 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSAIC: Modality-Specific Adaptation for Incremental Continual Learning in Parkinson's Disease Gait Assessment
Jun 11, 2026Gait-based Parkinson's disease assessment increasingly relies on heterogeneous sensors, but clinical systems rarely collect all modalities simultaneously. New sensors may arrive through device upgrades, protocol changes, or multi-center deployment, while historical patient data are often unavailable because of privacy and storage constraints. This modality-incremental setting faces three challenges: unreliable cross-modal distillation, modality-specific statistical shifts, and reduced plasticity after preservation. We propose MOSAIC, a compact continual learning framework. First, we identify the Toxic Teacher phenomenon and introduce Modality-Specific Warm-Up to stabilize newly learned modality representations before distillation. Second, we propose a statistics-decoupled MSBN architecture that isolates sensor statistics while maintaining a shared semantic backbone. Third, we design a curriculum-guided repulsive objective for Plasticity Recovery, preserving legacy knowledge while recovering modality-specific capacity. Experiments on three multimodal Parkinson's gait datasets show that MOSAIC improves final performance and mitigates forgetting. Project code is available at: https://github.com/minlinzeng/MOSAIC_Modality-Specific-Adaptation-for-Incremental-Continual-Learning-in-PD-Gait-Assessment.git
Rethinking Graph Generalization through the Lens of Sharpness-Aware Minimization
Feb 09, 2026Graph Neural Networks (GNNs) have achieved remarkable success across various graph-based tasks but remain highly sensitive to distribution shifts. In this work, we focus on a prevalent yet under-explored phenomenon in graph generalization, Minimal Shift Flip (MSF),where test samples that slightly deviate from the training distribution are abruptly misclassified. To interpret this phenomenon, we revisit MSF through the lens of Sharpness-Aware Minimization (SAM), which characterizes the local stability and sharpness of the loss landscape while providing a theoretical foundation for modeling generalization error. To quantify loss sharpness, we introduce the concept of Local Robust Radius, measuring the smallest perturbation required to flip a prediction and establishing a theoretical link between local stability and generalization. Building on this perspective, we further observe a continual decrease in the robust radius during training, indicating weakened local stability and an increasingly sharp loss landscape that gives rise to MSF. To jointly solve the MSF phenomenon and the intractability of radius, we develop an energy-based formulation that is theoretically proven to be monotonically correlated with the robust radius, offering a tractable and principled objective for modeling flatness and stability. Building on these insights, we propose an energy-driven generative augmentation framework (E2A) that leverages energy-guided latent perturbations to generate pseudo-OOD samples and enhance model generalization. Extensive experiments across multiple benchmarks demonstrate that E2A consistently improves graph OOD generalization, outperforming state-of-the-art baselines.
An Intelligent and Privacy-Preserving Digital Twin Model for Aging-in-Place
Apr 04, 2025The population of older adults is steadily increasing, with a strong preference for aging-in-place rather than moving to care facilities. Consequently, supporting this growing demographic has become a significant global challenge. However, facilitating successful aging-in-place is challenging, requiring consideration of multiple factors such as data privacy, health status monitoring, and living environments to improve health outcomes. In this paper, we propose an unobtrusive sensor system designed for installation in older adults' homes. Using data from the sensors, our system constructs a digital twin, a virtual representation of events and activities that occurred in the home. The system uses neural network models and decision rules to capture residents' activities and living environments. This digital twin enables continuous health monitoring by providing actionable insights into residents' well-being. Our system is designed to be low-cost and privacy-preserving, with the aim of providing green and safe monitoring for the health of older adults. We have successfully deployed our system in two homes over a time period of two months, and our findings demonstrate the feasibility and effectiveness of digital twin technology in supporting independent living for older adults. This study highlights that our system could revolutionize elder care by enabling personalized interventions, such as lifestyle adjustments, medical treatments, or modifications to the residential environment, to enhance health outcomes.
PAGE: Parametric Generative Explainer for Graph Neural Network
Aug 26, 2024This article introduces PAGE, a parameterized generative interpretive framework. PAGE is capable of providing faithful explanations for any graph neural network without necessitating prior knowledge or internal details. Specifically, we train the auto-encoder to generate explanatory substructures by designing appropriate training strategy. Due to the dimensionality reduction of features in the latent space of the auto-encoder, it becomes easier to extract causal features leading to the model's output, which can be easily employed to generate explanations. To accomplish this, we introduce an additional discriminator to capture the causality between latent causal features and the model's output. By designing appropriate optimization objectives, the well-trained discriminator can be employed to constrain the encoder in generating enhanced causal features. Finally, these features are mapped to substructures of the input graph through the decoder to serve as explanations. Compared to existing methods, PAGE operates at the sample scale rather than nodes or edges, eliminating the need for perturbation or encoding processes as seen in previous methods. Experimental results on both artificially synthesized and real-world datasets demonstrate that our approach not only exhibits the highest faithfulness and accuracy but also significantly outperforms baseline models in terms of efficiency.
Boosting Generalization with Adaptive Style Techniques for Fingerprint Liveness Detection
Oct 24, 2023



We introduce a high-performance fingerprint liveness feature extraction technique that secured first place in LivDet 2023 Fingerprint Representation Challenge. Additionally, we developed a practical fingerprint recognition system with 94.68% accuracy, earning second place in LivDet 2023 Liveness Detection in Action. By investigating various methods, particularly style transfer, we demonstrate improvements in accuracy and generalization when faced with limited training data. As a result, our approach achieved state-of-the-art performance in LivDet 2023 Challenges.
Wasserstein Distortion: Unifying Fidelity and Realism
Oct 05, 2023



We introduce a distortion measure for images, Wasserstein distortion, that simultaneously generalizes pixel-level fidelity on the one hand and realism on the other. We show how Wasserstein distortion reduces mathematically to a pure fidelity constraint or a pure realism constraint under different parameter choices. Pairs of images that are close under Wasserstein distortion illustrate its utility. In particular, we generate random textures that have high fidelity to a reference texture in one location of the image and smoothly transition to an independent realization of the texture as one moves away from this point. Connections between Wasserstein distortion and models of the human visual system are noted.
D-Separation for Causal Self-Explanation
Sep 23, 2023

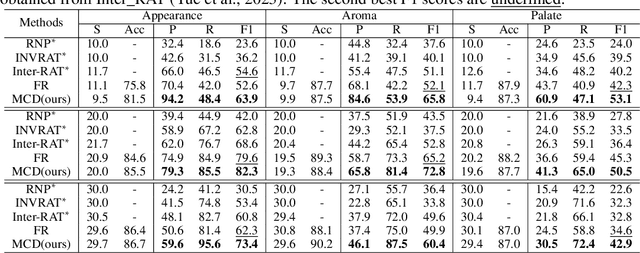

Rationalization is a self-explaining framework for NLP models. Conventional work typically uses the maximum mutual information (MMI) criterion to find the rationale that is most indicative of the target label. However, this criterion can be influenced by spurious features that correlate with the causal rationale or the target label. Instead of attempting to rectify the issues of the MMI criterion, we propose a novel criterion to uncover the causal rationale, termed the Minimum Conditional Dependence (MCD) criterion, which is grounded on our finding that the non-causal features and the target label are \emph{d-separated} by the causal rationale. By minimizing the dependence between the unselected parts of the input and the target label conditioned on the selected rationale candidate, all the causes of the label are compelled to be selected. In this study, we employ a simple and practical measure of dependence, specifically the KL-divergence, to validate our proposed MCD criterion. Empirically, we demonstrate that MCD improves the F1 score by up to $13.7\%$ compared to previous state-of-the-art MMI-based methods. Our code is available at: \url{https://github.com/jugechengzi/Rationalization-MCD}.
AdSEE: Investigating the Impact of Image Style Editing on Advertisement Attractiveness
Sep 15, 2023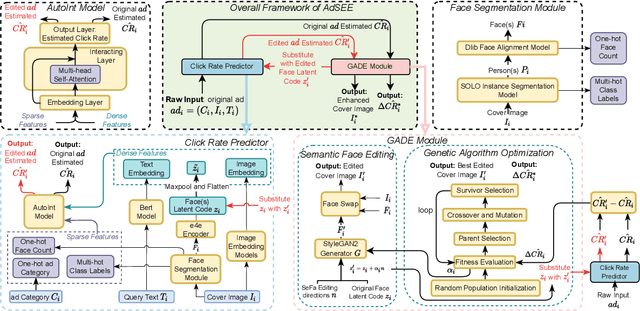


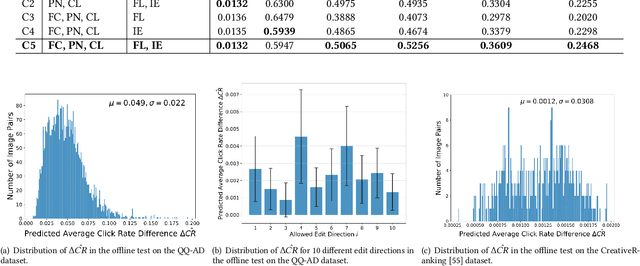
Online advertisements are important elements in e-commerce sites, social media platforms, and search engines. With the increasing popularity of mobile browsing, many online ads are displayed with visual information in the form of a cover image in addition to text descriptions to grab the attention of users. Various recent studies have focused on predicting the click rates of online advertisements aware of visual features or composing optimal advertisement elements to enhance visibility. In this paper, we propose Advertisement Style Editing and Attractiveness Enhancement (AdSEE), which explores whether semantic editing to ads images can affect or alter the popularity of online advertisements. We introduce StyleGAN-based facial semantic editing and inversion to ads images and train a click rate predictor attributing GAN-based face latent representations in addition to traditional visual and textual features to click rates. Through a large collected dataset named QQ-AD, containing 20,527 online ads, we perform extensive offline tests to study how different semantic directions and their edit coefficients may impact click rates. We further design a Genetic Advertisement Editor to efficiently search for the optimal edit directions and intensity given an input ad cover image to enhance its projected click rates. Online A/B tests performed over a period of 5 days have verified the increased click-through rates of AdSEE-edited samples as compared to a control group of original ads, verifying the relation between image styles and ad popularity. We open source the code for AdSEE research at https://github.com/LiyaoJiang1998/adsee.
Decoupled Rationalization with Asymmetric Learning Rates: A Flexible Lipschitz Restraint
May 26, 2023A self-explaining rationalization model is generally constructed by a cooperative game where a generator selects the most human-intelligible pieces from the input text as rationales, followed by a predictor that makes predictions based on the selected rationales. However, such a cooperative game may incur the degeneration problem where the predictor overfits to the uninformative pieces generated by a not yet well-trained generator and in turn, leads the generator to converge to a sub-optimal model that tends to select senseless pieces. In this paper, we theoretically bridge degeneration with the predictor's Lipschitz continuity. Then, we empirically propose a simple but effective method named DR, which can naturally and flexibly restrain the Lipschitz constant of the predictor, to address the problem of degeneration. The main idea of DR is to decouple the generator and predictor to allocate them with asymmetric learning rates. A series of experiments conducted on two widely used benchmarks have verified the effectiveness of the proposed method. Codes: \href{https://github.com/jugechengzi/Rationalization-DR}{https://github.com/jugechengzi/Rationalization-DR}.
MGR: Multi-generator based Rationalization
May 23, 2023



Rationalization is to employ a generator and a predictor to construct a self-explaining NLP model in which the generator selects a subset of human-intelligible pieces of the input text to the following predictor. However, rationalization suffers from two key challenges, i.e., spurious correlation and degeneration, where the predictor overfits the spurious or meaningless pieces solely selected by the not-yet well-trained generator and in turn deteriorates the generator. Although many studies have been proposed to address the two challenges, they are usually designed separately and do not take both of them into account. In this paper, we propose a simple yet effective method named MGR to simultaneously solve the two problems. The key idea of MGR is to employ multiple generators such that the occurrence stability of real pieces is improved and more meaningful pieces are delivered to the predictor. Empirically, we show that MGR improves the F1 score by up to 20.9% as compared to state-of-the-art methods. Codes are available at https://github.com/jugechengzi/Rationalization-MGR .