 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiM-GeoAttn-Net: Linear-Time Depth Modeling with Geometry-Aware Attention for 3D Aortic Dissection CTA Segmentation
Feb 27, 2026Accurate segmentation of aortic dissection (AD) lumens in CT angiography (CTA) is essential for quantitative morphological assessment and clinical decision-making. However, reliable 3D delineation remains challenging due to limited long-range context modeling, which compromises inter-slice coherence, and insufficient structural discrimination under low-contrast conditions. To address these limitations, we propose BiM-GeoAttn-Net, a lightweight framework that integrates linear-time depth-wise state-space modeling with geometry-aware vessel refinement. Our approach is featured by Bidirectional Depth Mamba (BiM) to efficiently capture cross-slice dependencies and Geometry-Aware Vessel Attention (GeoAttn) module that employs orientation-sensitive anisotropic filtering to refine tubular structures and sharpen ambiguous boundaries. Extensive experiments on a multi-source AD CTA dataset demonstrate that BiM-GeoAttn-Net achieves a Dice score of 93.35% and an HD95 of 12.36 mm, outperforming representative CNN-, Transformer-, and SSM-based baselines in overlap metrics while maintaining competitive boundary accuracy. These results suggest that coupling linear-time depth modeling with geometry-aware refinement provides an effective, computationally efficient solution for robust 3D AD segmentation.
SpectralMamba-UNet: Frequency-Disentangled State Space Modeling for Texture-Structure Consistent Medical Image Segmentation
Feb 26, 2026Accurate medical image segmentation requires effective modeling of both global anatomical structures and fine-grained boundary details. Recent state space models (e.g., Vision Mamba) offer efficient long-range dependency modeling. However, their one-dimensional serialization weakens local spatial continuity and high-frequency representation. To this end, we propose SpectralMamba-UNet, a novel frequency-disentangled framework to decouple the learning of structural and textural information in the spectral domain. Our Spectral Decomposition and Modeling (SDM) module applies discrete cosine transform to decompose low- and high-frequency features, where low frequency contributes to global contextual modeling via a frequency-domain Mamba and high frequency preserves boundary-sensitive details. To balance spectral contributions, we introduce a Spectral Channel Reweighting (SCR) mechanism to form channel-wise frequency-aware attention, and a Spectral-Guided Fusion (SGF) module to achieve adaptively multi-scale fusion in the decoder. Experiments on five public benchmarks demonstrate consistent improvements across diverse modalities and segmentation targets, validating the effectiveness and generalizability of our approach.
SAQNN: Spectral Adaptive Quantum Neural Network as a Universal Approximator
Feb 10, 2026Quantum machine learning (QML), as an interdisciplinary field bridging quantum computing and machine learning, has garnered significant attention in recent years. Currently, the field as a whole faces challenges due to incomplete theoretical foundations for the expressivity of quantum neural networks (QNNs). In this paper we propose a constructive QNN model and demonstrate that it possesses the universal approximation property (UAP), which means it can approximate any square-integrable function up to arbitrary accuracy. Furthermore, it supports switching function bases, thus adaptable to various scenarios in numerical approximation and machine learning. Our model has asymptotic advantages over the best classical feed-forward neural networks in terms of circuit size and achieves optimal parameter complexity when approximating Sobolev functions under $L_2$ norm.
TransforMARS: Fault-Tolerant Self-Reconfiguration for Arbitrarily Shaped Modular Aerial Robot Systems
Sep 17, 2025Modular Aerial Robot Systems (MARS) consist of multiple drone modules that are physically bound together to form a single structure for flight. Exploiting structural redundancy, MARS can be reconfigured into different formations to mitigate unit or rotor failures and maintain stable flight. Prior work on MARS self-reconfiguration has solely focused on maximizing controllability margins to tolerate a single rotor or unit fault for rectangular-shaped MARS. We propose TransforMARS, a general fault-tolerant reconfiguration framework that transforms arbitrarily shaped MARS under multiple rotor and unit faults while ensuring continuous in-air stability. Specifically, we develop algorithms to first identify and construct minimum controllable assemblies containing faulty units. We then plan feasible disassembly-assembly sequences to transport MARS units or subassemblies to form target configuration. Our approach enables more flexible and practical feasible reconfiguration. We validate TransforMARS in challenging arbitrarily shaped MARS configurations, demonstrating substantial improvements over prior works in both the capacity of handling diverse configurations and the number of faults tolerated. The videos and source code of this work are available at the anonymous repository: https://anonymous.4open.science/r/TransforMARS-1030/
Noise-Injected Spiking Graph Convolution for Energy-Efficient 3D Point Cloud Denoising
Feb 27, 2025



Spiking neural networks (SNNs), inspired by the spiking computation paradigm of the biological neural systems, have exhibited superior energy efficiency in 2D classification tasks over traditional artificial neural networks (ANNs). However, the regression potential of SNNs has not been well explored, especially in 3D point cloud processing.In this paper, we propose noise-injected spiking graph convolutional networks to leverage the full regression potential of SNNs in 3D point cloud denoising. Specifically, we first emulate the noise-injected neuronal dynamics to build noise-injected spiking neurons. On this basis, we design noise-injected spiking graph convolution for promoting disturbance-aware spiking representation learning on 3D points. Starting from the spiking graph convolution, we build two SNN-based denoising networks. One is a purely spiking graph convolutional network, which achieves low accuracy loss compared with some ANN-based alternatives, while resulting in significantly reduced energy consumption on two benchmark datasets, PU-Net and PC-Net. The other is a hybrid architecture that combines ANN-based learning with a high performance-efficiency trade-off in just a few time steps. Our work lights up SNN's potential for 3D point cloud denoising, injecting new perspectives of exploring the deployment on neuromorphic chips while paving the way for developing energy-efficient 3D data acquisition devices.
Boosting Gradient Ascent for Continuous DR-submodular Maximization
Jan 16, 2024Projected Gradient Ascent (PGA) is the most commonly used optimization scheme in machine learning and operations research areas. Nevertheless, numerous studies and examples have shown that the PGA methods may fail to achieve the tight approximation ratio for continuous DR-submodular maximization problems. To address this challenge, we present a boosting technique in this paper, which can efficiently improve the approximation guarantee of the standard PGA to \emph{optimal} with only small modifications on the objective function. The fundamental idea of our boosting technique is to exploit non-oblivious search to derive a novel auxiliary function $F$, whose stationary points are excellent approximations to the global maximum of the original DR-submodular objective $f$. Specifically, when $f$ is monotone and $\gamma$-weakly DR-submodular, we propose an auxiliary function $F$ whose stationary points can provide a better $(1-e^{-\gamma})$-approximation than the $(\gamma^2/(1+\gamma^2))$-approximation guaranteed by the stationary points of $f$ itself. Similarly, for the non-monotone case, we devise another auxiliary function $F$ whose stationary points can achieve an optimal $\frac{1-\min_{\boldsymbol{x}\in\mathcal{C}}\|\boldsymbol{x}\|_{\infty}}{4}$-approximation guarantee where $\mathcal{C}$ is a convex constraint set. In contrast, the stationary points of the original non-monotone DR-submodular function can be arbitrarily bad~\citep{chen2023continuous}. Furthermore, we demonstrate the scalability of our boosting technique on four problems. In all of these four problems, our resulting variants of boosting PGA algorithm beat the previous standard PGA in several aspects such as approximation ratio and efficiency. Finally, we corroborate our theoretical findings with numerical experiments, which demonstrate the effectiveness of our boosting PGA methods.
Robo360: A 3D Omnispective Multi-Material Robotic Manipulation Dataset
Dec 09, 2023
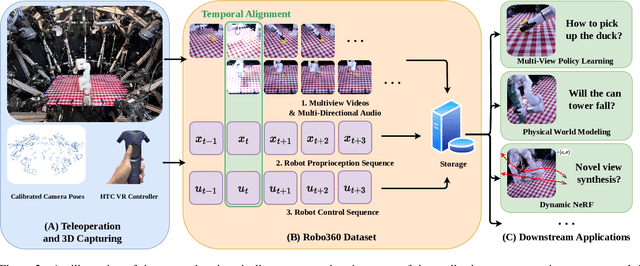
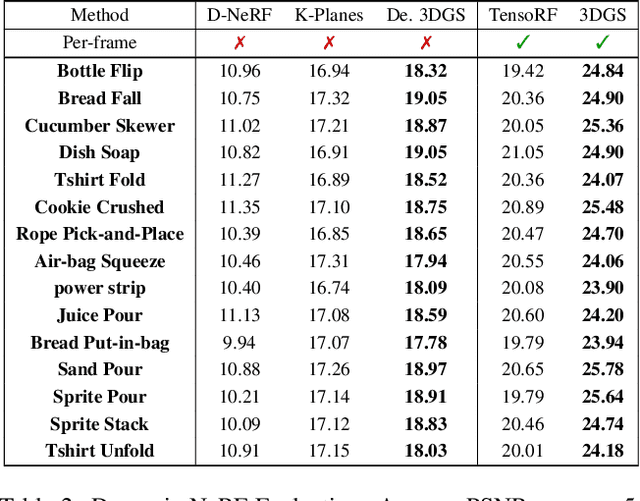

Building robots that can automate labor-intensive tasks has long been the core motivation behind the advancements in computer vision and the robotics community. Recent interest in leveraging 3D algorithms, particularly neural fields, has led to advancements in robot perception and physical understanding in manipulation scenarios. However, the real world's complexity poses significant challenges. To tackle these challenges, we present Robo360, a dataset that features robotic manipulation with a dense view coverage, which enables high-quality 3D neural representation learning, and a diverse set of objects with various physical and optical properties and facilitates research in various object manipulation and physical world modeling tasks. We confirm the effectiveness of our dataset using existing dynamic NeRF and evaluate its potential in learning multi-view policies. We hope that Robo360 can open new research directions yet to be explored at the intersection of understanding the physical world in 3D and robot control.
Towards A Robust Group-level Emotion Recognition via Uncertainty-Aware Learning
Oct 06, 2023



Group-level emotion recognition (GER) is an inseparable part of human behavior analysis, aiming to recognize an overall emotion in a multi-person scene. However, the existing methods are devoted to combing diverse emotion cues while ignoring the inherent uncertainties under unconstrained environments, such as congestion and occlusion occurring within a group. Additionally, since only group-level labels are available, inconsistent emotion predictions among individuals in one group can confuse the network. In this paper, we propose an uncertainty-aware learning (UAL) method to extract more robust representations for GER. By explicitly modeling the uncertainty of each individual, we utilize stochastic embedding drawn from a Gaussian distribution instead of deterministic point embedding. This representation captures the probabilities of different emotions and generates diverse predictions through this stochasticity during the inference stage. Furthermore, uncertainty-sensitive scores are adaptively assigned as the fusion weights of individuals' face within each group. Moreover, we develop an image enhancement module to enhance the model's robustness against severe noise. The overall three-branch model, encompassing face, object, and scene component, is guided by a proportional-weighted fusion strategy and integrates the proposed uncertainty-aware method to produce the final group-level output. Experimental results demonstrate the effectiveness and generalization ability of our method across three widely used databases.
Bandit Multi-linear DR-Submodular Maximization and Its Applications on Adversarial Submodular Bandits
May 21, 2023
We investigate the online bandit learning of the monotone multi-linear DR-submodular functions, designing the algorithm $\mathtt{BanditMLSM}$ that attains $O(T^{2/3}\log T)$ of $(1-1/e)$-regret. Then we reduce submodular bandit with partition matroid constraint and bandit sequential monotone maximization to the online bandit learning of the monotone multi-linear DR-submodular functions, attaining $O(T^{2/3}\log T)$ of $(1-1/e)$-regret in both problems, which improve the existing results. To the best of our knowledge, we are the first to give a sublinear regret algorithm for the submodular bandit with partition matroid constraint. A special case of this problem is studied by Streeter et al.(2009). They prove a $O(T^{4/5})$ $(1-1/e)$-regret upper bound. For the bandit sequential submodular maximization, the existing work proves an $O(T^{2/3})$ regret with a suboptimal $1/2$ approximation ratio (Niazadeh et al. 2021).
Reparameterization through Spatial Gradient Scaling
Mar 07, 2023Reparameterization aims to improve the generalization of deep neural networks by transforming convolutional layers into equivalent multi-branched structures during training. However, there exists a gap in understanding how reparameterization may change and benefit the learning process of neural networks. In this paper, we present a novel spatial gradient scaling method to redistribute learning focus among weights in convolutional networks. We prove that spatial gradient scaling achieves the same learning dynamics as a branched reparameterization yet without introducing structural changes into the network. We further propose an analytical approach that dynamically learns scalings for each convolutional layer based on the spatial characteristics of its input feature map gauged by mutual information. Experiments on CIFAR-10, CIFAR-100, and ImageNet show that without searching for reparameterized structures, our proposed scaling method outperforms the state-of-the-art reparameterization strategies at a lower computational cost.