 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerfCoder: Large Language Models for Interpretable Code Performance Optimization
Dec 16, 2025


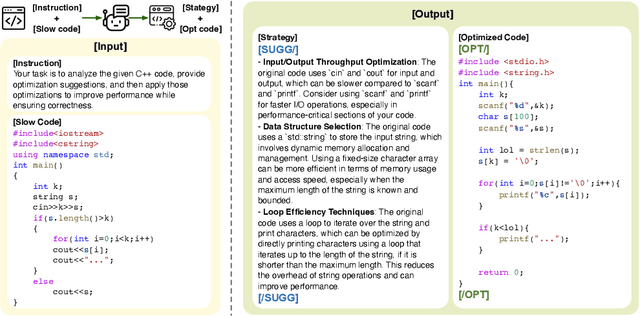
Large language models (LLMs) have achieved remarkable progress in automatic code generation, yet their ability to produce high-performance code remains limited--a critical requirement in real-world software systems. We argue that current LLMs struggle not only due to data scarcity but, more importantly, because they lack supervision that guides interpretable and effective performance improvements. In this work, we introduce PerfCoder, a family of LLMs specifically designed to generate performance-enhanced code from source code via interpretable, customized optimizations. PerfCoder is fine-tuned on a curated collection of real-world optimization trajectories with human-readable annotations, and preference-aligned by reinforcement fine-tuning using runtime measurements, enabling it to propose input-specific improvement strategies and apply them directly without relying on iterative refinement. On the PIE code performance benchmark, PerfCoder surpasses all existing models in both runtime speedup and effective optimization rate, demonstrating that performance optimization cannot be achieved by scale alone but requires optimization stratetgy awareness. In addition, PerfCoder can generate interpretable feedback about the source code, which, when provided as input to a larger LLM in a planner-and-optimizer cooperative workflow, can further improve outcomes. Specifically, we elevate the performance of 32B models and GPT-5 to new levels on code optimization, substantially surpassing their original performance.
TreeX: Generating Global Graphical GNN Explanations via Critical Subtree Extraction
Mar 12, 2025The growing demand for transparency and interpretability in critical domains has driven increased interests in comprehending the explainability of Message-Passing (MP) Graph Neural Networks (GNNs). Although substantial research efforts have been made to generate explanations for individual graph instances, identifying global explaining concepts for a GNN still poses great challenges, especially when concepts are desired in a graphical form on the dataset level. While most prior works treat GNNs as black boxes, in this paper, we propose to unbox GNNs by analyzing and extracting critical subtrees incurred by the inner workings of message passing, which correspond to critical subgraphs in the datasets. By aggregating subtrees in an embedding space with an efficient algorithm, which does not require complex subgraph matching or search, we can make intuitive graphical explanations for Message-Passing GNNs on local, class and global levels. We empirically show that our proposed approach not only generates clean subgraph concepts on a dataset level in contrast to existing global explaining methods which generate non-graphical rules (e.g., language or embeddings) as explanations, but it is also capable of providing explanations for individual instances with a comparable or even superior performance as compared to leading local-level GNN explainers.
Optimizing and Testing Instruction-Following: Analyzing the Impact of Fine-Grained Instruction Variants on instruction-tuned LLMs
Jun 17, 2024The effective alignment of Large Language Models (LLMs) with precise instructions is essential for their application in diverse real-world scenarios. Current methods focus on enhancing the diversity and complexity of training and evaluation samples, yet they fall short in accurately assessing LLMs' ability to follow similar instruction variants. We introduce an effective data augmentation technique that decomposes complex instructions into simpler sub-components, modifies these, and reconstructs them into new variants, thereby preserves the original instruction's context and complexity while introducing variability, which is critical for training and evaluating LLMs' instruction-following precision. We developed the DeMoRecon dataset using this method to both fine-tune and evaluate LLMs. Our findings show that LLMs fine-tuned with DeMoRecon will gain significant performance boost on both ours and commonly used instructions-following benchmarks.
SIFiD: Reassess Summary Factual Inconsistency Detection with LLM
Mar 12, 2024

Ensuring factual consistency between the summary and the original document is paramount in summarization tasks. Consequently, considerable effort has been dedicated to detecting inconsistencies. With the advent of Large Language Models (LLMs), recent studies have begun to leverage their advanced language understanding capabilities for inconsistency detection. However, early attempts have shown that LLMs underperform traditional models due to their limited ability to follow instructions and the absence of an effective detection methodology. In this study, we reassess summary inconsistency detection with LLMs, comparing the performances of GPT-3.5 and GPT-4. To advance research in LLM-based inconsistency detection, we propose SIFiD (Summary Inconsistency Detection with Filtered Document) that identify key sentences within documents by either employing natural language inference or measuring semantic similarity between summaries and documents.
Instruction Fusion: Advancing Prompt Evolution through Hybridization
Dec 27, 2023The fine-tuning of Large Language Models (LLMs) specialized in code generation has seen notable advancements through the use of open-domain coding queries. Despite the successes, existing methodologies like Evol-Instruct encounter performance limitations, impeding further enhancements in code generation tasks. This paper examines the constraints of existing prompt evolution techniques and introduces a novel approach, Instruction Fusion (IF). IF innovatively combines two distinct prompts through a hybridization process, thereby enhancing the evolution of training prompts for code LLMs. Our experimental results reveal that the proposed novel method effectively addresses the shortcomings of prior methods, significantly improving the performance of Code LLMs across five code generation benchmarks, namely HumanEval, HumanEval+, MBPP, MBPP+ and MultiPL-E, which underscore the effectiveness of Instruction Fusion in advancing the capabilities of LLMs in code generation.
iHAS: Instance-wise Hierarchical Architecture Search for Deep Learning Recommendation Models
Sep 14, 2023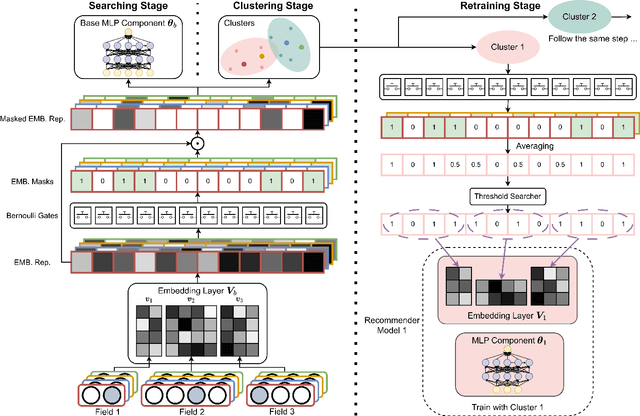
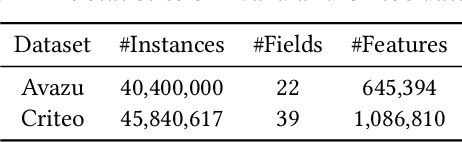
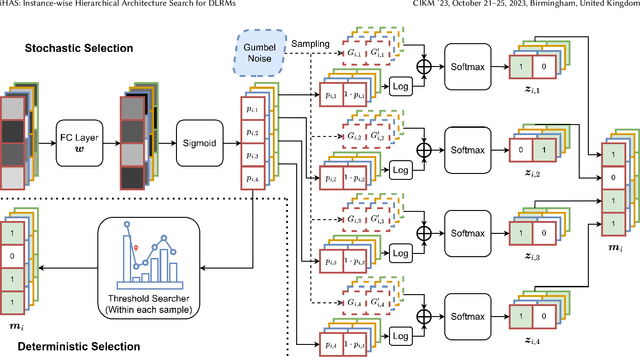
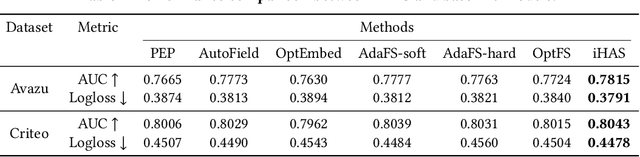
Current recommender systems employ large-sized embedding tables with uniform dimensions for all features, leading to overfitting, high computational cost, and suboptimal generalizing performance. Many techniques aim to solve this issue by feature selection or embedding dimension search. However, these techniques typically select a fixed subset of features or embedding dimensions for all instances and feed all instances into one recommender model without considering heterogeneity between items or users. This paper proposes a novel instance-wise Hierarchical Architecture Search framework, iHAS, which automates neural architecture search at the instance level. Specifically, iHAS incorporates three stages: searching, clustering, and retraining. The searching stage identifies optimal instance-wise embedding dimensions across different field features via carefully designed Bernoulli gates with stochastic selection and regularizers. After obtaining these dimensions, the clustering stage divides samples into distinct groups via a deterministic selection approach of Bernoulli gates. The retraining stage then constructs different recommender models, each one designed with optimal dimensions for the corresponding group. We conduct extensive experiments to evaluate the proposed iHAS on two public benchmark datasets from a real-world recommender system. The experimental results demonstrate the effectiveness of iHAS and its outstanding transferability to widely-used deep recommendation models.
TCR: Short Video Title Generation and Cover Selection with Attention Refinement
Apr 25, 2023With the widespread popularity of user-generated short videos, it becomes increasingly challenging for content creators to promote their content to potential viewers. Automatically generating appealing titles and covers for short videos can help grab viewers' attention. Existing studies on video captioning mostly focus on generating factual descriptions of actions, which do not conform to video titles intended for catching viewer attention. Furthermore, research for cover selection based on multimodal information is sparse. These problems motivate the need for tailored methods to specifically support the joint task of short video title generation and cover selection (TG-CS) as well as the demand for creating corresponding datasets to support the studies. In this paper, we first collect and present a real-world dataset named Short Video Title Generation (SVTG) that contains videos with appealing titles and covers. We then propose a Title generation and Cover selection with attention Refinement (TCR) method for TG-CS. The refinement procedure progressively selects high-quality samples and highly relevant frames and text tokens within each sample to refine model training. Extensive experiments show that our TCR method is superior to various existing video captioning methods in generating titles and is able to select better covers for noisy real-world short videos.
Mulco: Recognizing Chinese Nested Named Entities Through Multiple Scopes
Nov 20, 2022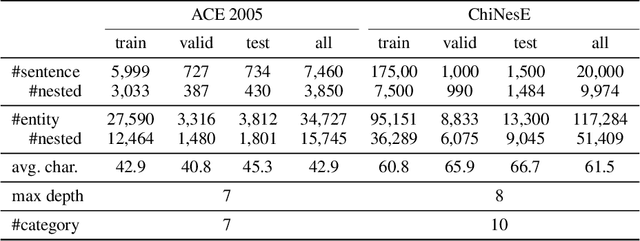
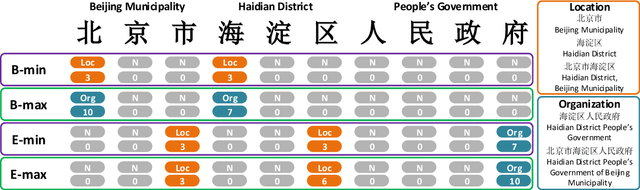
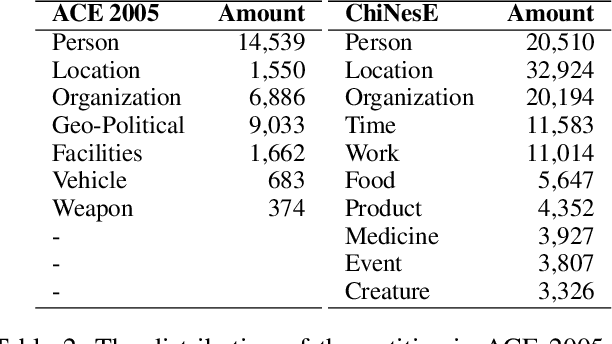
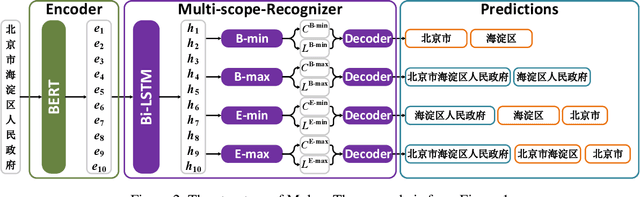
Nested Named Entity Recognition (NNER) has been a long-term challenge to researchers as an important sub-area of Named Entity Recognition. NNER is where one entity may be part of a longer entity, and this may happen on multiple levels, as the term nested suggests. These nested structures make traditional sequence labeling methods unable to properly recognize all entities. While recent researches focus on designing better recognition methods for NNER in a variety of languages, the Chinese NNER (CNNER) still lacks attention, where a free-for-access, CNNER-specialized benchmark is absent. In this paper, we aim to solve CNNER problems by providing a Chinese dataset and a learning-based model to tackle the issue. To facilitate the research on this task, we release ChiNesE, a CNNER dataset with 20,000 sentences sampled from online passages of multiple domains, containing 117,284 entities failing in 10 categories, where 43.8 percent of those entities are nested. Based on ChiNesE, we propose Mulco, a novel method that can recognize named entities in nested structures through multiple scopes. Each scope use a designed scope-based sequence labeling method, which predicts an anchor and the length of a named entity to recognize it. Experiment results show that Mulco has outperformed several baseline methods with the different recognizing schemes on ChiNesE. We also conduct extensive experiments on ACE2005 Chinese corpus, where Mulco has achieved the best performance compared with the baseline methods.
TAG: Toward Accurate Social Media Content Tagging with a Concept Graph
Oct 24, 2021
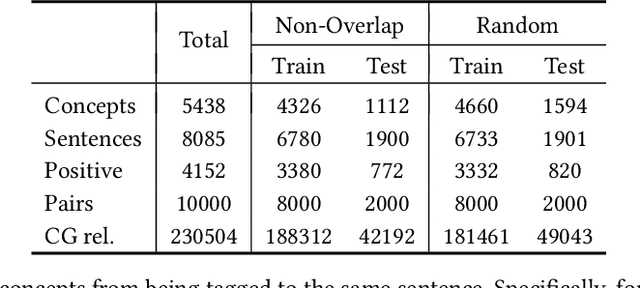

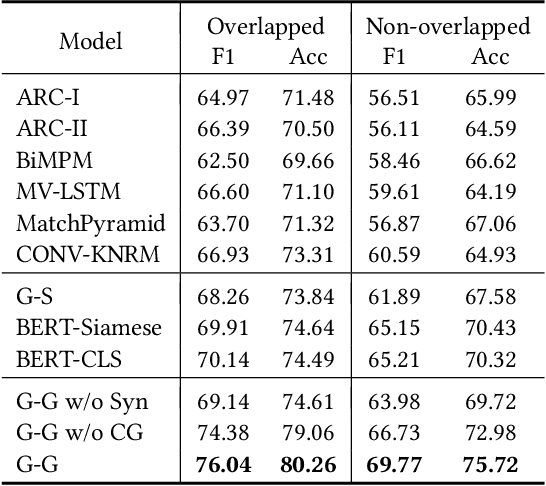
Although conceptualization has been widely studied in semantics and knowledge representation, it is still challenging to find the most accurate concept phrases to characterize the main idea of a text snippet on the fast-growing social media. This is partly attributed to the fact that most knowledge bases contain general terms of the world, such as trees and cars, which do not have the defining power or are not interesting enough to social media app users. Another reason is that the intricacy of natural language allows the use of tense, negation and grammar to change the logic or emphasis of language, thus conveying completely different meanings. In this paper, we present TAG, a high-quality concept matching dataset consisting of 10,000 labeled pairs of fine-grained concepts and web-styled natural language sentences, mined from the open-domain social media. The concepts we consider represent the trending interests of online users. Associated with TAG is a concept graph of these fine-grained concepts and entities to provide the structural context information. We evaluate a wide range of popular neural text matching models as well as pre-trained language models on TAG, and point out their insufficiency to tag social media content with the most appropriate concept. We further propose a novel graph-graph matching method that demonstrates superior abstraction and generalization performance by better utilizing both the structural context in the concept graph and logic interactions between semantic units in the sentence via syntactic dependency parsing. We open-source both the TAG dataset and the proposed methods to facilitate further research.