 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianFluent: Gaussian Simulation for Dynamic Scenes with Mixed Materials
Jan 14, 20263D Gaussian Splatting (3DGS) has emerged as a prominent 3D representation for high-fidelity and real-time rendering. Prior work has coupled physics simulation with Gaussians, but predominantly targets soft, deformable materials, leaving brittle fracture largely unresolved. This stems from two key obstacles: the lack of volumetric interiors with coherent textures in GS representation, and the absence of fracture-aware simulation methods for Gaussians. To address these challenges, we introduce GaussianFluent, a unified framework for realistic simulation and rendering of dynamic object states. First, it synthesizes photorealistic interiors by densifying internal Gaussians guided by generative models. Second, it integrates an optimized Continuum Damage Material Point Method (CD-MPM) to enable brittle fracture simulation at remarkably high speed. Our approach handles complex scenarios including mixed-material objects and multi-stage fracture propagation, achieving results infeasible with previous methods. Experiments clearly demonstrate GaussianFluent's capability for photo-realistic, real-time rendering with structurally consistent interiors, highlighting its potential for downstream application, such as VR and Robotics.
Reflection-Based Task Adaptation for Self-Improving VLA
Oct 14, 2025Pre-trained Vision-Language-Action (VLA) models represent a major leap towards general-purpose robots, yet efficiently adapting them to novel, specific tasks in-situ remains a significant hurdle. While reinforcement learning (RL) is a promising avenue for such adaptation, the process often suffers from low efficiency, hindering rapid task mastery. We introduce Reflective Self-Adaptation, a framework for rapid, autonomous task adaptation without human intervention. Our framework establishes a self-improving loop where the agent learns from its own experience to enhance both strategy and execution. The core of our framework is a dual-pathway architecture that addresses the full adaptation lifecycle. First, a Failure-Driven Reflective RL pathway enables rapid learning by using the VLM's causal reasoning to automatically synthesize a targeted, dense reward function from failure analysis. This provides a focused learning signal that significantly accelerates policy exploration. However, optimizing such proxy rewards introduces a potential risk of "reward hacking," where the agent masters the reward function but fails the actual task. To counteract this, our second pathway, Success-Driven Quality-Guided SFT, grounds the policy in holistic success. It identifies and selectively imitates high-quality successful trajectories, ensuring the agent remains aligned with the ultimate task goal. This pathway is strengthened by a conditional curriculum mechanism to aid initial exploration. We conduct experiments in challenging manipulation tasks. The results demonstrate that our framework achieves faster convergence and higher final success rates compared to representative baselines. Our work presents a robust solution for creating self-improving agents that can efficiently and reliably adapt to new environments.
Multi-level Dynamic Style Transfer for NeRFs
Oct 01, 2025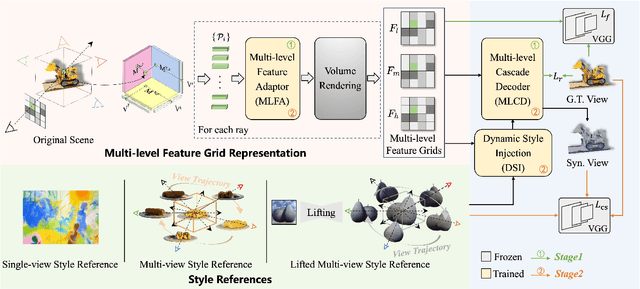
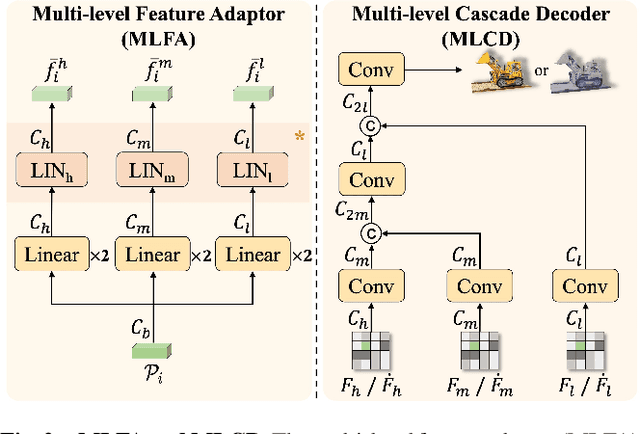


As the application of neural radiance fields (NeRFs) in various 3D vision tasks continues to expand, numerous NeRF-based style transfer techniques have been developed. However, existing methods typically integrate style statistics into the original NeRF pipeline, often leading to suboptimal results in both content preservation and artistic stylization. In this paper, we present multi-level dynamic style transfer for NeRFs (MDS-NeRF), a novel approach that reengineers the NeRF pipeline specifically for stylization and incorporates an innovative dynamic style injection module. Particularly, we propose a multi-level feature adaptor that helps generate a multi-level feature grid representation from the content radiance field, effectively capturing the multi-scale spatial structure of the scene. In addition, we present a dynamic style injection module that learns to extract relevant style features and adaptively integrates them into the content patterns. The stylized multi-level features are then transformed into the final stylized view through our proposed multi-level cascade decoder. Furthermore, we extend our 3D style transfer method to support omni-view style transfer using 3D style references. Extensive experiments demonstrate that MDS-NeRF achieves outstanding performance for 3D style transfer, preserving multi-scale spatial structures while effectively transferring stylistic characteristics.
TrueMoE: Dual-Routing Mixture of Discriminative Experts for Synthetic Image Detection
Sep 19, 2025
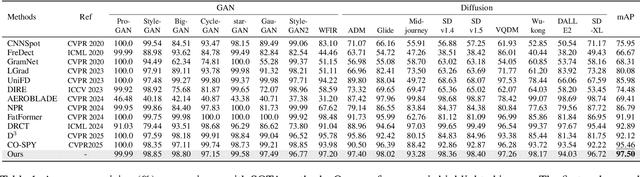

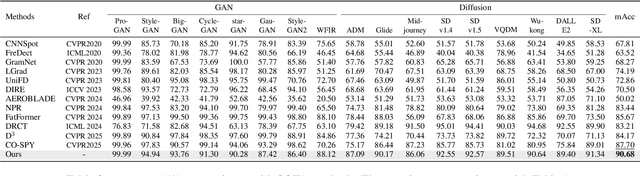
The rapid progress of generative models has made synthetic image detection an increasingly critical task. Most existing approaches attempt to construct a single, universal discriminative space to separate real from fake content. However, such unified spaces tend to be complex and brittle, often struggling to generalize to unseen generative patterns. In this work, we propose TrueMoE, a novel dual-routing Mixture-of-Discriminative-Experts framework that reformulates the detection task as a collaborative inference across multiple specialized and lightweight discriminative subspaces. At the core of TrueMoE is a Discriminative Expert Array (DEA) organized along complementary axes of manifold structure and perceptual granularity, enabling diverse forgery cues to be captured across subspaces. A dual-routing mechanism, comprising a granularity-aware sparse router and a manifold-aware dense router, adaptively assigns input images to the most relevant experts. Extensive experiments across a wide spectrum of generative models demonstrate that TrueMoE achieves superior generalization and robustness.
Active Neural Mapping at Scale
Sep 30, 2024



We introduce a NeRF-based active mapping system that enables efficient and robust exploration of large-scale indoor environments. The key to our approach is the extraction of a generalized Voronoi graph (GVG) from the continually updated neural map, leading to the synergistic integration of scene geometry, appearance, topology, and uncertainty. Anchoring uncertain areas induced by the neural map to the vertices of GVG allows the exploration to undergo adaptive granularity along a safe path that traverses unknown areas efficiently. Harnessing a modern hybrid NeRF representation, the proposed system achieves competitive results in terms of reconstruction accuracy, coverage completeness, and exploration efficiency even when scaling up to large indoor environments. Extensive results at different scales validate the efficacy of the proposed system.
Learn to Memorize and to Forget: A Continual Learning Perspective of Dynamic SLAM
Jul 18, 2024
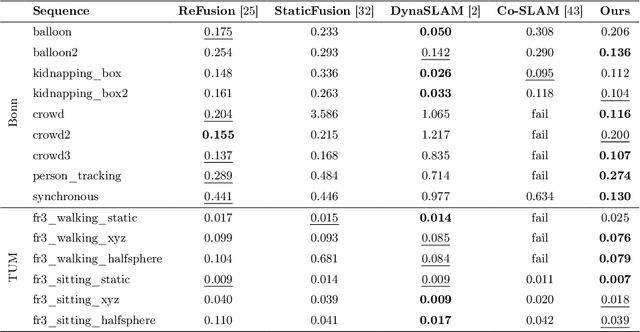

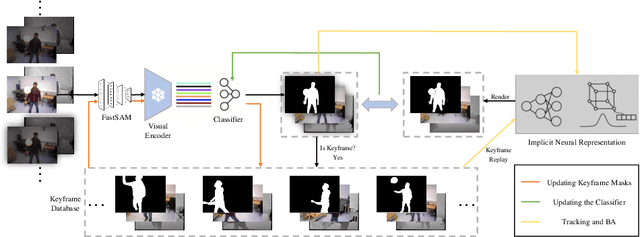
Simultaneous localization and mapping (SLAM) with implicit neural representations has received extensive attention due to the expressive representation power and the innovative paradigm of continual learning. However, deploying such a system within a dynamic environment has not been well-studied. Such challenges are intractable even for conventional algorithms since observations from different views with dynamic objects involved break the geometric and photometric consistency, whereas the consistency lays the foundation for joint optimizing the camera pose and the map parameters. In this paper, we best exploit the characteristics of continual learning and propose a novel SLAM framework for dynamic environments. While past efforts have been made to avoid catastrophic forgetting by exploiting an experience replay strategy, we view forgetting as a desirable characteristic. By adaptively controlling the replayed buffer, the ambiguity caused by moving objects can be easily alleviated through forgetting. We restrain the replay of the dynamic objects by introducing a continually-learned classifier for dynamic object identification. The iterative optimization of the neural map and the classifier notably improves the robustness of the SLAM system under a dynamic environment. Experiments on challenging datasets verify the effectiveness of the proposed framework.
Adaptive VIO: Deep Visual-Inertial Odometry with Online Continual Learning
May 27, 2024



Visual-inertial odometry (VIO) has demonstrated remarkable success due to its low-cost and complementary sensors. However, existing VIO methods lack the generalization ability to adjust to different environments and sensor attributes. In this paper, we propose Adaptive VIO, a new monocular visual-inertial odometry that combines online continual learning with traditional nonlinear optimization. Adaptive VIO comprises two networks to predict visual correspondence and IMU bias. Unlike end-to-end approaches that use networks to fuse the features from two modalities (camera and IMU) and predict poses directly, we combine neural networks with visual-inertial bundle adjustment in our VIO system. The optimized estimates will be fed back to the visual and IMU bias networks, refining the networks in a self-supervised manner. Such a learning-optimization-combined framework and feedback mechanism enable the system to perform online continual learning. Experiments demonstrate that our Adaptive VIO manifests adaptive capability on EuRoC and TUM-VI datasets. The overall performance exceeds the currently known learning-based VIO methods and is comparable to the state-of-the-art optimization-based methods.
Depth Reconstruction with Neural Signed Distance Fields in Structured Light Systems
May 20, 2024



We introduce a novel depth estimation technique for multi-frame structured light setups using neural implicit representations of 3D space. Our approach employs a neural signed distance field (SDF), trained through self-supervised differentiable rendering. Unlike passive vision, where joint estimation of radiance and geometry fields is necessary, we capitalize on known radiance fields from projected patterns in structured light systems. This enables isolated optimization of the geometry field, ensuring convergence and network efficacy with fixed device positioning. To enhance geometric fidelity, we incorporate an additional color loss based on object surfaces during training. Real-world experiments demonstrate our method's superiority in geometric performance for few-shot scenarios, while achieving comparable results with increased pattern availability.
Online Adaptive Disparity Estimation for Dynamic Scenes in Structured Light Systems
Oct 13, 2023



In recent years, deep neural networks have shown remarkable progress in dense disparity estimation from dynamic scenes in monocular structured light systems. However, their performance significantly drops when applied in unseen environments. To address this issue, self-supervised online adaptation has been proposed as a solution to bridge this performance gap. Unlike traditional fine-tuning processes, online adaptation performs test-time optimization to adapt networks to new domains. Therefore, achieving fast convergence during the adaptation process is critical for attaining satisfactory accuracy. In this paper, we propose an unsupervised loss function based on long sequential inputs. It ensures better gradient directions and faster convergence. Our loss function is designed using a multi-frame pattern flow, which comprises a set of sparse trajectories of the projected pattern along the sequence. We estimate the sparse pseudo ground truth with a confidence mask using a filter-based method, which guides the online adaptation process. Our proposed framework significantly improves the online adaptation speed and achieves superior performance on unseen data.
TIDE: Temporally Incremental Disparity Estimation via Pattern Flow in Structured Light System
Oct 13, 2023We introduced Temporally Incremental Disparity Estimation Network (TIDE-Net), a learning-based technique for disparity computation in mono-camera structured light systems. In our hardware setting, a static pattern is projected onto a dynamic scene and captured by a monocular camera. Different from most former disparity estimation methods that operate in a frame-wise manner, our network acquires disparity maps in a temporally incremental way. Specifically, We exploit the deformation of projected patterns (named pattern flow ) on captured image sequences, to model the temporal information. Notably, this newly proposed pattern flow formulation reflects the disparity changes along the epipolar line, which is a special form of optical flow. Tailored for pattern flow, the TIDE-Net, a recurrent architecture, is proposed and implemented. For each incoming frame, our model fuses correlation volumes (from current frame) and disparity (from former frame) warped by pattern flow. From fused features, the final stage of TIDE-Net estimates the residual disparity rather than the full disparity, as conducted by many previous methods. Interestingly, this design brings clear empirical advantages in terms of efficiency and generalization ability. Using only synthetic data for training, our extensitve evaluation results (w.r.t. both accuracy and efficienty metrics) show superior performance than several SOTA models on unseen real data. The code is available on https://github.com/CodePointer/TIDENet.