 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELIQ: A Label-Free Framework for Quality Assessment of Evolving AI-Generated Images
Feb 03, 2026Generative text-to-image models are advancing at an unprecedented pace, continuously shifting the perceptual quality ceiling and rendering previously collected labels unreliable for newer generations. To address this, we present ELIQ, a Label-free Framework for Quality Assessment of Evolving AI-generated Images. Specifically, ELIQ focuses on visual quality and prompt-image alignment, automatically constructs positive and aspect-specific negative pairs to cover both conventional distortions and AIGC-specific distortion modes, enabling transferable supervision without human annotations. Building on these pairs, ELIQ adapts a pre-trained multimodal model into a quality-aware critic via instruction tuning and predicts two-dimensional quality using lightweight gated fusion and a Quality Query Transformer. Experiments across multiple benchmarks demonstrate that ELIQ consistently outperforms existing label-free methods, generalizes from AI-generated content (AIGC) to user-generated content (UGC) scenarios without modification, and paves the way for scalable and label-free quality assessment under continuously evolving generative models. The code will be released upon publication.
VideoAesBench: Benchmarking the Video Aesthetics Perception Capabilities of Large Multimodal Models
Jan 29, 2026Large multimodal models (LMMs) have demonstrated outstanding capabilities in various visual perception tasks, which has in turn made the evaluation of LMMs significant. However, the capability of video aesthetic quality assessment, which is a fundamental ability for human, remains underexplored for LMMs. To address this, we introduce VideoAesBench, a comprehensive benchmark for evaluating LMMs' understanding of video aesthetic quality. VideoAesBench has several significant characteristics: (1) Diverse content including 1,804 videos from multiple video sources including user-generated (UGC), AI-generated (AIGC), compressed, robotic-generated (RGC), and game videos. (2) Multiple question formats containing traditional single-choice questions, multi-choice questions, True or False questions, and a novel open-ended questions for video aesthetics description. (3) Holistic video aesthetics dimensions including visual form related questions from 5 aspects, visual style related questions from 4 aspects, and visual affectiveness questions from 3 aspects. Based on VideoAesBench, we benchmark 23 open-source and commercial large multimodal models. Our findings show that current LMMs only contain basic video aesthetics perception ability, their performance remains incomplete and imprecise. We hope our VideoAesBench can be served as a strong testbed and offer insights for explainable video aesthetics assessment.
Q-Bench-Portrait: Benchmarking Multimodal Large Language Models on Portrait Image Quality Perception
Jan 26, 2026Recent advances in multimodal large language models (MLLMs) have demonstrated impressive performance on existing low-level vision benchmarks, which primarily focus on generic images. However, their capabilities to perceive and assess portrait images, a domain characterized by distinct structural and perceptual properties, remain largely underexplored. To this end, we introduce Q-Bench-Portrait, the first holistic benchmark specifically designed for portrait image quality perception, comprising 2,765 image-question-answer triplets and featuring (1) diverse portrait image sources, including natural, synthetic distortion, AI-generated, artistic, and computer graphics images; (2) comprehensive quality dimensions, covering technical distortions, AIGC-specific distortions, and aesthetics; and (3) a range of question formats, including single-choice, multiple-choice, true/false, and open-ended questions, at both global and local levels. Based on Q-Bench-Portrait, we evaluate 20 open-source and 5 closed-source MLLMs, revealing that although current models demonstrate some competence in portrait image perception, their performance remains limited and imprecise, with a clear gap relative to human judgments. We hope that the proposed benchmark will foster further research into enhancing the portrait image perception capabilities of both general-purpose and domain-specific MLLMs.
VTONQA: A Multi-Dimensional Quality Assessment Dataset for Virtual Try-on
Jan 06, 2026With the rapid development of e-commerce and digital fashion, image-based virtual try-on (VTON) has attracted increasing attention. However, existing VTON models often suffer from artifacts such as garment distortion and body inconsistency, highlighting the need for reliable quality evaluation of VTON-generated images. To this end, we construct VTONQA, the first multi-dimensional quality assessment dataset specifically designed for VTON, which contains 8,132 images generated by 11 representative VTON models, along with 24,396 mean opinion scores (MOSs) across three evaluation dimensions (i.e., clothing fit, body compatibility, and overall quality). Based on VTONQA, we benchmark both VTON models and a diverse set of image quality assessment (IQA) metrics, revealing the limitations of existing methods and highlighting the value of the proposed dataset. We believe that the VTONQA dataset and corresponding benchmarks will provide a solid foundation for perceptually aligned evaluation, benefiting both the development of quality assessment methods and the advancement of VTON models.
LMME3DHF: Benchmarking and Evaluating Multimodal 3D Human Face Generation with LMMs
May 05, 2025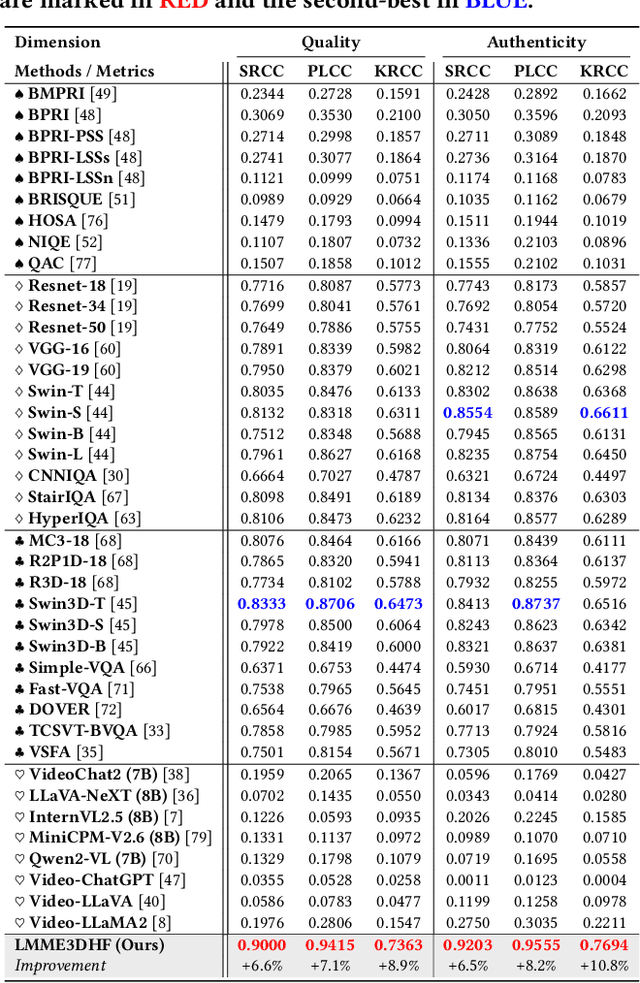
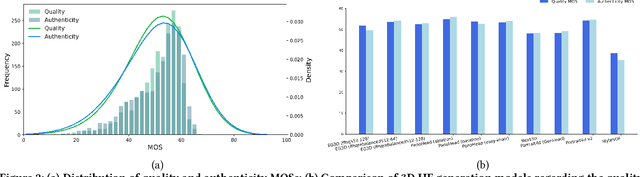

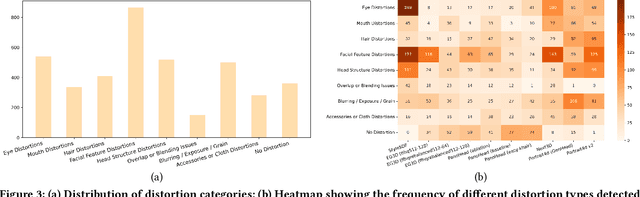
The rapid advancement in generative artificial intelligence have enabled the creation of 3D human faces (HFs) for applications including media production, virtual reality, security, healthcare, and game development, etc. However, assessing the quality and realism of these AI-generated 3D human faces remains a significant challenge due to the subjective nature of human perception and innate perceptual sensitivity to facial features. To this end, we conduct a comprehensive study on the quality assessment of AI-generated 3D human faces. We first introduce Gen3DHF, a large-scale benchmark comprising 2,000 videos of AI-Generated 3D Human Faces along with 4,000 Mean Opinion Scores (MOS) collected across two dimensions, i.e., quality and authenticity, 2,000 distortion-aware saliency maps and distortion descriptions. Based on Gen3DHF, we propose LMME3DHF, a Large Multimodal Model (LMM)-based metric for Evaluating 3DHF capable of quality and authenticity score prediction, distortion-aware visual question answering, and distortion-aware saliency prediction. Experimental results show that LMME3DHF achieves state-of-the-art performance, surpassing existing methods in both accurately predicting quality scores for AI-generated 3D human faces and effectively identifying distortion-aware salient regions and distortion types, while maintaining strong alignment with human perceptual judgments. Both the Gen3DHF database and the LMME3DHF will be released upon the publication.
AGHI-QA: A Subjective-Aligned Dataset and Metric for AI-Generated Human Images
Apr 30, 2025



The rapid development of text-to-image (T2I) generation approaches has attracted extensive interest in evaluating the quality of generated images, leading to the development of various quality assessment methods for general-purpose T2I outputs. However, existing image quality assessment (IQA) methods are limited to providing global quality scores, failing to deliver fine-grained perceptual evaluations for structurally complex subjects like humans, which is a critical challenge considering the frequent anatomical and textural distortions in AI-generated human images (AGHIs). To address this gap, we introduce AGHI-QA, the first large-scale benchmark specifically designed for quality assessment of AGHIs. The dataset comprises 4,000 images generated from 400 carefully crafted text prompts using 10 state of-the-art T2I models. We conduct a systematic subjective study to collect multidimensional annotations, including perceptual quality scores, text-image correspondence scores, visible and distorted body part labels. Based on AGHI-QA, we evaluate the strengths and weaknesses of current T2I methods in generating human images from multiple dimensions. Furthermore, we propose AGHI-Assessor, a novel quality metric that integrates the large multimodal model (LMM) with domain-specific human features for precise quality prediction and identification of visible and distorted body parts in AGHIs. Extensive experimental results demonstrate that AGHI-Assessor showcases state-of-the-art performance, significantly outperforming existing IQA methods in multidimensional quality assessment and surpassing leading LMMs in detecting structural distortions in AGHIs.
LMM4Gen3DHF: Benchmarking and Evaluating Multimodal 3D Human Face Generation with LMMs
Apr 29, 2025The rapid advancement in generative artificial intelligence have enabled the creation of 3D human faces (HFs) for applications including media production, virtual reality, security, healthcare, and game development, etc. However, assessing the quality and realism of these AI-generated 3D human faces remains a significant challenge due to the subjective nature of human perception and innate perceptual sensitivity to facial features. To this end, we conduct a comprehensive study on the quality assessment of AI-generated 3D human faces. We first introduce Gen3DHF, a large-scale benchmark comprising 2,000 videos of AI-Generated 3D Human Faces along with 4,000 Mean Opinion Scores (MOS) collected across two dimensions, i.e., quality and authenticity, 2,000 distortion-aware saliency maps and distortion descriptions. Based on Gen3DHF, we propose LMME3DHF, a Large Multimodal Model (LMM)-based metric for Evaluating 3DHF capable of quality and authenticity score prediction, distortion-aware visual question answering, and distortion-aware saliency prediction. Experimental results show that LMME3DHF achieves state-of-the-art performance, surpassing existing methods in both accurately predicting quality scores for AI-generated 3D human faces and effectively identifying distortion-aware salient regions and distortion types, while maintaining strong alignment with human perceptual judgments. Both the Gen3DHF database and the LMME3DHF will be released upon the publication.
FVQ: A Large-Scale Dataset and A LMM-based Method for Face Video Quality Assessment
Apr 12, 2025



Face video quality assessment (FVQA) deserves to be explored in addition to general video quality assessment (VQA), as face videos are the primary content on social media platforms and human visual system (HVS) is particularly sensitive to human faces. However, FVQA is rarely explored due to the lack of large-scale FVQA datasets. To fill this gap, we present the first large-scale in-the-wild FVQA dataset, FVQ-20K, which contains 20,000 in-the-wild face videos together with corresponding mean opinion score (MOS) annotations. Along with the FVQ-20K dataset, we further propose a specialized FVQA method named FVQ-Rater to achieve human-like rating and scoring for face video, which is the first attempt to explore the potential of large multimodal models (LMMs) for the FVQA task. Concretely, we elaborately extract multi-dimensional features including spatial features, temporal features, and face-specific features (i.e., portrait features and face embeddings) to provide comprehensive visual information, and take advantage of the LoRA-based instruction tuning technique to achieve quality-specific fine-tuning, which shows superior performance on both FVQ-20K and CFVQA datasets. Extensive experiments and comprehensive analysis demonstrate the significant potential of the FVQ-20K dataset and FVQ-Rater method in promoting the development of FVQA.
Disentangled Clothed Avatar Generation with Layered Representation
Jan 08, 2025



Clothed avatar generation has wide applications in virtual and augmented reality, filmmaking, and more. Previous methods have achieved success in generating diverse digital avatars, however, generating avatars with disentangled components (\eg, body, hair, and clothes) has long been a challenge. In this paper, we propose LayerAvatar, the first feed-forward diffusion-based method for generating component-disentangled clothed avatars. To achieve this, we first propose a layered UV feature plane representation, where components are distributed in different layers of the Gaussian-based UV feature plane with corresponding semantic labels. This representation supports high-resolution and real-time rendering, as well as expressive animation including controllable gestures and facial expressions. Based on the well-designed representation, we train a single-stage diffusion model and introduce constrain terms to address the severe occlusion problem of the innermost human body layer. Extensive experiments demonstrate the impressive performances of our method in generating disentangled clothed avatars, and we further explore its applications in component transfer. The project page is available at: https://olivia23333.github.io/LayerAvatar/
MMHead: Towards Fine-grained Multi-modal 3D Facial Animation
Oct 10, 2024



3D facial animation has attracted considerable attention due to its extensive applications in the multimedia field. Audio-driven 3D facial animation has been widely explored with promising results. However, multi-modal 3D facial animation, especially text-guided 3D facial animation is rarely explored due to the lack of multi-modal 3D facial animation dataset. To fill this gap, we first construct a large-scale multi-modal 3D facial animation dataset, MMHead, which consists of 49 hours of 3D facial motion sequences, speech audios, and rich hierarchical text annotations. Each text annotation contains abstract action and emotion descriptions, fine-grained facial and head movements (i.e., expression and head pose) descriptions, and three possible scenarios that may cause such emotion. Concretely, we integrate five public 2D portrait video datasets, and propose an automatic pipeline to 1) reconstruct 3D facial motion sequences from monocular videos; and 2) obtain hierarchical text annotations with the help of AU detection and ChatGPT. Based on the MMHead dataset, we establish benchmarks for two new tasks: text-induced 3D talking head animation and text-to-3D facial motion generation. Moreover, a simple but efficient VQ-VAE-based method named MM2Face is proposed to unify the multi-modal information and generate diverse and plausible 3D facial motions, which achieves competitive results on both benchmarks. Extensive experiments and comprehensive analysis demonstrate the significant potential of our dataset and benchmarks in promoting the development of multi-modal 3D facial animation.