 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Reinforcement Learning Based Online 3D Bin Packing Spatial Strategy Optimization
Apr 13, 2026The online 3D bin packing problem is important in logistics, warehousing and intelligent manufacturing, with solutions shifting to deep reinforcement learning (DRL) which faces challenges like low sample efficiency. This paper proposes a diffusion reinforcement learning-based algorithm, using a Markov decision chain for packing modeling, height map-based state representation and a diffusion model-based actor network. Experiments show it significantly improves the average number of packed items compared to state-of-the-art DRL methods, with excellent application potential in complex online scenarios.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
TempoGPT: Enhancing Temporal Reasoning via Quantizing Embedding
Jan 13, 2025Multi-modal language model has made advanced progress in vision and audio, but still faces significant challenges in dealing with complex reasoning tasks in the time series domain. The reasons are twofold. First, labels for multi-modal time series data are coarse and devoid of analysis or reasoning processes. Training with these data cannot improve the model's reasoning capabilities. Second, due to the lack of precise tokenization in processing time series, the representation patterns for temporal and textual information are inconsistent, which hampers the effectiveness of multi-modal alignment. To address these challenges, we propose a multi-modal time series data construction approach and a multi-modal time series language model (TLM), TempoGPT. Specially, we construct multi-modal data for complex reasoning tasks by analyzing the variable-system relationships within a white-box system. Additionally, proposed TempoGPT achieves consistent representation between temporal and textual information by quantizing temporal embeddings, where temporal embeddings are quantized into a series of discrete tokens using a predefined codebook; subsequently, a shared embedding layer processes both temporal and textual tokens. Extensive experiments demonstrate that TempoGPT accurately perceives temporal information, logically infers conclusions, and achieves state-of-the-art in the constructed complex time series reasoning tasks. Moreover, we quantitatively demonstrate the effectiveness of quantizing temporal embeddings in enhancing multi-modal alignment and the reasoning capabilities of TLMs. Code and data are available at https://github.com/zhanghaochuan20/TempoGPT.
A Foundational Generative Model for Breast Ultrasound Image Analysis
Jan 12, 2025



Foundational models have emerged as powerful tools for addressing various tasks in clinical settings. However, their potential development to breast ultrasound analysis remains untapped. In this paper, we present BUSGen, the first foundational generative model specifically designed for breast ultrasound image analysis. Pretrained on over 3.5 million breast ultrasound images, BUSGen has acquired extensive knowledge of breast structures, pathological features, and clinical variations. With few-shot adaptation, BUSGen can generate repositories of realistic and informative task-specific data, facilitating the development of models for a wide range of downstream tasks. Extensive experiments highlight BUSGen's exceptional adaptability, significantly exceeding real-data-trained foundational models in breast cancer screening, diagnosis, and prognosis. In breast cancer early diagnosis, our approach outperformed all board-certified radiologists (n=9), achieving an average sensitivity improvement of 16.5% (P-value<0.0001). Additionally, we characterized the scaling effect of using generated data which was as effective as the collected real-world data for training diagnostic models. Moreover, extensive experiments demonstrated that our approach improved the generalization ability of downstream models. Importantly, BUSGen protected patient privacy by enabling fully de-identified data sharing, making progress forward in secure medical data utilization. An online demo of BUSGen is available at https://aibus.bio.
Convolution Type of Metaplectic Cohen's Distribution Time-Frequency Analysis Theory, Method and Technology
Aug 08, 2024The conventional Cohen's distribution can't meet the requirement of additive noises jamming signals high-performance denoising under the condition of low signal-to-noise ratio, it is necessary to integrate the metaplectic transform for non-stationary signal fractional domain time-frequency analysis. In this paper, we blend time-frequency operators and coordinate operator fractionizations to formulate the definition of the metaplectic Wigner distribution, based on which we integrate the generalized metaplectic convolution to address the unified representation issue of the convolution type of metaplectic Cohen's distribution (CMCD), whose special cases and essential properties are also derived. We blend Wiener filter principle and fractional domain filter mechanism of the metaplectic transform to design the least-squares adaptive filter method in the metaplectic Wigner distribution domain, giving birth to the least-squares adaptive filter-based CMCD whose kernel function can be adjusted with the input signal automatically to achieve the minimum mean-square error (MSE) denoising in Wigner distribution domain. We discuss the optimal symplectic matrices selection strategy of the proposed adaptive CMCD through the minimum MSE minimization modeling and solving. Some examples are also carried out to demonstrate that the proposed filtering method outperforms some state-of-the-arts including Wiener filter and fixed kernel functions-based or adaptive Cohen's distribution in noise suppression.
Adaptive Cohen's Class Time-Frequency Distribution
Aug 08, 2024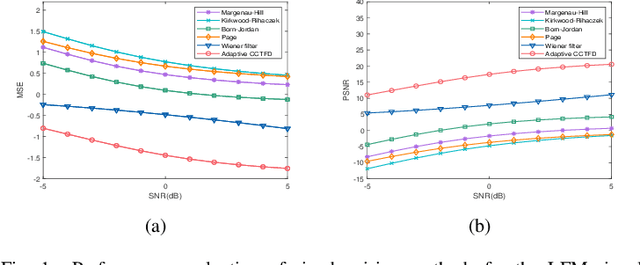
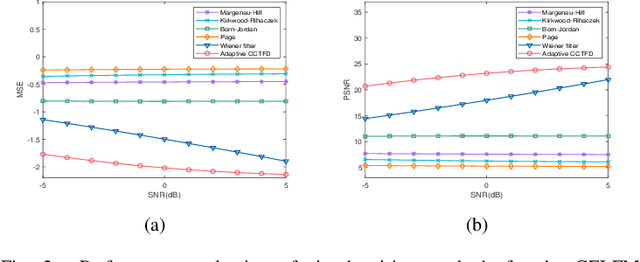
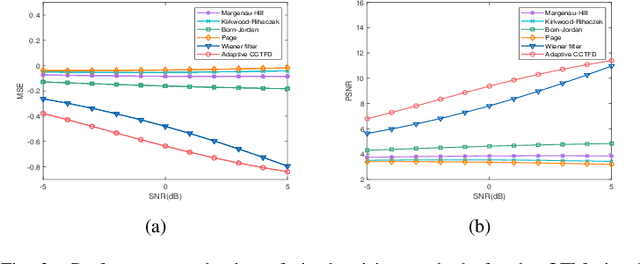
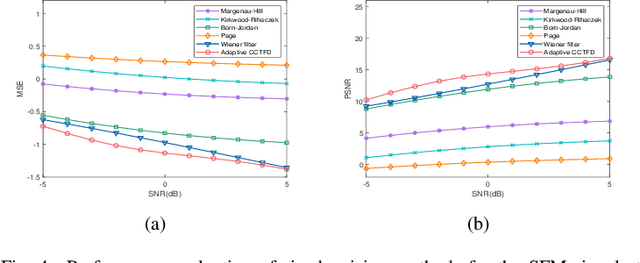
The fixed kernel function-based Cohen's class time-frequency distributions (CCTFDs) allow flexibility in denoising for some specific polluted signals. Due to the limitation of fixed kernel functions, however, from the view point of filtering they fail to automatically adjust the response according to the change of signal to adapt to different signal characteristics. In this letter, we integrate Wiener filter principle and the time-frequency filtering mechanism of CCTFD to design the least-squares adaptive filter method in the Wigner-Ville distribution (WVD) domain, giving birth to the least-squares adaptive filter-based CCTFD whose kernel function can be adjusted with the input signal automatically to achieve the minimum mean-square error denoising in the WVD domain. Some examples are also carried out to demonstrate that the proposed adaptive CCTFD outperforms some state-of-the-arts in noise suppression.
Knowledge-driven AI-generated data for accurate and interpretable breast ultrasound diagnoses
Jul 23, 2024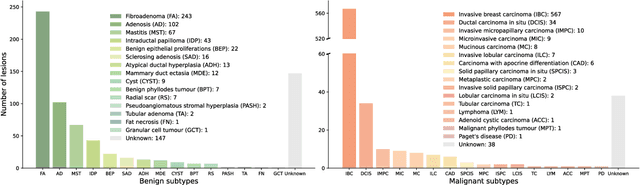
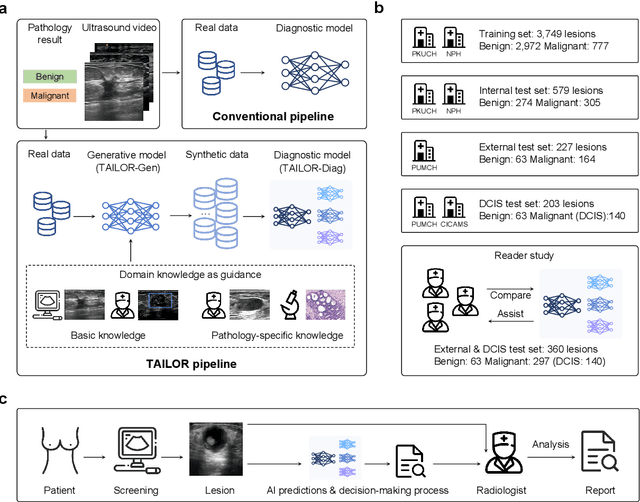
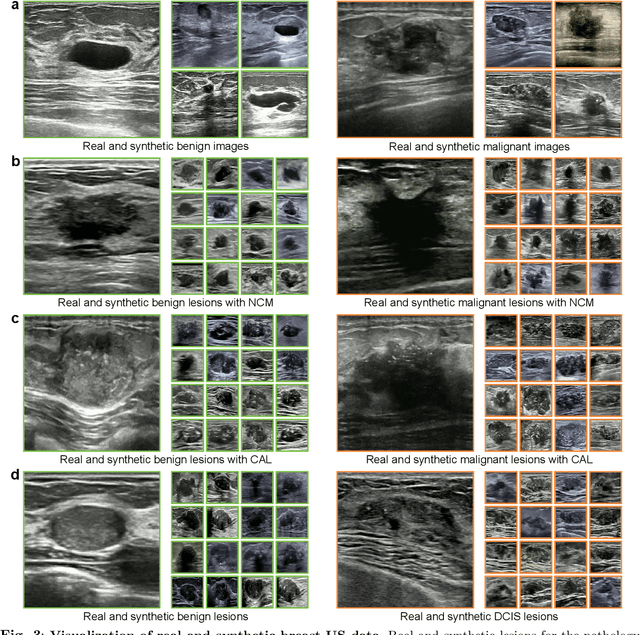
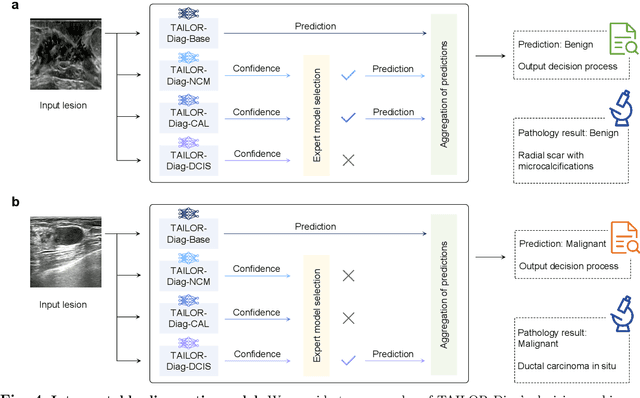
Data-driven deep learning models have shown great capabilities to assist radiologists in breast ultrasound (US) diagnoses. However, their effectiveness is limited by the long-tail distribution of training data, which leads to inaccuracies in rare cases. In this study, we address a long-standing challenge of improving the diagnostic model performance on rare cases using long-tailed data. Specifically, we introduce a pipeline, TAILOR, that builds a knowledge-driven generative model to produce tailored synthetic data. The generative model, using 3,749 lesions as source data, can generate millions of breast-US images, especially for error-prone rare cases. The generated data can be further used to build a diagnostic model for accurate and interpretable diagnoses. In the prospective external evaluation, our diagnostic model outperforms the average performance of nine radiologists by 33.5% in specificity with the same sensitivity, improving their performance by providing predictions with an interpretable decision-making process. Moreover, on ductal carcinoma in situ (DCIS), our diagnostic model outperforms all radiologists by a large margin, with only 34 DCIS lesions in the source data. We believe that TAILOR can potentially be extended to various diseases and imaging modalities.
Decoupling Representation and Knowledge for Few-Shot Intent Classification and Slot Filling
Dec 21, 2023



Few-shot intent classification and slot filling are important but challenging tasks due to the scarcity of finely labeled data. Therefore, current works first train a model on source domains with sufficiently labeled data, and then transfer the model to target domains where only rarely labeled data is available. However, experience transferring as a whole usually suffers from gaps that exist among source domains and target domains. For instance, transferring domain-specific-knowledge-related experience is difficult. To tackle this problem, we propose a new method that explicitly decouples the transferring of general-semantic-representation-related experience and the domain-specific-knowledge-related experience. Specifically, for domain-specific-knowledge-related experience, we design two modules to capture intent-slot relation and slot-slot relation respectively. Extensive experiments on Snips and FewJoint datasets show that our method achieves state-of-the-art performance. The method improves the joint accuracy metric from 27.72% to 42.20% in the 1-shot setting, and from 46.54% to 60.79% in the 5-shot setting.
Decoupled Rationalization with Asymmetric Learning Rates: A Flexible Lipschitz Restraint
May 26, 2023A self-explaining rationalization model is generally constructed by a cooperative game where a generator selects the most human-intelligible pieces from the input text as rationales, followed by a predictor that makes predictions based on the selected rationales. However, such a cooperative game may incur the degeneration problem where the predictor overfits to the uninformative pieces generated by a not yet well-trained generator and in turn, leads the generator to converge to a sub-optimal model that tends to select senseless pieces. In this paper, we theoretically bridge degeneration with the predictor's Lipschitz continuity. Then, we empirically propose a simple but effective method named DR, which can naturally and flexibly restrain the Lipschitz constant of the predictor, to address the problem of degeneration. The main idea of DR is to decouple the generator and predictor to allocate them with asymmetric learning rates. A series of experiments conducted on two widely used benchmarks have verified the effectiveness of the proposed method. Codes: \href{https://github.com/jugechengzi/Rationalization-DR}{https://github.com/jugechengzi/Rationalization-DR}.
Improving Adversarial Robustness with Self-Paced Hard-Class Pair Reweighting
Oct 26, 2022Deep Neural Networks are vulnerable to adversarial attacks. Among many defense strategies, adversarial training with untargeted attacks is one of the most recognized methods. Theoretically, the predicted labels of untargeted attacks should be unpredictable and uniformly-distributed overall false classes. However, we find that the naturally imbalanced inter-class semantic similarity makes those hard-class pairs to become the virtual targets of each other. This study investigates the impact of such closely-coupled classes on adversarial attacks and develops a self-paced reweighting strategy in adversarial training accordingly. Specifically, we propose to upweight hard-class pair loss in model optimization, which prompts learning discriminative features from hard classes. We further incorporate a term to quantify hard-class pair consistency in adversarial training, which greatly boost model robustness. Extensive experiments show that the proposed adversarial training method achieves superior robustness performance over state-of-the-art defenses against a wide range of adversarial attacks.