 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Linear Graph Representation: A Compact Operator Space for Graph Signal Processing and Graph Neural Networks
Jun 12, 2026Graph Signal Processing (GSP) and Graph Neural Networks (GNNs) rely fundamentally on the matrix representation of the underlying graph topology. This representation defines key operators such as the graph Fourier transform, spectral filtering, and convolution. Existing parameterized operator families interpolate only partial subsets of classical graph matrices, while broader formulations become non-compact when representing transition-type operators, limiting both theoretical analysis and stable learning. To address this issue, we propose the Generalized Linear Graph Representation (GLGR), denoted by $\mathbf{Q}_{α,l}$, as a compact two-parameter operator family defined on a bounded linear domain. GLGR unifies major classical operators together with transition-type operators without requiring asymptotic parameters. Theoretically, we show that $\mathbf{Q}_{α,l}$ admits a variational decomposition balancing local smoothness and global degree-weighted energy, derive spectral perturbation bounds, and establish graph-aware sufficient conditions for positive semi-definiteness. Building on this formulation, we develop Adaptive GLGR Convolution (AG-Conv), which makes the propagation operator itself learnable within end-to-end GNNs. Experiments on graph classification and node classification benchmarks show that GLGR improves both fixed-operator representation search and adaptive graph learning across multiple backbones.
Node-Oriented Proactive Spectral Modulation: A Unified Fractional Framework for Graph Signal Denoising
Jun 02, 2026Graph signal denoising is a fundamental task in graph signal processing. While the node-oriented filtering approach enhances spatial adaptability, it suffers from spectral rigidity due to its reliance on the graph Fourier transform. Conversely, emerging fractional-domain transforms provide crucial spectral flexibility but are fundamentally limited by their globally shared filtering paradigm, failing to accommodate localized topological variations. To bridge this gap, this paper proposes a generalized node-oriented fractional filtering (NOFF) framework that seamlessly integrates localized spatial adaptability with proactive spectral modulation across various fractional transforms. However, straightforwardly assigning independent full-rank filters to all vertices incurs a prohibitive parameter space, leading to severe overfitting on random noise. To mitigate this, we introduce the low-rank NOFF (LRNOFF) architecture. By imposing a strict low-rank constraint, LRNOFF inherently acts as a powerful implicit regularizer, preventing noise memorization and ensuring the extraction of robust spectral bases. Furthermore, we develop an efficient computational implementation termed LRNOFF-Fast, which drastically reduces computational and memory overhead while preserving theoretical optimality. Experiments on real-world datasets demonstrate that the proposed framework achieves state-of-the-art performance.
Machine Learning methods for event classification and vertex reconstruction of the 12C + 12C reaction with the MATE-TPC
May 27, 2026In modern nuclear physics experiments, identifying events of interest is challenging for nuclear reaction studies with the active target Time Projection Chamber (TPC). In this work, machine learning techniques are employed to analyze the complex data of the 12C + 12C fusion reaction from a TPC named MATE (multi-purpose active-target time projection chamber for nuclear experiments). Specifically, we successfully applied Residual Neural Network (ResNet-50, ResNet-34 and ResNet-18) and Visual Geometry Group (VGG-19) to classify elastic scattering and fusion reaction events from the 12C + 12C reaction. The classification results of the four models are nearly identical, with accuracies of approximately 97% for the simulated data and 90% for the experimental data. Moreover, these approaches successfully identify some events that are misclassified by traditional methods. These models are also applied to classify events from different fusion reaction channels, with classification accuracies of approximately 95% on simulated data. In addition, a Convolutional Neural Network (CNN) model is developed to reconstruct the reaction vertex, providing an alternative strategy for vertex reconstruction. These results indicate that machine learning techniques can effectively classify reaction events from different channels and reconstruct the reaction vertex, thereby paving the way for future analyses of complex nuclear reaction data.
DPC-VQA: Decoupling Quality Perception and Residual Calibration for Video Quality Assessment
Apr 14, 2026Recent multimodal large language models (MLLMs) have shown promising performance on video quality assessment (VQA) tasks. However, adapting them to new scenarios remains expensive due to large-scale retraining and costly mean opinion score (MOS) annotations. In this paper, we argue that a pretrained MLLM already provides a useful perceptual prior for VQA, and that the main challenge is to efficiently calibrate this prior to the target MOS space. Based on this insight, we propose DPC-VQA, a decoupling perception and calibration framework for video quality assessment. Specifically, DPC-VQA uses a frozen MLLM to provide a base quality estimate and perceptual prior, and employs a lightweight calibration branch to predict a residual correction for target-scenario adaptation. This design avoids costly end-to-end retraining while maintaining reliable performance with lower training and data costs. Extensive experiments on both user-generated content (UGC) and AI-generated content (AIGC) benchmarks show that DPC-VQA achieves competitive performance against representative baselines, while using less than 2% of the trainable parameters of conventional MLLM-based VQA methods and remaining effective with only 20\% of MOS labels. The code will be released upon publication.
A Unified Fractional Spectral Framework for Spatiotemporal Graph Signals: Bi-Fractional Transform and Geodesic Coupling
Mar 02, 2026Graph signal processing extends spectral analysis to data supported on irregular domains. Existing fractional transforms for two-dimensional graph signals, including the two-dimensional graph fractional Fourier transform (GFRFT), typically impose a shared fractional order across dimensions, which limits adaptivity to heterogeneous spatiotemporal spectra. To address this limitation, we propose the two-dimensional graph bi-fractional Fourier transform, which assigns independent fractional orders to the factor graphs of a Cartesian product, enabling decoupled spectral control while preserving separability, unitarity, and invertibility. To further resolve the basis ambiguity in temporal fractional analysis, we develop a geodesic-coupled GFRFT by constructing a coupling path along the principal geodesic on the unitary manifold, thereby unifying graph-induced and discrete temporal bases with guaranteed unitarity and a closed-form inverse. Building on these transforms, we derive a differentiable Wiener-type filtering framework with a hybrid optimization strategy: the fractional orders are learned end-to-end from data, while the coupling parameter is fixed as a structural regularizer. Experiments on real-world time-varying graph datasets and dynamic image restoration tasks demonstrate consistent gains over state-of-the-art fractional transforms and competitive learning-based baselines.
DWAFM: Dynamic Weighted Graph Structure Embedding Integrated with Attention and Frequency-Domain MLPs for Traffic Forecasting
Mar 01, 2026Accurate traffic prediction is a key task for intelligent transportation systems. The core difficulty lies in accurately modeling the complex spatial-temporal dependencies in traffic data. In recent years, improvements in network architecture have failed to bring significant performance enhancements, while embedding technology has shown great potential. However, existing embedding methods often ignore graph structure information or rely solely on static graph structures, making it difficult to effectively capture the dynamic associations between nodes that evolve over time. To address this issue, this letter proposes a novel dynamic weighted graph structure (DWGS) embedding method, which relies on a graph structure that can truly reflect the changes in the strength of dynamic associations between nodes over time. By first combining the DWGS embedding with the spatial-temporal adaptive embedding, as well as the temporal embedding and feature embedding, and then integrating attention and frequency-domain multi-layer perceptrons (MLPs), we design a novel traffic prediction model, termed the DWGS embedding integrated with attention and frequency-domain MLPs (DWAFM). Experiments on five real-world traffic datasets show that the DWAFM achieves better prediction performance than some state-of-the-arts.
FGFRFT: Fast Graph Fractional FourierTransform via Fourier Series Approximation
Feb 24, 2026The graph fractional Fourier transform (GFRFT) generalizes the graph Fourier transform (GFT) but suffers from a significant computational bottleneck: determining the optimal transform order requires expensive eigendecomposition and matrix multiplication, leading to $O(N^3)$ complexity. To address this issue, we propose a fast GFRFT (FGFRFT) algorithm for unitary GFT matrices based on Fourier series approximation and an efficient caching strategy. FGFRFT reduces the complexity of generating transform matrices to $O(2LN^2)$ while preserving differentiability, thereby enabling adaptive order learning. We validate the algorithm through theoretical analysis, approximation accuracy tests, and order learning experiments. Furthermore, we demonstrate its practical efficacy for image and point cloud denoising and present the fractional specformer, which integrates the FGFRFT into the specformer architecture. This integration enables the model to overcome the limitations of a fixed GFT basis and learn optimal fractional orders for complex data. Experimental results confirm that the proposed algorithm significantly accelerates computation and achieves superior performance compared with the GFRFT.
ELIQ: A Label-Free Framework for Quality Assessment of Evolving AI-Generated Images
Feb 03, 2026Generative text-to-image models are advancing at an unprecedented pace, continuously shifting the perceptual quality ceiling and rendering previously collected labels unreliable for newer generations. To address this, we present ELIQ, a Label-free Framework for Quality Assessment of Evolving AI-generated Images. Specifically, ELIQ focuses on visual quality and prompt-image alignment, automatically constructs positive and aspect-specific negative pairs to cover both conventional distortions and AIGC-specific distortion modes, enabling transferable supervision without human annotations. Building on these pairs, ELIQ adapts a pre-trained multimodal model into a quality-aware critic via instruction tuning and predicts two-dimensional quality using lightweight gated fusion and a Quality Query Transformer. Experiments across multiple benchmarks demonstrate that ELIQ consistently outperforms existing label-free methods, generalizes from AI-generated content (AIGC) to user-generated content (UGC) scenarios without modification, and paves the way for scalable and label-free quality assessment under continuously evolving generative models. The code will be released upon publication.
Decoupling Perception and Calibration: Label-Efficient Image Quality Assessment Framework
Jan 28, 2026Recent multimodal large language models (MLLMs) have demonstrated strong capabilities in image quality assessment (IQA) tasks. However, adapting such large-scale models is computationally expensive and still relies on substantial Mean Opinion Score (MOS) annotations. We argue that for MLLM-based IQA, the core bottleneck lies not in the quality perception capacity of MLLMs, but in MOS scale calibration. Therefore, we propose LEAF, a Label-Efficient Image Quality Assessment Framework that distills perceptual quality priors from an MLLM teacher into a lightweight student regressor, enabling MOS calibration with minimal human supervision. Specifically, the teacher conducts dense supervision through point-wise judgments and pair-wise preferences, with an estimate of decision reliability. Guided by these signals, the student learns the teacher's quality perception patterns through joint distillation and is calibrated on a small MOS subset to align with human annotations. Experiments on both user-generated and AI-generated IQA benchmarks demonstrate that our method significantly reduces the need for human annotations while maintaining strong MOS-aligned correlations, making lightweight IQA practical under limited annotation budgets.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
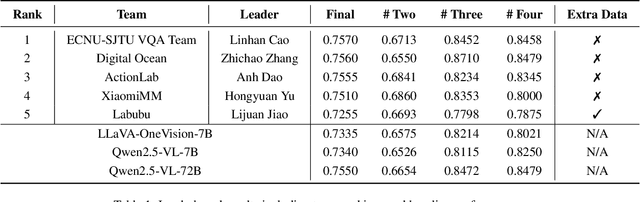
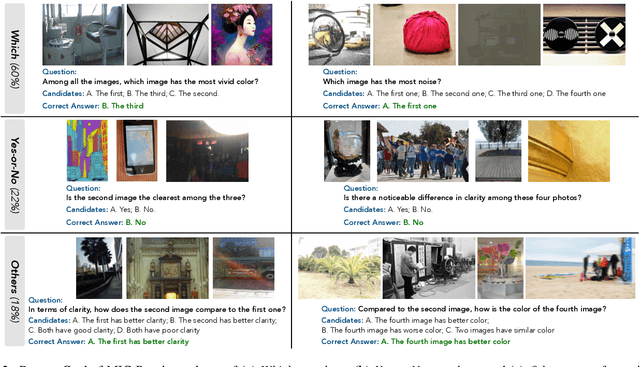
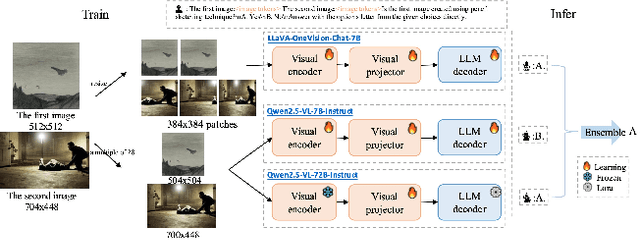
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.