 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilizing Diffusion Posterior Sampling by Noise--Frequency Continuation
Jan 30, 2026Diffusion posterior sampling solves inverse problems by combining a pretrained diffusion prior with measurement-consistency guidance, but it often fails to recover fine details because measurement terms are applied in a manner that is weakly coupled to the diffusion noise level. At high noise, data-consistency gradients computed from inaccurate estimates can be geometrically incongruent with the posterior geometry, inducing early-step drift, spurious high-frequency artifacts, plus sensitivity to schedules and ill-conditioned operators. To address these concerns, we propose a noise--frequency Continuation framework that constructs a continuous family of intermediate posteriors whose likelihood enforces measurement consistency only within a noise-dependent frequency band. This principle is instantiated with a stabilized posterior sampler that combines a diffusion predictor, band-limited likelihood guidance, and a multi-resolution consistency strategy that aggressively commits reliable coarse corrections while conservatively adopting high-frequency details only when they become identifiable. Across super-resolution, inpainting, and deblurring, our method achieves state-of-the-art performance and improves motion deblurring PSNR by up to 5 dB over strong baselines.
Disentangled Clothed Avatar Generation with Layered Representation
Jan 08, 2025



Clothed avatar generation has wide applications in virtual and augmented reality, filmmaking, and more. Previous methods have achieved success in generating diverse digital avatars, however, generating avatars with disentangled components (\eg, body, hair, and clothes) has long been a challenge. In this paper, we propose LayerAvatar, the first feed-forward diffusion-based method for generating component-disentangled clothed avatars. To achieve this, we first propose a layered UV feature plane representation, where components are distributed in different layers of the Gaussian-based UV feature plane with corresponding semantic labels. This representation supports high-resolution and real-time rendering, as well as expressive animation including controllable gestures and facial expressions. Based on the well-designed representation, we train a single-stage diffusion model and introduce constrain terms to address the severe occlusion problem of the innermost human body layer. Extensive experiments demonstrate the impressive performances of our method in generating disentangled clothed avatars, and we further explore its applications in component transfer. The project page is available at: https://olivia23333.github.io/LayerAvatar/
$E^{3}$Gen: Efficient, Expressive and Editable Avatars Generation
May 29, 2024



This paper aims to introduce 3D Gaussian for efficient, expressive, and editable digital avatar generation. This task faces two major challenges: (1) The unstructured nature of 3D Gaussian makes it incompatible with current generation pipelines; (2) the expressive animation of 3D Gaussian in a generative setting that involves training with multiple subjects remains unexplored. In this paper, we propose a novel avatar generation method named $E^3$Gen, to effectively address these challenges. First, we propose a novel generative UV features plane representation that encodes unstructured 3D Gaussian onto a structured 2D UV space defined by the SMPL-X parametric model. This novel representation not only preserves the representation ability of the original 3D Gaussian but also introduces a shared structure among subjects to enable generative learning of the diffusion model. To tackle the second challenge, we propose a part-aware deformation module to achieve robust and accurate full-body expressive pose control. Extensive experiments demonstrate that our method achieves superior performance in avatar generation and enables expressive full-body pose control and editing.
SingingHead: A Large-scale 4D Dataset for Singing Head Animation
Dec 08, 2023



Singing, as a common facial movement second only to talking, can be regarded as a universal language across ethnicities and cultures, plays an important role in emotional communication, art, and entertainment. However, it is often overlooked in the field of audio-driven facial animation due to the lack of singing head datasets and the domain gap between singing and talking in rhythm and amplitude. To this end, we collect a high-quality large-scale singing head dataset, SingingHead, which consists of more than 27 hours of synchronized singing video, 3D facial motion, singing audio, and background music from 76 individuals and 8 types of music. Along with the SingingHead dataset, we argue that 3D and 2D facial animation tasks can be solved together, and propose a unified singing facial animation framework named UniSinger to achieve both singing audio-driven 3D singing head animation and 2D singing portrait video synthesis. Extensive comparative experiments with both SOTA 3D facial animation and 2D portrait animation methods demonstrate the necessity of singing-specific datasets in singing head animation tasks and the promising performance of our unified facial animation framework.
YOLOP: You Only Look Once for Panoptic Driving Perception
Aug 31, 2021
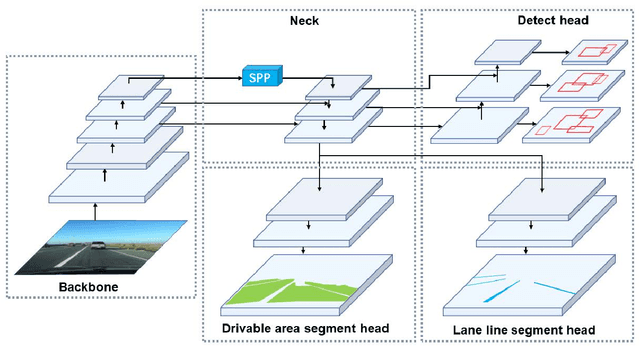


A panoptic driving perception system is an essential part of autonomous driving. A high-precision and real-time perception system can assist the vehicle in making the reasonable decision while driving. We present a panoptic driving perception network (YOLOP) to perform traffic object detection, drivable area segmentation and lane detection simultaneously. It is composed of one encoder for feature extraction and three decoders to handle the specific tasks. Our model performs extremely well on the challenging BDD100K dataset, achieving state-of-the-art on all three tasks in terms of accuracy and speed. Besides, we verify the effectiveness of our multi-task learning model for joint training via ablative studies. To our best knowledge, this is the first work that can process these three visual perception tasks simultaneously in real-time on an embedded device Jetson TX2(23 FPS) and maintain excellent accuracy. To facilitate further research, the source codes and pre-trained models will be released at https://github.com/hustvl/YOLOP.