 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiCLP: Large Language Model Reasoning with Implicit Cognition Latent Planning
Dec 30, 2025Large language models (LLMs), when guided by explicit textual plans, can perform reliable step-by-step reasoning during problem-solving. However, generating accurate and effective textual plans remains challenging due to LLM hallucinations and the high diversity of task-specific questions. To address this, we draw inspiration from human Implicit Cognition (IC), the subconscious process by which decisions are guided by compact, generalized patterns learned from past experiences without requiring explicit verbalization. We propose iCLP, a novel framework that enables LLMs to adaptively generate latent plans (LPs), which are compact encodings of effective reasoning instructions. iCLP first distills explicit plans from existing step-by-step reasoning trajectories. It then learns discrete representations of these plans via a vector-quantized autoencoder coupled with a codebook. Finally, by fine-tuning LLMs on paired latent plans and corresponding reasoning steps, the models learn to perform implicit planning during reasoning. Experimental results on mathematical reasoning and code generation tasks demonstrate that, with iCLP, LLMs can plan in latent space while reasoning in language space. This approach yields significant improvements in both accuracy and efficiency and, crucially, demonstrates strong cross-domain generalization while preserving the interpretability of chain-of-thought reasoning.
Can LLMs Predict Their Own Failures? Self-Awareness via Internal Circuits
Dec 23, 2025Large language models (LLMs) generate fluent and complex outputs but often fail to recognize their own mistakes and hallucinations. Existing approaches typically rely on external judges, multi-sample consistency, or text-based self-critique, which incur additional compute or correlate weakly with true correctness. We ask: can LLMs predict their own failures by inspecting internal states during inference? We introduce Gnosis, a lightweight self-awareness mechanism that enables frozen LLMs to perform intrinsic self-verification by decoding signals from hidden states and attention patterns. Gnosis passively observes internal traces, compresses them into fixed-budget descriptors, and predicts correctness with negligible inference cost, adding only ~5M parameters and operating independently of sequence length. Across math reasoning, open-domain question answering, and academic knowledge benchmarks, and over frozen backbones ranging from 1.7B to 20B parameters, Gnosis consistently outperforms strong internal baselines and large external judges in both accuracy and calibration. Moreover, it generalizes zero-shot to partial generations, enabling early detection of failing trajectories and compute-aware control. These results show that reliable correctness cues are intrinsic to generation process and can be extracted efficiently without external supervision.
PerfCoder: Large Language Models for Interpretable Code Performance Optimization
Dec 16, 2025


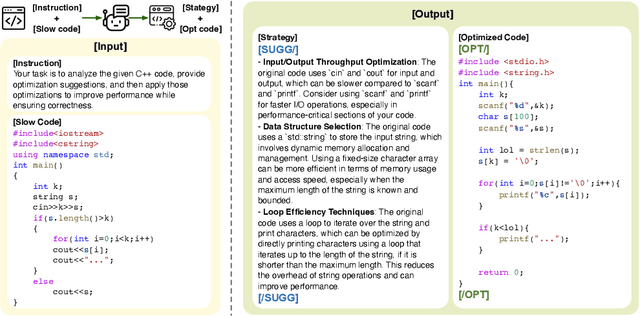
Large language models (LLMs) have achieved remarkable progress in automatic code generation, yet their ability to produce high-performance code remains limited--a critical requirement in real-world software systems. We argue that current LLMs struggle not only due to data scarcity but, more importantly, because they lack supervision that guides interpretable and effective performance improvements. In this work, we introduce PerfCoder, a family of LLMs specifically designed to generate performance-enhanced code from source code via interpretable, customized optimizations. PerfCoder is fine-tuned on a curated collection of real-world optimization trajectories with human-readable annotations, and preference-aligned by reinforcement fine-tuning using runtime measurements, enabling it to propose input-specific improvement strategies and apply them directly without relying on iterative refinement. On the PIE code performance benchmark, PerfCoder surpasses all existing models in both runtime speedup and effective optimization rate, demonstrating that performance optimization cannot be achieved by scale alone but requires optimization stratetgy awareness. In addition, PerfCoder can generate interpretable feedback about the source code, which, when provided as input to a larger LLM in a planner-and-optimizer cooperative workflow, can further improve outcomes. Specifically, we elevate the performance of 32B models and GPT-5 to new levels on code optimization, substantially surpassing their original performance.
rSIM: Incentivizing Reasoning Capabilities of LLMs via Reinforced Strategy Injection
Dec 09, 2025Large language models (LLMs) are post-trained through reinforcement learning (RL) to evolve into Reasoning Language Models (RLMs), where the hallmark of this advanced reasoning is ``aha'' moments when they start to perform strategies, such as self-reflection and deep thinking, within chain of thoughts (CoTs). Motivated by this, this paper proposes a novel reinforced strategy injection mechanism (rSIM), that enables any LLM to become an RLM by employing a small planner to guide the LLM's CoT through the adaptive injection of reasoning strategies. To achieve this, the planner (leader agent) is jointly trained with an LLM (follower agent) using multi-agent RL (MARL), based on a leader-follower framework and straightforward rule-based rewards. Experimental results show that rSIM enables Qwen2.5-0.5B to become an RLM and significantly outperform Qwen2.5-14B. Moreover, the planner is generalizable: it only needs to be trained once and can be applied as a plug-in to substantially improve the reasoning capabilities of existing LLMs. In addition, the planner supports continual learning across various tasks, allowing its planning abilities to gradually improve and generalize to a wider range of problems.
Re-ttention: Ultra Sparse Visual Generation via Attention Statistical Reshape
May 28, 2025Diffusion Transformers (DiT) have become the de-facto model for generating high-quality visual content like videos and images. A huge bottleneck is the attention mechanism where complexity scales quadratically with resolution and video length. One logical way to lessen this burden is sparse attention, where only a subset of tokens or patches are included in the calculation. However, existing techniques fail to preserve visual quality at extremely high sparsity levels and might even incur non-negligible compute overheads. % To address this concern, we propose Re-ttention, which implements very high sparse attention for visual generation models by leveraging the temporal redundancy of Diffusion Models to overcome the probabilistic normalization shift within the attention mechanism. Specifically, Re-ttention reshapes attention scores based on the prior softmax distribution history in order to preserve the visual quality of the full quadratic attention at very high sparsity levels. % Experimental results on T2V/T2I models such as CogVideoX and the PixArt DiTs demonstrate that Re-ttention requires as few as 3.1\% of the tokens during inference, outperforming contemporary methods like FastDiTAttn, Sparse VideoGen and MInference. Further, we measure latency to show that our method can attain over 45\% end-to-end % and over 92\% self-attention latency reduction on an H100 GPU at negligible overhead cost. Code available online here: \href{https://github.com/cccrrrccc/Re-ttention}{https://github.com/cccrrrccc/Re-ttention}
FP4DiT: Towards Effective Floating Point Quantization for Diffusion Transformers
Mar 19, 2025Diffusion Models (DM) have revolutionized the text-to-image visual generation process. However, the large computational cost and model footprint of DMs hinders practical deployment, especially on edge devices. Post-training quantization (PTQ) is a lightweight method to alleviate these burdens without the need for training or fine-tuning. While recent DM PTQ methods achieve W4A8 on integer-based PTQ, two key limitations remain: First, while most existing DM PTQ methods evaluate on classical DMs like Stable Diffusion XL, 1.5 or earlier, which use convolutional U-Nets, newer Diffusion Transformer (DiT) models like the PixArt series, Hunyuan and others adopt fundamentally different transformer backbones to achieve superior image synthesis. Second, integer (INT) quantization is prevailing in DM PTQ but doesn't align well with the network weight and activation distribution, while Floating-Point Quantization (FPQ) is still under-investigated, yet it holds the potential to better align the weight and activation distributions in low-bit settings for DiT. In response, we introduce FP4DiT, a PTQ method that leverages FPQ to achieve W4A6 quantization. Specifically, we extend and generalize the Adaptive Rounding PTQ technique to adequately calibrate weight quantization for FPQ and demonstrate that DiT activations depend on input patch data, necessitating robust online activation quantization techniques. Experimental results demonstrate that FP4DiT outperforms integer-based PTQ at W4A6 and W4A8 precision and generates convincing visual content on PixArt-$\alpha$, PixArt-$\Sigma$ and Hunyuan in terms of several T2I metrics such as HPSv2 and CLIP.
TreeX: Generating Global Graphical GNN Explanations via Critical Subtree Extraction
Mar 12, 2025The growing demand for transparency and interpretability in critical domains has driven increased interests in comprehending the explainability of Message-Passing (MP) Graph Neural Networks (GNNs). Although substantial research efforts have been made to generate explanations for individual graph instances, identifying global explaining concepts for a GNN still poses great challenges, especially when concepts are desired in a graphical form on the dataset level. While most prior works treat GNNs as black boxes, in this paper, we propose to unbox GNNs by analyzing and extracting critical subtrees incurred by the inner workings of message passing, which correspond to critical subgraphs in the datasets. By aggregating subtrees in an embedding space with an efficient algorithm, which does not require complex subgraph matching or search, we can make intuitive graphical explanations for Message-Passing GNNs on local, class and global levels. We empirically show that our proposed approach not only generates clean subgraph concepts on a dataset level in contrast to existing global explaining methods which generate non-graphical rules (e.g., language or embeddings) as explanations, but it is also capable of providing explanations for individual instances with a comparable or even superior performance as compared to leading local-level GNN explainers.
Applying Graph Explanation to Operator Fusion
Dec 31, 2024



Layer fusion techniques are critical to improving the inference efficiency of deep neural networks (DNN) for deployment. Fusion aims to lower inference costs by reducing data transactions between an accelerator's on-chip buffer and DRAM. This is accomplished by grouped execution of multiple operations like convolution and activations together into single execution units - fusion groups. However, on-chip buffer capacity limits fusion group size and optimizing fusion on whole DNNs requires partitioning into multiple fusion groups. Finding the optimal groups is a complex problem where the presence of invalid solutions hampers traditional search algorithms and demands robust approaches. In this paper we incorporate Explainable AI, specifically Graph Explanation Techniques (GET), into layer fusion. Given an invalid fusion group, we identify the operations most responsible for group invalidity, then use this knowledge to recursively split the original fusion group via a greedy tree-based algorithm to minimize DRAM access. We pair our scheme with common algorithms and optimize DNNs on two types of layer fusion: Line-Buffer Depth First (LBDF) and Branch Requirement Reduction (BRR). Experiments demonstrate the efficacy of our scheme on several popular and classical convolutional neural networks like ResNets and MobileNets. Our scheme achieves over 20% DRAM Access reduction on EfficientNet-B3.
Qua$^2$SeDiMo: Quantifiable Quantization Sensitivity of Diffusion Models
Dec 19, 2024
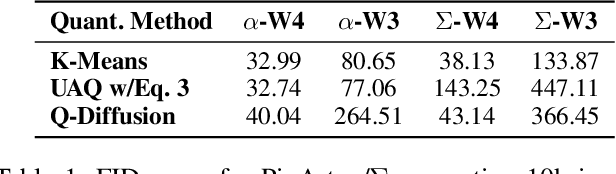

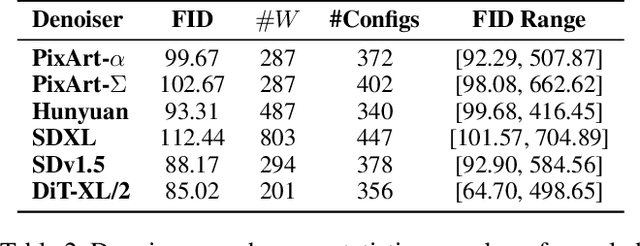
Diffusion Models (DM) have democratized AI image generation through an iterative denoising process. Quantization is a major technique to alleviate the inference cost and reduce the size of DM denoiser networks. However, as denoisers evolve from variants of convolutional U-Nets toward newer Transformer architectures, it is of growing importance to understand the quantization sensitivity of different weight layers, operations and architecture types to performance. In this work, we address this challenge with Qua$^2$SeDiMo, a mixed-precision Post-Training Quantization framework that generates explainable insights on the cost-effectiveness of various model weight quantization methods for different denoiser operation types and block structures. We leverage these insights to make high-quality mixed-precision quantization decisions for a myriad of diffusion models ranging from foundational U-Nets to state-of-the-art Transformers. As a result, Qua$^2$SeDiMo can construct 3.4-bit, 3.9-bit, 3.65-bit and 3.7-bit weight quantization on PixArt-${\alpha}$, PixArt-${\Sigma}$, Hunyuan-DiT and SDXL, respectively. We further pair our weight-quantization configurations with 6-bit activation quantization and outperform existing approaches in terms of quantitative metrics and generative image quality.
PixelMan: Consistent Object Editing with Diffusion Models via Pixel Manipulation and Generation
Dec 18, 2024



Recent research explores the potential of Diffusion Models (DMs) for consistent object editing, which aims to modify object position, size, and composition, etc., while preserving the consistency of objects and background without changing their texture and attributes. Current inference-time methods often rely on DDIM inversion, which inherently compromises efficiency and the achievable consistency of edited images. Recent methods also utilize energy guidance which iteratively updates the predicted noise and can drive the latents away from the original image, resulting in distortions. In this paper, we propose PixelMan, an inversion-free and training-free method for achieving consistent object editing via Pixel Manipulation and generation, where we directly create a duplicate copy of the source object at target location in the pixel space, and introduce an efficient sampling approach to iteratively harmonize the manipulated object into the target location and inpaint its original location, while ensuring image consistency by anchoring the edited image to be generated to the pixel-manipulated image as well as by introducing various consistency-preserving optimization techniques during inference. Experimental evaluations based on benchmark datasets as well as extensive visual comparisons show that in as few as 16 inference steps, PixelMan outperforms a range of state-of-the-art training-based and training-free methods (usually requiring 50 steps) on multiple consistent object editing tasks.