 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline3R: Online Learning for Consistent Sequential Reconstruction Based on Geometry Foundation Model
Apr 10, 2026We present Online3R, a new sequential reconstruction framework that is capable of adapting to new scenes through online learning, effectively resolving inconsistency issues. Specifically, we introduce a set of learnable lightweight visual prompts into a pretrained, frozen geometry foundation model to capture the knowledge of new environments while preserving the fundamental capability of the foundation model for geometry prediction. To solve the problems of missing groundtruth and the requirement of high efficiency when updating these visual prompts at test time, we introduce a local-global self-supervised learning strategy by enforcing the local and global consistency constraints on predictions. The local consistency constraints are conducted on intermediate and previously local fused results, enabling the model to be trained with high-quality pseudo groundtruth signals; the global consistency constraints are operated on sparse keyframes spanning long distances rather than per frame, allowing the model to learn from a consistent prediction over a long trajectory in an efficient way. Our experiments demonstrate that Online3R outperforms previous state-of-the-art methods on various benchmarks. Project page: https://shunkaizhou.github.io/online3r-1.0/
MV-SAM3D: Adaptive Multi-View Fusion for Layout-Aware 3D Generation
Mar 12, 2026Recent unified 3D generation models have made remarkable progress in producing high-quality 3D assets from a single image. Notably, layout-aware approaches such as SAM3D can reconstruct multiple objects while preserving their spatial arrangement, opening the door to practical scene-level 3D generation. However, current methods are limited to single-view input and cannot leverage complementary multi-view observations, while independently estimated object poses often lead to physically implausible layouts such as interpenetration and floating artifacts. We present MV-SAM3D, a training-free framework that extends layout-aware 3D generation with multi-view consistency and physical plausibility. We formulate multi-view fusion as a Multi-Diffusion process in 3D latent space and propose two adaptive weighting strategies -- attention-entropy weighting and visibility weighting -- that enable confidence-aware fusion, ensuring each viewpoint contributes according to its local observation reliability. For multi-object composition, we introduce physics-aware optimization that injects collision and contact constraints both during and after generation, yielding physically plausible object arrangements. Experiments on standard benchmarks and real-world multi-object scenes demonstrate significant improvements in reconstruction fidelity and layout plausibility, all without any additional training. Code is available at https://github.com/devinli123/MV-SAM3D.
Reflection-Based Task Adaptation for Self-Improving VLA
Oct 14, 2025Pre-trained Vision-Language-Action (VLA) models represent a major leap towards general-purpose robots, yet efficiently adapting them to novel, specific tasks in-situ remains a significant hurdle. While reinforcement learning (RL) is a promising avenue for such adaptation, the process often suffers from low efficiency, hindering rapid task mastery. We introduce Reflective Self-Adaptation, a framework for rapid, autonomous task adaptation without human intervention. Our framework establishes a self-improving loop where the agent learns from its own experience to enhance both strategy and execution. The core of our framework is a dual-pathway architecture that addresses the full adaptation lifecycle. First, a Failure-Driven Reflective RL pathway enables rapid learning by using the VLM's causal reasoning to automatically synthesize a targeted, dense reward function from failure analysis. This provides a focused learning signal that significantly accelerates policy exploration. However, optimizing such proxy rewards introduces a potential risk of "reward hacking," where the agent masters the reward function but fails the actual task. To counteract this, our second pathway, Success-Driven Quality-Guided SFT, grounds the policy in holistic success. It identifies and selectively imitates high-quality successful trajectories, ensuring the agent remains aligned with the ultimate task goal. This pathway is strengthened by a conditional curriculum mechanism to aid initial exploration. We conduct experiments in challenging manipulation tasks. The results demonstrate that our framework achieves faster convergence and higher final success rates compared to representative baselines. Our work presents a robust solution for creating self-improving agents that can efficiently and reliably adapt to new environments.
Pro-AD: Learning Comprehensive Prototypes with Prototype-based Constraint for Multi-class Unsupervised Anomaly Detection
Jun 16, 2025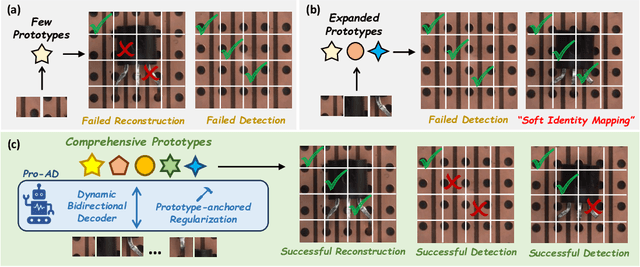



Prototype-based reconstruction methods for unsupervised anomaly detection utilize a limited set of learnable prototypes which only aggregates insufficient normal information, resulting in undesirable reconstruction. However, increasing the number of prototypes may lead to anomalies being well reconstructed through the attention mechanism, which we refer to as the "Soft Identity Mapping" problem. In this paper, we propose Pro-AD to address these issues and fully utilize the prototypes to boost the performance of anomaly detection. Specifically, we first introduce an expanded set of learnable prototypes to provide sufficient capacity for semantic information. Then we employ a Dynamic Bidirectional Decoder which integrates the process of the normal information aggregation and the target feature reconstruction via prototypes, with the aim of allowing the prototypes to aggregate more comprehensive normal semantic information from different levels of the image features and the target feature reconstruction to not only utilize its contextual information but also dynamically leverage the learned comprehensive prototypes. Additionally, to prevent the anomalies from being well reconstructed using sufficient semantic information through the attention mechanism, Pro-AD introduces a Prototype-based Constraint that applied within the target feature reconstruction process of the decoder, which further improves the performance of our approach. Extensive experiments on multiple challenging benchmarks demonstrate that our Pro-AD achieve state-of-the-art performance, highlighting its superior robustness and practical effectiveness for Multi-class Unsupervised Anomaly Detection task.
Domain-Specific Pruning of Large Mixture-of-Experts Models with Few-shot Demonstrations
Apr 09, 2025



Mixture-of-Experts (MoE) models achieve a favorable trade-off between performance and inference efficiency by activating only a subset of experts. However, the memory overhead of storing all experts remains a major limitation, especially in large-scale MoE models such as DeepSeek-R1 (671B). In this study, we investigate domain specialization and expert redundancy in large-scale MoE models and uncover a consistent behavior we term few-shot expert localization, with only a few demonstrations, the model consistently activates a sparse and stable subset of experts. Building on this observation, we propose a simple yet effective pruning framework, EASY-EP, that leverages a few domain-specific demonstrations to identify and retain only the most relevant experts. EASY-EP comprises two key components: output-aware expert importance assessment and expert-level token contribution estimation. The former evaluates the importance of each expert for the current token by considering the gating scores and magnitudes of the outputs of activated experts, while the latter assesses the contribution of tokens based on representation similarities after and before routed experts. Experiments show that our method can achieve comparable performances and $2.99\times$ throughput under the same memory budget with full DeepSeek-R1 with only half the experts. Our code is available at https://github.com/RUCAIBox/EASYEP.
Learn to Memorize and to Forget: A Continual Learning Perspective of Dynamic SLAM
Jul 18, 2024

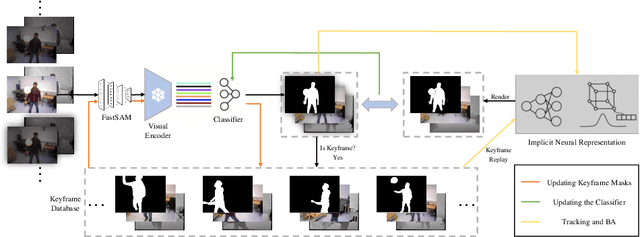
Simultaneous localization and mapping (SLAM) with implicit neural representations has received extensive attention due to the expressive representation power and the innovative paradigm of continual learning. However, deploying such a system within a dynamic environment has not been well-studied. Such challenges are intractable even for conventional algorithms since observations from different views with dynamic objects involved break the geometric and photometric consistency, whereas the consistency lays the foundation for joint optimizing the camera pose and the map parameters. In this paper, we best exploit the characteristics of continual learning and propose a novel SLAM framework for dynamic environments. While past efforts have been made to avoid catastrophic forgetting by exploiting an experience replay strategy, we view forgetting as a desirable characteristic. By adaptively controlling the replayed buffer, the ambiguity caused by moving objects can be easily alleviated through forgetting. We restrain the replay of the dynamic objects by introducing a continually-learned classifier for dynamic object identification. The iterative optimization of the neural map and the classifier notably improves the robustness of the SLAM system under a dynamic environment. Experiments on challenging datasets verify the effectiveness of the proposed framework.
DEDGAT: Dual Embedding of Directed Graph Attention Networks for Detecting Financial Risk
Mar 06, 2023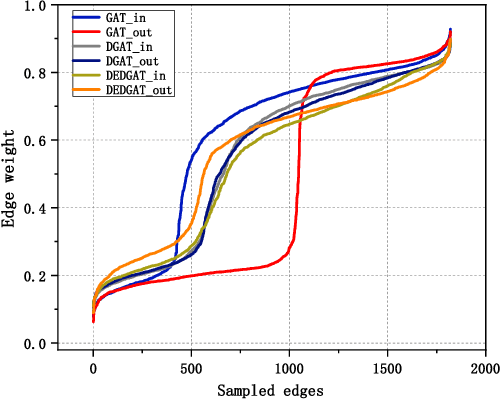
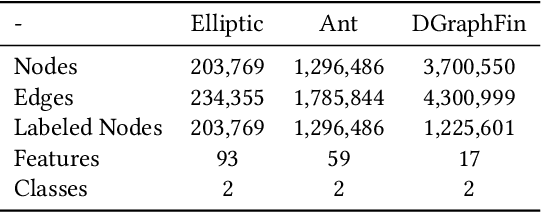
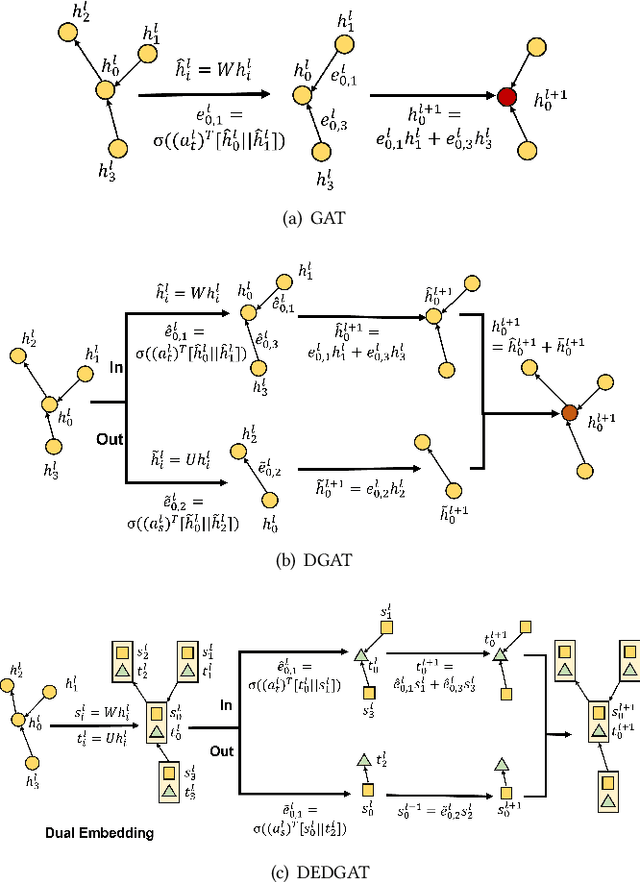
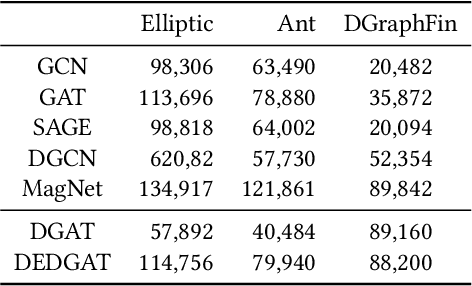
Graph representation plays an important role in the field of financial risk control, where the relationship among users can be constructed in a graph manner. In practical scenarios, the relationships between nodes in risk control tasks are bidirectional, e.g., merchants having both revenue and expense behaviors. Graph neural networks designed for undirected graphs usually aggregate discriminative node or edge representations with an attention strategy, but cannot fully exploit the out-degree information when used for the tasks built on directed graph, which leads to the problem of a directional bias. To tackle this problem, we propose a Directed Graph ATtention network called DGAT, which explicitly takes out-degree into attention calculation. In addition to having directional requirements, the same node might have different representations of its input and output, and thus we further propose a dual embedding of DGAT, referred to as DEDGAT. Specifically, DEDGAT assigns in-degree and out-degree representations to each node and uses these two embeddings to calculate the attention weights of in-degree and out-degree nodes, respectively. Experiments performed on the benchmark datasets show that DGAT and DEDGAT obtain better classification performance compared to undirected GAT. Also,the visualization results demonstrate that our methods can fully use both in-degree and out-degree information.
Part-level Action Parsing via a Pose-guided Coarse-to-Fine Framework
Mar 09, 2022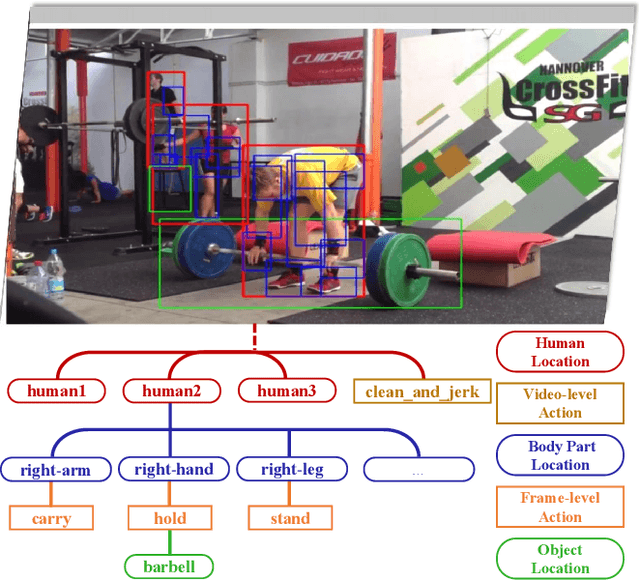
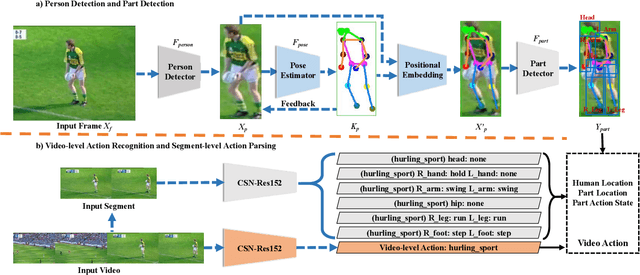
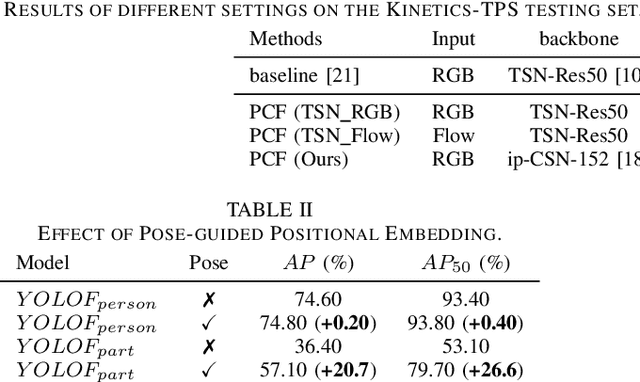
Action recognition from videos, i.e., classifying a video into one of the pre-defined action types, has been a popular topic in the communities of artificial intelligence, multimedia, and signal processing. However, existing methods usually consider an input video as a whole and learn models, e.g., Convolutional Neural Networks (CNNs), with coarse video-level class labels. These methods can only output an action class for the video, but cannot provide fine-grained and explainable cues to answer why the video shows a specific action. Therefore, researchers start to focus on a new task, Part-level Action Parsing (PAP), which aims to not only predict the video-level action but also recognize the frame-level fine-grained actions or interactions of body parts for each person in the video. To this end, we propose a coarse-to-fine framework for this challenging task. In particular, our framework first predicts the video-level class of the input video, then localizes the body parts and predicts the part-level action. Moreover, to balance the accuracy and computation in part-level action parsing, we propose to recognize the part-level actions by segment-level features. Furthermore, to overcome the ambiguity of body parts, we propose a pose-guided positional embedding method to accurately localize body parts. Through comprehensive experiments on a large-scale dataset, i.e., Kinetics-TPS, our framework achieves state-of-the-art performance and outperforms existing methods over a 31.10% ROC score.
Boosting Video Representation Learning with Multi-Faceted Integration
Jan 11, 2022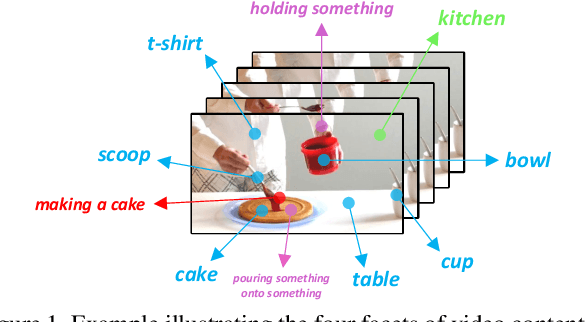
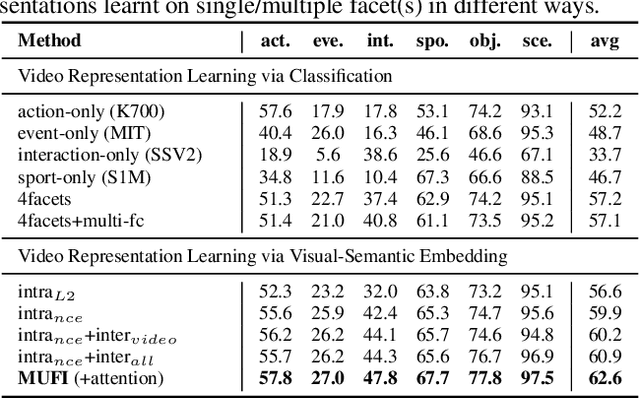
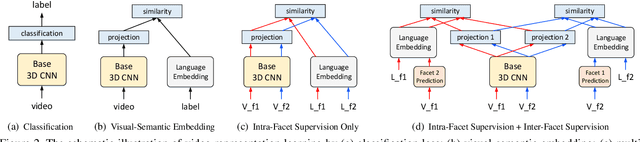
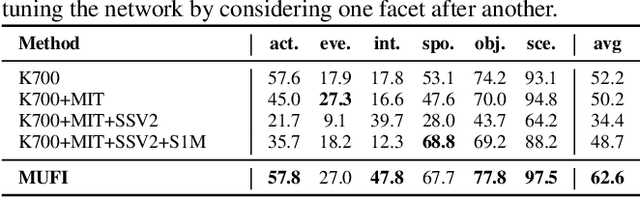
Video content is multifaceted, consisting of objects, scenes, interactions or actions. The existing datasets mostly label only one of the facets for model training, resulting in the video representation that biases to only one facet depending on the training dataset. There is no study yet on how to learn a video representation from multifaceted labels, and whether multifaceted information is helpful for video representation learning. In this paper, we propose a new learning framework, MUlti-Faceted Integration (MUFI), to aggregate facets from different datasets for learning a representation that could reflect the full spectrum of video content. Technically, MUFI formulates the problem as visual-semantic embedding learning, which explicitly maps video representation into a rich semantic embedding space, and jointly optimizes video representation from two perspectives. One is to capitalize on the intra-facet supervision between each video and its own label descriptions, and the second predicts the "semantic representation" of each video from the facets of other datasets as the inter-facet supervision. Extensive experiments demonstrate that learning 3D CNN via our MUFI framework on a union of four large-scale video datasets plus two image datasets leads to superior capability of video representation. The pre-learnt 3D CNN with MUFI also shows clear improvements over other approaches on several downstream video applications. More remarkably, MUFI achieves 98.1%/80.9% on UCF101/HMDB51 for action recognition and 101.5% in terms of CIDEr-D score on MSVD for video captioning.
YOLOP: You Only Look Once for Panoptic Driving Perception
Aug 31, 2021
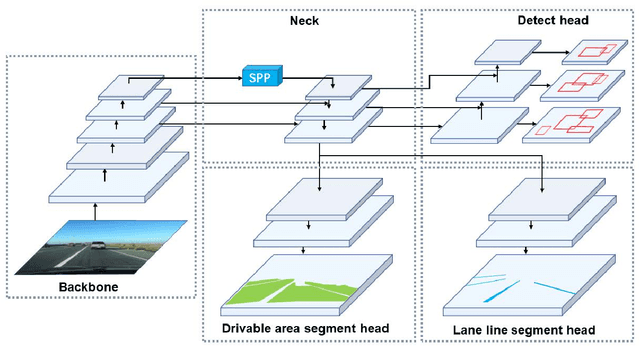


A panoptic driving perception system is an essential part of autonomous driving. A high-precision and real-time perception system can assist the vehicle in making the reasonable decision while driving. We present a panoptic driving perception network (YOLOP) to perform traffic object detection, drivable area segmentation and lane detection simultaneously. It is composed of one encoder for feature extraction and three decoders to handle the specific tasks. Our model performs extremely well on the challenging BDD100K dataset, achieving state-of-the-art on all three tasks in terms of accuracy and speed. Besides, we verify the effectiveness of our multi-task learning model for joint training via ablative studies. To our best knowledge, this is the first work that can process these three visual perception tasks simultaneously in real-time on an embedded device Jetson TX2(23 FPS) and maintain excellent accuracy. To facilitate further research, the source codes and pre-trained models will be released at https://github.com/hustvl/YOLOP.