 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Outlier Dynamics in LLM NVFP4 Pretraining
Feb 02, 2026Training large language models using 4-bit arithmetic enhances throughput and memory efficiency. Yet, the limited dynamic range of FP4 increases sensitivity to outliers. While NVFP4 mitigates quantization error via hierarchical microscaling, a persistent loss gap remains compared to BF16. This study conducts a longitudinal analysis of outlier dynamics across architecture during NVFP4 pretraining, focusing on where they localize, why they occur, and how they evolve temporally. We find that, compared with Softmax Attention (SA), Linear Attention (LA) reduces per-tensor heavy tails but still exhibits persistent block-level spikes under block quantization. Our analysis attributes outliers to specific architectural components: Softmax in SA, gating in LA, and SwiGLU in FFN, with "post-QK" operations exhibiting higher sensitivity to quantization. Notably, outliers evolve from transient spikes early in training to a small set of persistent hot channels (i.e., channels with persistently large magnitudes) in later stages. Based on these findings, we introduce Hot-Channel Patch (HCP), an online compensation mechanism that identifies hot channels and reinjects residuals using hardware-efficient kernels. We then develop CHON, an NVFP4 training recipe integrating HCP with post-QK operation protection. On GLA-1.3B model trained for 60B tokens, CHON reduces the loss gap to BF16 from 0.94% to 0.58% while maintaining downstream accuracy.
Remoe: Towards Efficient and Low-Cost MoE Inference in Serverless Computing
Dec 21, 2025Mixture-of-Experts (MoE) has become a dominant architecture in large language models (LLMs) due to its ability to scale model capacity via sparse expert activation. Meanwhile, serverless computing, with its elasticity and pay-per-use billing, is well-suited for deploying MoEs with bursty workloads. However, the large number of experts in MoE models incurs high inference costs due to memory-intensive parameter caching. These costs are difficult to mitigate via simple model partitioning due to input-dependent expert activation. To address these issues, we propose Remoe, a heterogeneous MoE inference system tailored for serverless computing. Remoe assigns non-expert modules to GPUs and expert modules to CPUs, and further offloads infrequently activated experts to separate serverless functions to reduce memory overhead and enable parallel execution. We incorporate three key techniques: (1) a Similar Prompts Searching (SPS) algorithm to predict expert activation patterns based on semantic similarity of inputs; (2) a Main Model Pre-allocation (MMP) algorithm to ensure service-level objectives (SLOs) via worst-case memory estimation; and (3) a joint memory and replica optimization framework leveraging Lagrangian duality and the Longest Processing Time (LPT) algorithm. We implement Remoe on Kubernetes and evaluate it across multiple LLM benchmarks. Experimental results show that Remoe reduces inference cost by up to 57% and cold start latency by 47% compared to state-of-the-art baselines.
rSIM: Incentivizing Reasoning Capabilities of LLMs via Reinforced Strategy Injection
Dec 09, 2025Large language models (LLMs) are post-trained through reinforcement learning (RL) to evolve into Reasoning Language Models (RLMs), where the hallmark of this advanced reasoning is ``aha'' moments when they start to perform strategies, such as self-reflection and deep thinking, within chain of thoughts (CoTs). Motivated by this, this paper proposes a novel reinforced strategy injection mechanism (rSIM), that enables any LLM to become an RLM by employing a small planner to guide the LLM's CoT through the adaptive injection of reasoning strategies. To achieve this, the planner (leader agent) is jointly trained with an LLM (follower agent) using multi-agent RL (MARL), based on a leader-follower framework and straightforward rule-based rewards. Experimental results show that rSIM enables Qwen2.5-0.5B to become an RLM and significantly outperform Qwen2.5-14B. Moreover, the planner is generalizable: it only needs to be trained once and can be applied as a plug-in to substantially improve the reasoning capabilities of existing LLMs. In addition, the planner supports continual learning across various tasks, allowing its planning abilities to gradually improve and generalize to a wider range of problems.
Hear No Evil: Detecting Gradient Leakage by Malicious Servers in Federated Learning
Jun 25, 2025Recent work has shown that gradient updates in federated learning (FL) can unintentionally reveal sensitive information about a client's local data. This risk becomes significantly greater when a malicious server manipulates the global model to provoke information-rich updates from clients. In this paper, we adopt a defender's perspective to provide the first comprehensive analysis of malicious gradient leakage attacks and the model manipulation techniques that enable them. Our investigation reveals a core trade-off: these attacks cannot be both highly effective in reconstructing private data and sufficiently stealthy to evade detection -- especially in realistic FL settings that incorporate common normalization techniques and federated averaging. Building on this insight, we argue that malicious gradient leakage attacks, while theoretically concerning, are inherently limited in practice and often detectable through basic monitoring. As a complementary contribution, we propose a simple, lightweight, and broadly applicable client-side detection mechanism that flags suspicious model updates before local training begins, despite the fact that such detection may not be strictly necessary in realistic FL settings. This mechanism further underscores the feasibility of defending against these attacks with minimal overhead, offering a deployable safeguard for privacy-conscious federated learning systems.
Leaner Training, Lower Leakage: Revisiting Memorization in LLM Fine-Tuning with LoRA
Jun 25, 2025Memorization in large language models (LLMs) makes them vulnerable to data extraction attacks. While pre-training memorization has been extensively studied, fewer works have explored its impact in fine-tuning, particularly for LoRA fine-tuning, a widely adopted parameter-efficient method. In this work, we re-examine memorization in fine-tuning and uncover a surprising divergence from prior findings across different fine-tuning strategies. Factors such as model scale and data duplication, which strongly influence memorization in pre-training and full fine-tuning, do not follow the same trend in LoRA fine-tuning. Using a more relaxed similarity-based memorization metric, we demonstrate that LoRA significantly reduces memorization risks compared to full fine-tuning, while still maintaining strong task performance.
TreeX: Generating Global Graphical GNN Explanations via Critical Subtree Extraction
Mar 12, 2025The growing demand for transparency and interpretability in critical domains has driven increased interests in comprehending the explainability of Message-Passing (MP) Graph Neural Networks (GNNs). Although substantial research efforts have been made to generate explanations for individual graph instances, identifying global explaining concepts for a GNN still poses great challenges, especially when concepts are desired in a graphical form on the dataset level. While most prior works treat GNNs as black boxes, in this paper, we propose to unbox GNNs by analyzing and extracting critical subtrees incurred by the inner workings of message passing, which correspond to critical subgraphs in the datasets. By aggregating subtrees in an embedding space with an efficient algorithm, which does not require complex subgraph matching or search, we can make intuitive graphical explanations for Message-Passing GNNs on local, class and global levels. We empirically show that our proposed approach not only generates clean subgraph concepts on a dataset level in contrast to existing global explaining methods which generate non-graphical rules (e.g., language or embeddings) as explanations, but it is also capable of providing explanations for individual instances with a comparable or even superior performance as compared to leading local-level GNN explainers.
Calibre: Towards Fair and Accurate Personalized Federated Learning with Self-Supervised Learning
Dec 28, 2024



In the context of personalized federated learning, existing approaches train a global model to extract transferable representations, based on which any client could train personalized models with a limited number of data samples. Self-supervised learning is considered a promising direction as the global model it produces is generic and facilitates personalization for all clients fairly. However, when data is heterogeneous across clients, the global model trained using SSL is unable to learn high-quality personalized models. In this paper, we show that when the global model is trained with SSL without modifications, its produced representations have fuzzy class boundaries. As a result, personalized learning within each client produces models with low accuracy. In order to improve SSL towards better accuracy without sacrificing its advantage in fairness, we propose Calibre, a new personalized federated learning framework designed to calibrate SSL representations by maintaining a suitable balance between more generic and more client-specific representations. Calibre is designed based on theoretically-sound properties, and introduces (1) a client-specific prototype loss as an auxiliary training objective; and (2) an aggregation algorithm guided by such prototypes across clients. Our experimental results in an extensive array of non-i.i.d.~settings show that Calibre achieves state-of-the-art performance in terms of both mean accuracy and fairness across clients. Code repo: https://github.com/TL-System/plato/tree/main/examples/ssl/calibre.
Toward Adaptive Reasoning in Large Language Models with Thought Rollback
Dec 27, 2024


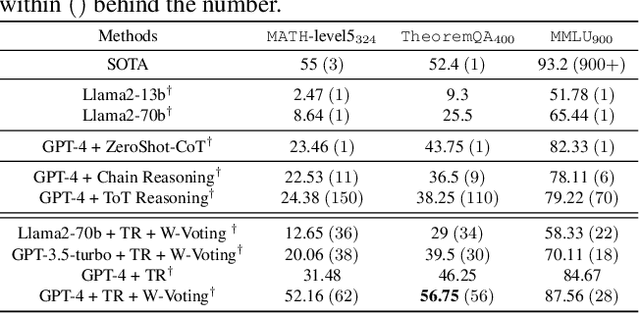
Large language models (LLMs) have been routinely used to solve various tasks using step-by-step reasoning. However, the structure of intermediate reasoning steps, or thoughts, is rigid and unidirectional, such as chains, trees, or acyclic-directed graphs. Consequently, the resulting inflexible and forward-only reasoning may not address challenging tasks and fail when the LLM frequently gives false responses, i.e., ``hallucinations''. This paper proposes a new reasoning framework, called Thought Rollback (TR), allowing LLMs to adaptively build thought structure while maintaining effective reasoning toward problem-solving under ``hallucinations''. The core mechanism of TR is rolling back thoughts, which allows LLMs to perform error analysis on thoughts, and thus roll back to any previously mistaken thought for revision. Subsequently, by including such trial-and-error in the prompt to guide the LLM, each rollback leads to one more reliable reasoning path. Therefore, starting with a simple prompt without human annotations, LLM with TR adaptively and gradually explores thoughts for a correct solution. Comprehensive experiments on mathematical problems and multi-task reasoning demonstrate the state-of-the-art performance of TR in terms of problem-solving rate and interaction cost. For instance, the solving rate of GPT-4 with TR outperforms the current best by $9\%$ on the MATH dataset.
Hufu: A Modality-Agnositc Watermarking System for Pre-Trained Transformers via Permutation Equivariance
Mar 09, 2024



With the blossom of deep learning models and services, it has become an imperative concern to safeguard the valuable model parameters from being stolen. Watermarking is considered an important tool for ownership verification. However, current watermarking schemes are customized for different models and tasks, hard to be integrated as an integrated intellectual protection service. We propose Hufu, a modality-agnostic watermarking system for pre-trained Transformer-based models, relying on the permutation equivariance property of Transformers. Hufu embeds watermark by fine-tuning the pre-trained model on a set of data samples specifically permuted, and the embedded model essentially contains two sets of weights -- one for normal use and the other for watermark extraction which is triggered on permuted inputs. The permutation equivariance ensures minimal interference between these two sets of model weights and thus high fidelity on downstream tasks. Since our method only depends on the model itself, it is naturally modality-agnostic, task-independent, and trigger-sample-free. Extensive experiments on the state-of-the-art vision Transformers, BERT, and GPT2 have demonstrated Hufu's superiority in meeting watermarking requirements including effectiveness, efficiency, fidelity, and robustness, showing its great potential to be deployed as a uniform ownership verification service for various Transformers.
FedReview: A Review Mechanism for Rejecting Poisoned Updates in Federated Learning
Feb 26, 2024



Federated learning has recently emerged as a decentralized approach to learn a high-performance model without access to user data. Despite its effectiveness, federated learning gives malicious users opportunities to manipulate the model by uploading poisoned model updates to the server. In this paper, we propose a review mechanism called FedReview to identify and decline the potential poisoned updates in federated learning. Under our mechanism, the server randomly assigns a subset of clients as reviewers to evaluate the model updates on their training datasets in each round. The reviewers rank the model updates based on the evaluation results and count the number of the updates with relatively low quality as the estimated number of poisoned updates. Based on review reports, the server employs a majority voting mechanism to integrate the rankings and remove the potential poisoned updates in the model aggregation process. Extensive evaluation on multiple datasets demonstrate that FedReview can assist the server to learn a well-performed global model in an adversarial environment.