 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive VIO: Deep Visual-Inertial Odometry with Online Continual Learning
May 27, 2024



Visual-inertial odometry (VIO) has demonstrated remarkable success due to its low-cost and complementary sensors. However, existing VIO methods lack the generalization ability to adjust to different environments and sensor attributes. In this paper, we propose Adaptive VIO, a new monocular visual-inertial odometry that combines online continual learning with traditional nonlinear optimization. Adaptive VIO comprises two networks to predict visual correspondence and IMU bias. Unlike end-to-end approaches that use networks to fuse the features from two modalities (camera and IMU) and predict poses directly, we combine neural networks with visual-inertial bundle adjustment in our VIO system. The optimized estimates will be fed back to the visual and IMU bias networks, refining the networks in a self-supervised manner. Such a learning-optimization-combined framework and feedback mechanism enable the system to perform online continual learning. Experiments demonstrate that our Adaptive VIO manifests adaptive capability on EuRoC and TUM-VI datasets. The overall performance exceeds the currently known learning-based VIO methods and is comparable to the state-of-the-art optimization-based methods.
SC-wLS: Towards Interpretable Feed-forward Camera Re-localization
Oct 23, 2022Visual re-localization aims to recover camera poses in a known environment, which is vital for applications like robotics or augmented reality. Feed-forward absolute camera pose regression methods directly output poses by a network, but suffer from low accuracy. Meanwhile, scene coordinate based methods are accurate, but need iterative RANSAC post-processing, which brings challenges to efficient end-to-end training and inference. In order to have the best of both worlds, we propose a feed-forward method termed SC-wLS that exploits all scene coordinate estimates for weighted least squares pose regression. This differentiable formulation exploits a weight network imposed on 2D-3D correspondences, and requires pose supervision only. Qualitative results demonstrate the interpretability of learned weights. Evaluations on 7Scenes and Cambridge datasets show significantly promoted performance when compared with former feed-forward counterparts. Moreover, our SC-wLS method enables a new capability: self-supervised test-time adaptation on the weight network. Codes and models are publicly available.
Generalizing to the Open World: Deep Visual Odometry with Online Adaptation
Mar 29, 2021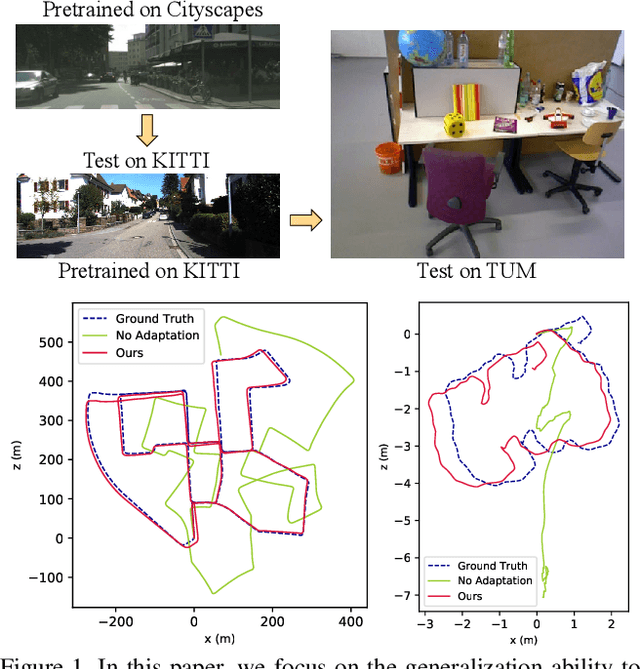
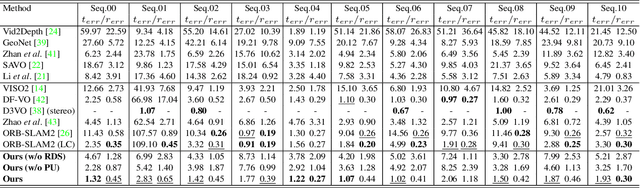
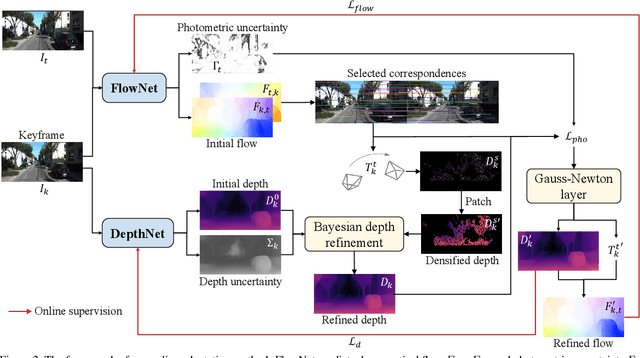
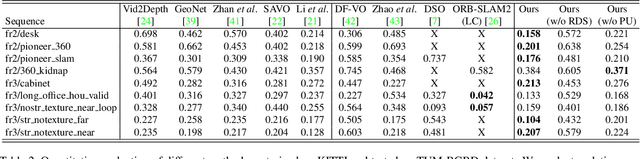
Despite learning-based visual odometry (VO) has shown impressive results in recent years, the pretrained networks may easily collapse in unseen environments. The large domain gap between training and testing data makes them difficult to generalize to new scenes. In this paper, we propose an online adaptation framework for deep VO with the assistance of scene-agnostic geometric computations and Bayesian inference. In contrast to learning-based pose estimation, our method solves pose from optical flow and depth while the single-view depth estimation is continuously improved with new observations by online learned uncertainties. Meanwhile, an online learned photometric uncertainty is used for further depth and pose optimization by a differentiable Gauss-Newton layer. Our method enables fast adaptation of deep VO networks to unseen environments in a self-supervised manner. Extensive experiments including Cityscapes to KITTI and outdoor KITTI to indoor TUM demonstrate that our method achieves state-of-the-art generalization ability among self-supervised VO methods.
Self-Supervised Deep Visual Odometry with Online Adaptation
May 13, 2020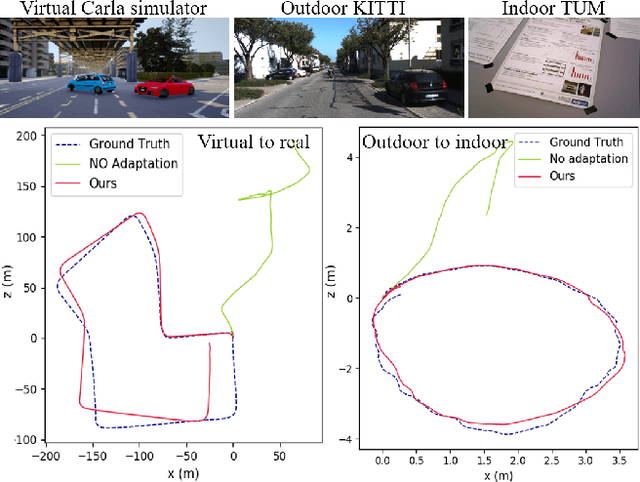
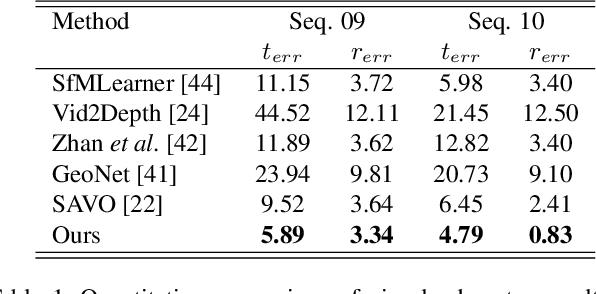
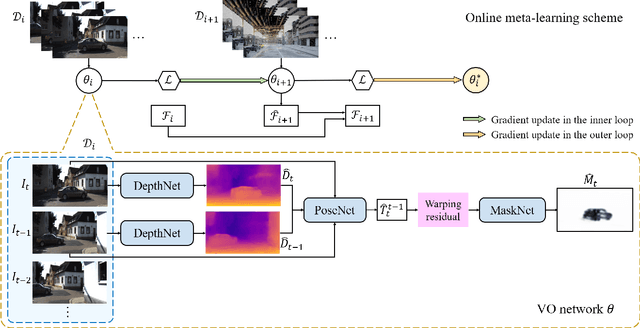

Self-supervised VO methods have shown great success in jointly estimating camera pose and depth from videos. However, like most data-driven methods, existing VO networks suffer from a notable decrease in performance when confronted with scenes different from the training data, which makes them unsuitable for practical applications. In this paper, we propose an online meta-learning algorithm to enable VO networks to continuously adapt to new environments in a self-supervised manner. The proposed method utilizes convolutional long short-term memory (convLSTM) to aggregate rich spatial-temporal information in the past. The network is able to memorize and learn from its past experience for better estimation and fast adaptation to the current frame. When running VO in the open world, in order to deal with the changing environment, we propose an online feature alignment method by aligning feature distributions at different time. Our VO network is able to seamlessly adapt to different environments. Extensive experiments on unseen outdoor scenes, virtual to real world and outdoor to indoor environments demonstrate that our method consistently outperforms state-of-the-art self-supervised VO baselines considerably.