov 19, 2025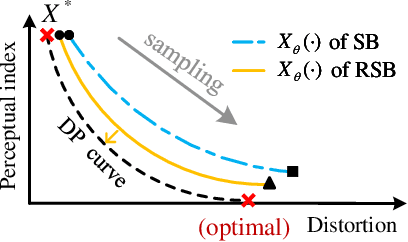
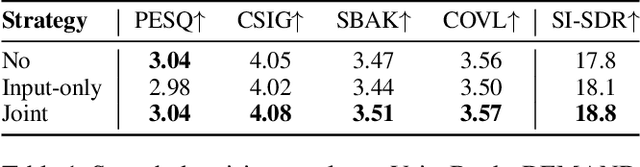
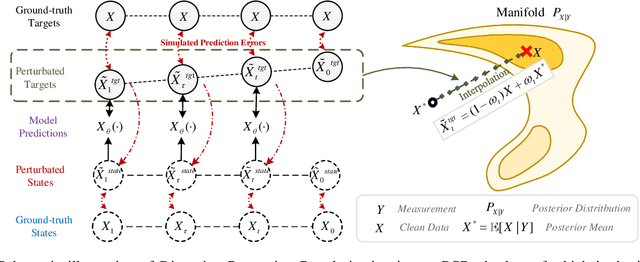

Diffusion models serve as a powerful generative framework for solving inverse problems. However, they still face two key challenges: 1) the distortion-perception tradeoff, where improving perceptual quality often degrades reconstruction fidelity, and 2) the exposure bias problem, where the training-inference input mismatch leads to prediction error accumulation and reduced reconstruction quality. In this work, we propose the Regularized Schrödinger Bridge (RSB), an adaptation of Schrödinger Bridge tailored for inverse problems that addresses the above limitations. RSB employs a novel regularized training strategy that perturbs both the input states and targets, effectively mitigating exposure bias by exposing the model to simulated prediction errors and also alleviating distortion by well-designed interpolation via the posterior mean. Extensive experiments on two typical inverse problems for speech enhancement demonstrate that RSB outperforms state-of-the-art methods, significantly improving distortion metrics and effectively reducing exposure bias.
Keyword Mamba: Spoken Keyword Spotting with State Space Models
Aug 10, 2025Keyword spotting (KWS) is an essential task in speech processing. It is widely used in voice assistants and smart devices. Deep learning models like CNNs, RNNs, and Transformers have performed well in KWS. However, they often struggle to handle long-term patterns and stay efficient at the same time. In this work, we present Keyword Mamba, a new architecture for KWS. It uses a neural state space model (SSM) called Mamba. We apply Mamba along the time axis and also explore how it can replace the self-attention part in Transformer models. We test our model on the Google Speech Commands datasets. The results show that Keyword Mamba reaches strong accuracy with fewer parameters and lower computational cost. To our knowledge, this is the first time a state space model has been used for KWS. These results suggest that Mamba has strong potential in speech-related tasks.
Rebalanced Multimodal Learning with Data-aware Unimodal Sampling
Mar 05, 2025To address the modality learning degeneration caused by modality imbalance, existing multimodal learning~(MML) approaches primarily attempt to balance the optimization process of each modality from the perspective of model learning. However, almost all existing methods ignore the modality imbalance caused by unimodal data sampling, i.e., equal unimodal data sampling often results in discrepancies in informational content, leading to modality imbalance. Therefore, in this paper, we propose a novel MML approach called \underline{D}ata-aware \underline{U}nimodal \underline{S}ampling~(\method), which aims to dynamically alleviate the modality imbalance caused by sampling. Specifically, we first propose a novel cumulative modality discrepancy to monitor the multimodal learning process. Based on the learning status, we propose a heuristic and a reinforcement learning~(RL)-based data-aware unimodal sampling approaches to adaptively determine the quantity of sampled data at each iteration, thus alleviating the modality imbalance from the perspective of sampling. Meanwhile, our method can be seamlessly incorporated into almost all existing multimodal learning approaches as a plugin. Experiments demonstrate that \method~can achieve the best performance by comparing with diverse state-of-the-art~(SOTA) baselines.
EDSep: An Effective Diffusion-Based Method for Speech Source Separation
Jan 27, 2025


Generative models have attracted considerable attention for speech separation tasks, and among these, diffusion-based methods are being explored. Despite the notable success of diffusion techniques in generation tasks, their adaptation to speech separation has encountered challenges, notably slow convergence and suboptimal separation outcomes. To address these issues and enhance the efficacy of diffusion-based speech separation, we introduce EDSep, a novel single-channel method grounded in score matching via stochastic differential equation (SDE). This method enhances generative modeling for speech source separation by optimizing training and sampling efficiency. Specifically, a novel denoiser function is proposed to approximate data distributions, which obtains ideal denoiser outputs. Additionally, a stochastic sampler is carefully designed to resolve the reverse SDE during the sampling process, gradually separating speech from mixtures. Extensive experiments on databases such as WSJ0-2mix, LRS2-2mix, and VoxCeleb2-2mix demonstrate our proposed method's superior performance over existing diffusion and discriminative models, validating its efficacy.
An Empirical Study of Super-resolution on Low-resolution Micro-expression Recognition
Oct 16, 2023



Micro-expression recognition (MER) in low-resolution (LR) scenarios presents an important and complex challenge, particularly for practical applications such as group MER in crowded environments. Despite considerable advancements in super-resolution techniques for enhancing the quality of LR images and videos, few study has focused on investigate super-resolution for improving LR MER. The scarcity of investigation can be attributed to the inherent difficulty in capturing the subtle motions of micro-expressions, even in original-resolution MER samples, which becomes even more challenging in LR samples due to the loss of distinctive features. Furthermore, a lack of systematic benchmarking and thorough analysis of super-resolution-assisted MER methods has been noted. This paper tackles these issues by conducting a series of benchmark experiments that integrate both super-resolution (SR) and MER methods, guided by an in-depth literature survey. Specifically, we employ seven cutting-edge state-of-the-art (SOTA) MER techniques and evaluate their performance on samples generated from 13 SOTA SR techniques, thereby addressing the problem of super-resolution in MER. Through our empirical study, we uncover the primary challenges associated with SR-assisted MER and identify avenues to tackle these challenges by leveraging recent advancements in both SR and MER methodologies. Our analysis provides insights for progressing toward more efficient SR-assisted MER.
Towards A Robust Group-level Emotion Recognition via Uncertainty-Aware Learning
Oct 06, 2023



Group-level emotion recognition (GER) is an inseparable part of human behavior analysis, aiming to recognize an overall emotion in a multi-person scene. However, the existing methods are devoted to combing diverse emotion cues while ignoring the inherent uncertainties under unconstrained environments, such as congestion and occlusion occurring within a group. Additionally, since only group-level labels are available, inconsistent emotion predictions among individuals in one group can confuse the network. In this paper, we propose an uncertainty-aware learning (UAL) method to extract more robust representations for GER. By explicitly modeling the uncertainty of each individual, we utilize stochastic embedding drawn from a Gaussian distribution instead of deterministic point embedding. This representation captures the probabilities of different emotions and generates diverse predictions through this stochasticity during the inference stage. Furthermore, uncertainty-sensitive scores are adaptively assigned as the fusion weights of individuals' face within each group. Moreover, we develop an image enhancement module to enhance the model's robustness against severe noise. The overall three-branch model, encompassing face, object, and scene component, is guided by a proportional-weighted fusion strategy and integrates the proposed uncertainty-aware method to produce the final group-level output. Experimental results demonstrate the effectiveness and generalization ability of our method across three widely used databases.
Label Structure Preserving Contrastive Embedding for Multi-Label Learning with Missing Labels
Sep 03, 2022



Contrastive learning (CL) has shown impressive advances in image representation learning in whichever supervised multi-class classification or unsupervised learning. However, these CL methods fail to be directly adapted to multi-label image classification due to the difficulty in defining the positive and negative instances to contrast a given anchor image in multi-label scenario, let the label missing one alone, implying that borrowing a commonly-used way from contrastive multi-class learning to define them will incur a lot of false negative instances unfavorable for learning. In this paper, with the introduction of a label correction mechanism to identify missing labels, we first elegantly generate positives and negatives for individual semantic labels of an anchor image, then define a unique contrastive loss for multi-label image classification with missing labels (CLML), the loss is able to accurately bring images close to their true positive images and false negative images, far away from their true negative images. Different from existing multi-label CL losses, CLML also preserves low-rank global and local label dependencies in the latent representation space where such dependencies have been shown to be helpful in dealing with missing labels. To the best of our knowledge, this is the first general multi-label CL loss in the missing-label scenario and thus can seamlessly be paired with those losses of any existing multi-label learning methods just via a single hyperparameter. The proposed strategy has been shown to improve the classification performance of the Resnet101 model by margins of 1.2%, 1.6%, and 1.3% respectively on three standard datasets, MSCOCO, VOC, and NUS-WIDE. Code is available at https://github.com/chuangua/ContrastiveLossMLML.
Region attention and graph embedding network for occlusion objective class-based micro-expression recognition
Jul 13, 2021
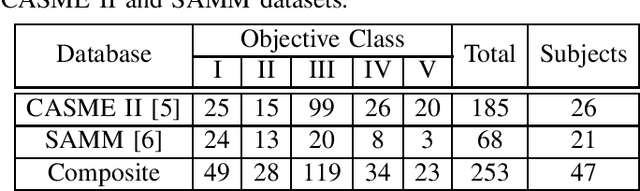
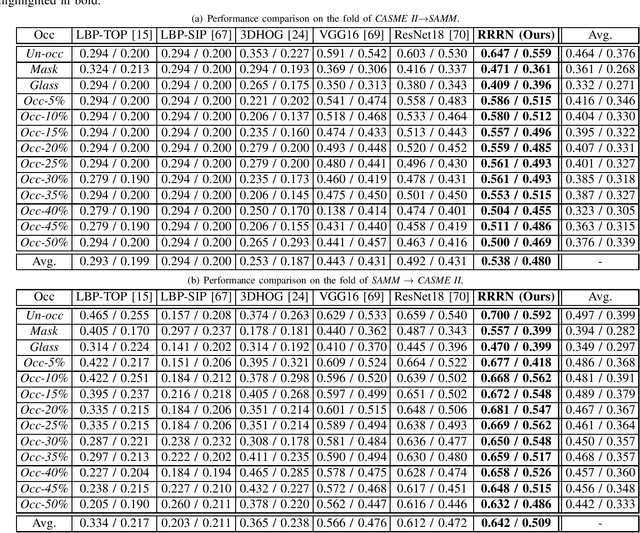
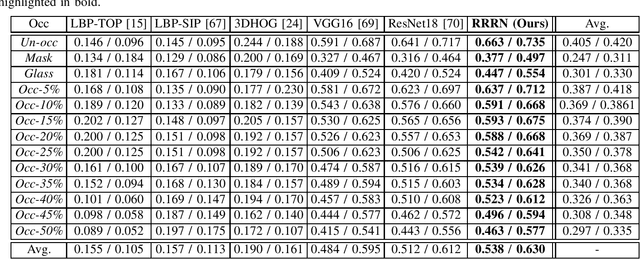
Micro-expression recognition (\textbf{MER}) has attracted lots of researchers' attention in a decade. However, occlusion will occur for MER in real-world scenarios. This paper deeply investigates an interesting but unexplored challenging issue in MER, \ie, occlusion MER. First, to research MER under real-world occlusion, synthetic occluded micro-expression databases are created by using various mask for the community. Second, to suppress the influence of occlusion, a \underline{R}egion-inspired \underline{R}elation \underline{R}easoning \underline{N}etwork (\textbf{RRRN}) is proposed to model relations between various facial regions. RRRN consists of a backbone network, the Region-Inspired (\textbf{RI}) module and Relation Reasoning (\textbf{RR}) module. More specifically, the backbone network aims at extracting feature representations from different facial regions, RI module computing an adaptive weight from the region itself based on attention mechanism with respect to the unobstructedness and importance for suppressing the influence of occlusion, and RR module exploiting the progressive interactions among these regions by performing graph convolutions. Experiments are conducted on handout-database evaluation and composite database evaluation tasks of MEGC 2018 protocol. Experimental results show that RRRN can significantly explore the importance of facial regions and capture the cooperative complementary relationship of facial regions for MER. The results also demonstrate RRRN outperforms the state-of-the-art approaches, especially on occlusion, and RRRN acts more robust to occlusion.
Feature refinement: An expression-specific feature learning and fusion method for micro-expression recognition
Jan 13, 2021



Micro-Expression Recognition has become challenging, as it is extremely difficult to extract the subtle facial changes of micro-expressions. Recently, several approaches proposed several expression-shared features algorithms for micro-expression recognition. However, they do not reveal the specific discriminative characteristics, which lead to sub-optimal performance. This paper proposes a novel Feature Refinement ({FR}) with expression-specific feature learning and fusion for micro-expression recognition. It aims to obtain salient and discriminative features for specific expressions and also predict expression by fusing the expression-specific features. FR consists of an expression proposal module with attention mechanism and a classification branch. First, an inception module is designed based on optical flow to obtain expression-shared features. Second, in order to extract salient and discriminative features for specific expression, expression-shared features are fed into an expression proposal module with attention factors and proposal loss. Last, in the classification branch, labels of categories are predicted by a fusion of the expression-specific features. Experiments on three publicly available databases validate the effectiveness of FR under different protocol. Results on public benchmarks demonstrate that our FR provides salient and discriminative information for micro-expression recognition. The results also show our FR achieves better or competitive performance with the existing state-of-the-art methods on micro-expression recognition.
Objective Class-based Micro-Expression Recognition through Simultaneous Action Unit Detection and Feature Aggregation
Dec 24, 2020



Micro-expression recognition (MER) has attracted lots of researchers' attention due to its potential value in many practical applications. In this paper, we investigate Micro-Expression Recognition (MER) is a challenging task as the subtle changes occur over different action regions of a face. Changes in facial action regions are formed as Action Units (AUs), and AUs in micro-expressions can be seen as the actors in cooperative group activities. In this paper, we propose a novel deep neural network model for objective class-based MER, which simultaneously detects AUs and aggregates AU-level features into micro-expression-level representation through Graph Convolutional Networks (GCN). Specifically, we propose two new strategies in our AU detection module for more effective AU feature learning: the attention mechanism and the balanced detection loss function. With those two strategies, features are learned for all the AUs in a unified model, eliminating the error-prune landmark detection process and tedious separate training for each AU. Moreover, our model incorporates a tailored objective class-based AU knowledge-graph, which facilitates the GCN to aggregate the AU-level features into a micro-expression-level feature representation. Extensive experiments on two tasks in MEGC 2018 show that our approach significantly outperforms the current state-of-the-arts in MER. Additionally, we also report our single model-based micro-expression AU detection results.