 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAISE: Requirement-Adaptive Evolutionary Refinement for Training-Free Text-to-Image Alignment
Feb 28, 2026Recent text-to-image (T2I) diffusion models achieve remarkable realism, yet faithful prompt-image alignment remains challenging, particularly for complex prompts with multiple objects, relations, and fine-grained attributes. Existing training-free inference-time scaling methods rely on fixed iteration budgets that cannot adapt to prompt difficulty, while reflection-tuned models require carefully curated reflection datasets and extensive joint fine-tuning of diffusion and vision-language models, often overfitting to reflection paths data and lacking transferability across models. We introduce RAISE (Requirement-Adaptive Self-Improving Evolution), a training-free, requirement-driven evolutionary framework for adaptive T2I generation. RAISE formulates image generation as a requirement-driven adaptive scaling process, evolving a population of candidates at inference time through a diverse set of refinement actions-including prompt rewriting, noise resampling, and instructional editing. Each generation is verified against a structured checklist of requirements, enabling the system to dynamically identify unsatisfied items and allocate further computation only where needed. This achieves adaptive test-time scaling that aligns computational effort with semantic query complexity. On GenEval and DrawBench, RAISE attains state-of-the-art alignment (0.94 overall GenEval) while incurring fewer generated samples (reduced by 30-40%) and VLM calls (reduced by 80%) than prior scaling and reflection-tuned baselines, demonstrating efficient, generalizable, and model-agnostic multi-round self-improvement. Code is available at https://github.com/LiyaoJiang1998/RAISE.
Re-ttention: Ultra Sparse Visual Generation via Attention Statistical Reshape
May 28, 2025Diffusion Transformers (DiT) have become the de-facto model for generating high-quality visual content like videos and images. A huge bottleneck is the attention mechanism where complexity scales quadratically with resolution and video length. One logical way to lessen this burden is sparse attention, where only a subset of tokens or patches are included in the calculation. However, existing techniques fail to preserve visual quality at extremely high sparsity levels and might even incur non-negligible compute overheads. % To address this concern, we propose Re-ttention, which implements very high sparse attention for visual generation models by leveraging the temporal redundancy of Diffusion Models to overcome the probabilistic normalization shift within the attention mechanism. Specifically, Re-ttention reshapes attention scores based on the prior softmax distribution history in order to preserve the visual quality of the full quadratic attention at very high sparsity levels. % Experimental results on T2V/T2I models such as CogVideoX and the PixArt DiTs demonstrate that Re-ttention requires as few as 3.1\% of the tokens during inference, outperforming contemporary methods like FastDiTAttn, Sparse VideoGen and MInference. Further, we measure latency to show that our method can attain over 45\% end-to-end % and over 92\% self-attention latency reduction on an H100 GPU at negligible overhead cost. Code available online here: \href{https://github.com/cccrrrccc/Re-ttention}{https://github.com/cccrrrccc/Re-ttention}
PixelMan: Consistent Object Editing with Diffusion Models via Pixel Manipulation and Generation
Dec 18, 2024



Recent research explores the potential of Diffusion Models (DMs) for consistent object editing, which aims to modify object position, size, and composition, etc., while preserving the consistency of objects and background without changing their texture and attributes. Current inference-time methods often rely on DDIM inversion, which inherently compromises efficiency and the achievable consistency of edited images. Recent methods also utilize energy guidance which iteratively updates the predicted noise and can drive the latents away from the original image, resulting in distortions. In this paper, we propose PixelMan, an inversion-free and training-free method for achieving consistent object editing via Pixel Manipulation and generation, where we directly create a duplicate copy of the source object at target location in the pixel space, and introduce an efficient sampling approach to iteratively harmonize the manipulated object into the target location and inpaint its original location, while ensuring image consistency by anchoring the edited image to be generated to the pixel-manipulated image as well as by introducing various consistency-preserving optimization techniques during inference. Experimental evaluations based on benchmark datasets as well as extensive visual comparisons show that in as few as 16 inference steps, PixelMan outperforms a range of state-of-the-art training-based and training-free methods (usually requiring 50 steps) on multiple consistent object editing tasks.
FRAP: Faithful and Realistic Text-to-Image Generation with Adaptive Prompt Weighting
Aug 21, 2024



Text-to-image (T2I) diffusion models have demonstrated impressive capabilities in generating high-quality images given a text prompt. However, ensuring the prompt-image alignment remains a considerable challenge, i.e., generating images that faithfully align with the prompt's semantics. Recent works attempt to improve the faithfulness by optimizing the latent code, which potentially could cause the latent code to go out-of-distribution and thus produce unrealistic images. In this paper, we propose FRAP, a simple, yet effective approach based on adaptively adjusting the per-token prompt weights to improve prompt-image alignment and authenticity of the generated images. We design an online algorithm to adaptively update each token's weight coefficient, which is achieved by minimizing a unified objective function that encourages object presence and the binding of object-modifier pairs. Through extensive evaluations, we show FRAP generates images with significantly higher prompt-image alignment to prompts from complex datasets, while having a lower average latency compared to recent latent code optimization methods, e.g., 4 seconds faster than D&B on the COCO-Subject dataset. Furthermore, through visual comparisons and evaluation on the CLIP-IQA-Real metric, we show that FRAP not only improves prompt-image alignment but also generates more authentic images with realistic appearances. We also explore combining FRAP with prompt rewriting LLM to recover their degraded prompt-image alignment, where we observe improvements in both prompt-image alignment and image quality.
AdSEE: Investigating the Impact of Image Style Editing on Advertisement Attractiveness
Sep 15, 2023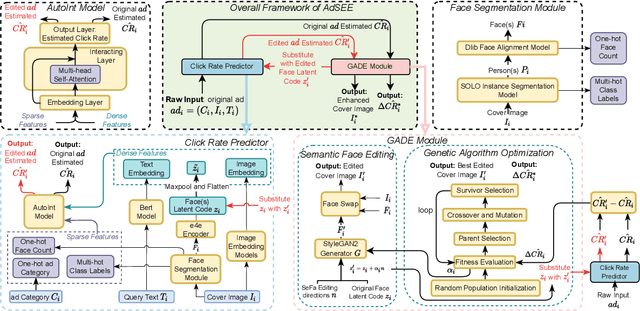


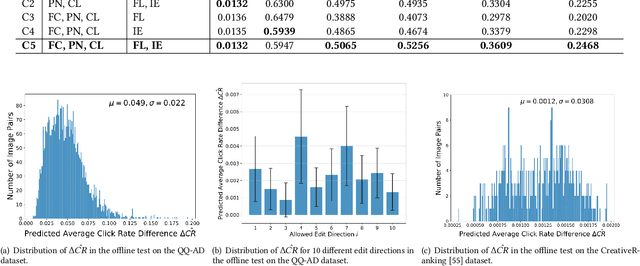
Online advertisements are important elements in e-commerce sites, social media platforms, and search engines. With the increasing popularity of mobile browsing, many online ads are displayed with visual information in the form of a cover image in addition to text descriptions to grab the attention of users. Various recent studies have focused on predicting the click rates of online advertisements aware of visual features or composing optimal advertisement elements to enhance visibility. In this paper, we propose Advertisement Style Editing and Attractiveness Enhancement (AdSEE), which explores whether semantic editing to ads images can affect or alter the popularity of online advertisements. We introduce StyleGAN-based facial semantic editing and inversion to ads images and train a click rate predictor attributing GAN-based face latent representations in addition to traditional visual and textual features to click rates. Through a large collected dataset named QQ-AD, containing 20,527 online ads, we perform extensive offline tests to study how different semantic directions and their edit coefficients may impact click rates. We further design a Genetic Advertisement Editor to efficiently search for the optimal edit directions and intensity given an input ad cover image to enhance its projected click rates. Online A/B tests performed over a period of 5 days have verified the increased click-through rates of AdSEE-edited samples as compared to a control group of original ads, verifying the relation between image styles and ad popularity. We open source the code for AdSEE research at https://github.com/LiyaoJiang1998/adsee.
iHAS: Instance-wise Hierarchical Architecture Search for Deep Learning Recommendation Models
Sep 14, 2023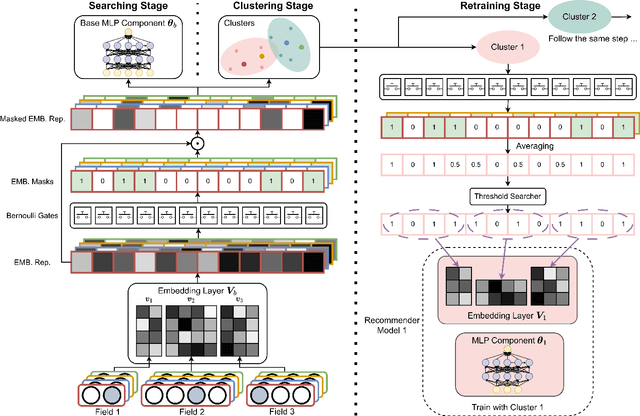
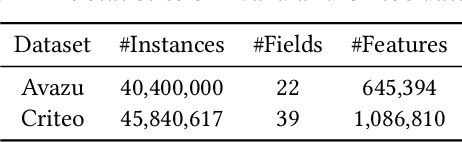
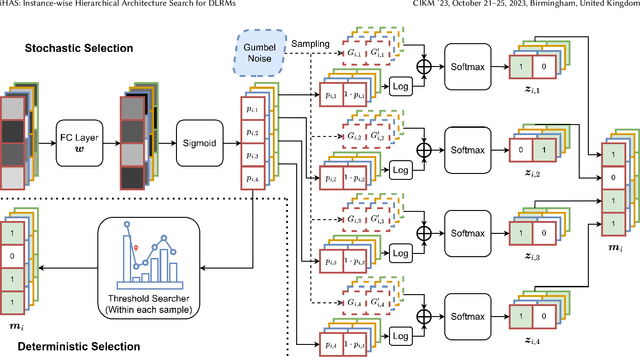
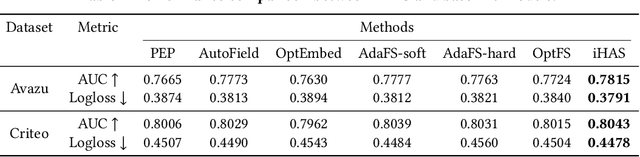
Current recommender systems employ large-sized embedding tables with uniform dimensions for all features, leading to overfitting, high computational cost, and suboptimal generalizing performance. Many techniques aim to solve this issue by feature selection or embedding dimension search. However, these techniques typically select a fixed subset of features or embedding dimensions for all instances and feed all instances into one recommender model without considering heterogeneity between items or users. This paper proposes a novel instance-wise Hierarchical Architecture Search framework, iHAS, which automates neural architecture search at the instance level. Specifically, iHAS incorporates three stages: searching, clustering, and retraining. The searching stage identifies optimal instance-wise embedding dimensions across different field features via carefully designed Bernoulli gates with stochastic selection and regularizers. After obtaining these dimensions, the clustering stage divides samples into distinct groups via a deterministic selection approach of Bernoulli gates. The retraining stage then constructs different recommender models, each one designed with optimal dimensions for the corresponding group. We conduct extensive experiments to evaluate the proposed iHAS on two public benchmark datasets from a real-world recommender system. The experimental results demonstrate the effectiveness of iHAS and its outstanding transferability to widely-used deep recommendation models.