 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdSEE: Investigating the Impact of Image Style Editing on Advertisement Attractiveness
Sep 15, 2023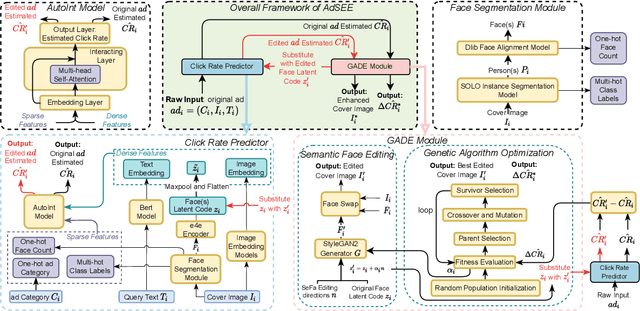


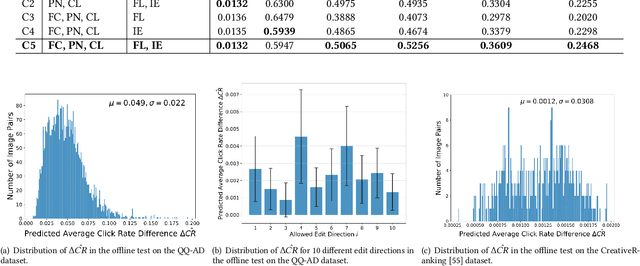
Online advertisements are important elements in e-commerce sites, social media platforms, and search engines. With the increasing popularity of mobile browsing, many online ads are displayed with visual information in the form of a cover image in addition to text descriptions to grab the attention of users. Various recent studies have focused on predicting the click rates of online advertisements aware of visual features or composing optimal advertisement elements to enhance visibility. In this paper, we propose Advertisement Style Editing and Attractiveness Enhancement (AdSEE), which explores whether semantic editing to ads images can affect or alter the popularity of online advertisements. We introduce StyleGAN-based facial semantic editing and inversion to ads images and train a click rate predictor attributing GAN-based face latent representations in addition to traditional visual and textual features to click rates. Through a large collected dataset named QQ-AD, containing 20,527 online ads, we perform extensive offline tests to study how different semantic directions and their edit coefficients may impact click rates. We further design a Genetic Advertisement Editor to efficiently search for the optimal edit directions and intensity given an input ad cover image to enhance its projected click rates. Online A/B tests performed over a period of 5 days have verified the increased click-through rates of AdSEE-edited samples as compared to a control group of original ads, verifying the relation between image styles and ad popularity. We open source the code for AdSEE research at https://github.com/LiyaoJiang1998/adsee.
QBSUM: a Large-Scale Query-Based Document Summarization Dataset from Real-world Applications
Oct 28, 2020
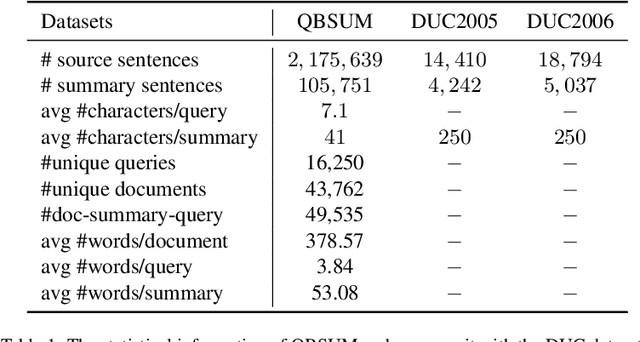
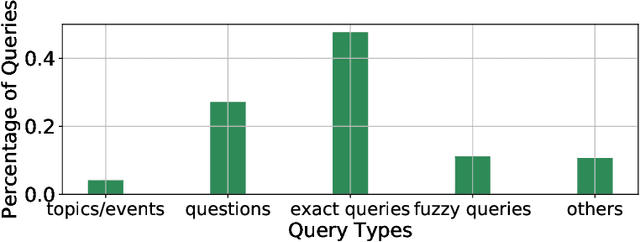

Query-based document summarization aims to extract or generate a summary of a document which directly answers or is relevant to the search query. It is an important technique that can be beneficial to a variety of applications such as search engines, document-level machine reading comprehension, and chatbots. Currently, datasets designed for query-based summarization are short in numbers and existing datasets are also limited in both scale and quality. Moreover, to the best of our knowledge, there is no publicly available dataset for Chinese query-based document summarization. In this paper, we present QBSUM, a high-quality large-scale dataset consisting of 49,000+ data samples for the task of Chinese query-based document summarization. We also propose multiple unsupervised and supervised solutions to the task and demonstrate their high-speed inference and superior performance via both offline experiments and online A/B tests. The QBSUM dataset is released in order to facilitate future advancement of this research field.