 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline3R: Online Learning for Consistent Sequential Reconstruction Based on Geometry Foundation Model
Apr 10, 2026We present Online3R, a new sequential reconstruction framework that is capable of adapting to new scenes through online learning, effectively resolving inconsistency issues. Specifically, we introduce a set of learnable lightweight visual prompts into a pretrained, frozen geometry foundation model to capture the knowledge of new environments while preserving the fundamental capability of the foundation model for geometry prediction. To solve the problems of missing groundtruth and the requirement of high efficiency when updating these visual prompts at test time, we introduce a local-global self-supervised learning strategy by enforcing the local and global consistency constraints on predictions. The local consistency constraints are conducted on intermediate and previously local fused results, enabling the model to be trained with high-quality pseudo groundtruth signals; the global consistency constraints are operated on sparse keyframes spanning long distances rather than per frame, allowing the model to learn from a consistent prediction over a long trajectory in an efficient way. Our experiments demonstrate that Online3R outperforms previous state-of-the-art methods on various benchmarks. Project page: https://shunkaizhou.github.io/online3r-1.0/
Identifiable Deep Latent Variable Models for MNAR Data
Mar 27, 2026Missing data is a ubiquitous challenge in data analysis, often leading to biased and inaccurate results. Traditional imputation methods usually assume that the missingness mechanism is missing-at-random (MAR), where the missingness is independent of the missing values themselves. This assumption is frequently violated in real-world scenarios, prompted by recent advances in imputation methods using deep learning to address this challenge. However, these methods neglect the crucial issue of nonparametric identifiability in missing-not-at-random (MNAR) data, which can lead to biased and unreliable results. This paper seeks to bridge this gap by proposing a novel framework based on deep latent variable models for MNAR data. Building on the assumption of conditional no self-censoring given latent variables, we establish the identifiability of the data distribution. This crucial theoretical result guarantees the feasibility of our approach. To effectively estimate unknown parameters, we develop an efficient algorithm utilizing importance-weighted autoencoders. We demonstrate, both theoretically and empirically, that our estimation process accurately recovers the ground-truth joint distribution under specific regularity conditions. Extensive simulation studies and real-world data experiments showcase the advantages of our proposed method compared to various classical and state-of-the-art approaches to missing data imputation.
MATCHA:Towards Matching Anything
Jan 24, 2025



Establishing correspondences across images is a fundamental challenge in computer vision, underpinning tasks like Structure-from-Motion, image editing, and point tracking. Traditional methods are often specialized for specific correspondence types, geometric, semantic, or temporal, whereas humans naturally identify alignments across these domains. Inspired by this flexibility, we propose MATCHA, a unified feature model designed to ``rule them all'', establishing robust correspondences across diverse matching tasks. Building on insights that diffusion model features can encode multiple correspondence types, MATCHA augments this capacity by dynamically fusing high-level semantic and low-level geometric features through an attention-based module, creating expressive, versatile, and robust features. Additionally, MATCHA integrates object-level features from DINOv2 to further boost generalization, enabling a single feature capable of matching anything. Extensive experiments validate that MATCHA consistently surpasses state-of-the-art methods across geometric, semantic, and temporal matching tasks, setting a new foundation for a unified approach for the fundamental correspondence problem in computer vision. To the best of our knowledge, MATCHA is the first approach that is able to effectively tackle diverse matching tasks with a single unified feature.
VRS-NeRF: Visual Relocalization with Sparse Neural Radiance Field
Apr 14, 2024



Visual relocalization is a key technique to autonomous driving, robotics, and virtual/augmented reality. After decades of explorations, absolute pose regression (APR), scene coordinate regression (SCR), and hierarchical methods (HMs) have become the most popular frameworks. However, in spite of high efficiency, APRs and SCRs have limited accuracy especially in large-scale outdoor scenes; HMs are accurate but need to store a large number of 2D descriptors for matching, resulting in poor efficiency. In this paper, we propose an efficient and accurate framework, called VRS-NeRF, for visual relocalization with sparse neural radiance field. Precisely, we introduce an explicit geometric map (EGM) for 3D map representation and an implicit learning map (ILM) for sparse patches rendering. In this localization process, EGP provides priors of spare 2D points and ILM utilizes these sparse points to render patches with sparse NeRFs for matching. This allows us to discard a large number of 2D descriptors so as to reduce the map size. Moreover, rendering patches only for useful points rather than all pixels in the whole image reduces the rendering time significantly. This framework inherits the accuracy of HMs and discards their low efficiency. Experiments on 7Scenes, CambridgeLandmarks, and Aachen datasets show that our method gives much better accuracy than APRs and SCRs, and close performance to HMs but is much more efficient.
PRAM: Place Recognition Anywhere Model for Efficient Visual Localization
Apr 11, 2024



Humans localize themselves efficiently in known environments by first recognizing landmarks defined on certain objects and their spatial relationships, and then verifying the location by aligning detailed structures of recognized objects with those in the memory. Inspired by this, we propose the place recognition anywhere model (PRAM) to perform visual localization as efficiently as humans do. PRAM consists of two main components - recognition and registration. In detail, first of all, a self-supervised map-centric landmark definition strategy is adopted, making places in either indoor or outdoor scenes act as unique landmarks. Then, sparse keypoints extracted from images, are utilized as the input to a transformer-based deep neural network for landmark recognition; these keypoints enable PRAM to recognize hundreds of landmarks with high time and memory efficiency. Keypoints along with recognized landmark labels are further used for registration between query images and the 3D landmark map. Different from previous hierarchical methods, PRAM discards global and local descriptors, and reduces over 90% storage. Since PRAM utilizes recognition and landmark-wise verification to replace global reference search and exhaustive matching respectively, it runs 2.4 times faster than prior state-of-the-art approaches. Moreover, PRAM opens new directions for visual localization including multi-modality localization, map-centric feature learning, and hierarchical scene coordinate regression.
Individualized Dynamic Model for Multi-resolutional Data
Nov 22, 2023



Mobile health has emerged as a major success in tracking individual health status, due to the popularity and power of smartphones and wearable devices. This has also brought great challenges in handling heterogeneous, multi-resolution data which arise ubiquitously in mobile health due to irregular multivariate measurements collected from individuals. In this paper, we propose an individualized dynamic latent factor model for irregular multi-resolution time series data to interpolate unsampled measurements of time series with low resolution. One major advantage of the proposed method is the capability to integrate multiple irregular time series and multiple subjects by mapping the multi-resolution data to the latent space. In addition, the proposed individualized dynamic latent factor model is applicable to capturing heterogeneous longitudinal information through individualized dynamic latent factors. In theory, we provide the integrated interpolation error bound of the proposed estimator and derive the convergence rate with B-spline approximation methods. Both the simulation studies and the application to smartwatch data demonstrate the superior performance of the proposed method compared to existing methods.
SFD2: Semantic-guided Feature Detection and Description
Apr 28, 2023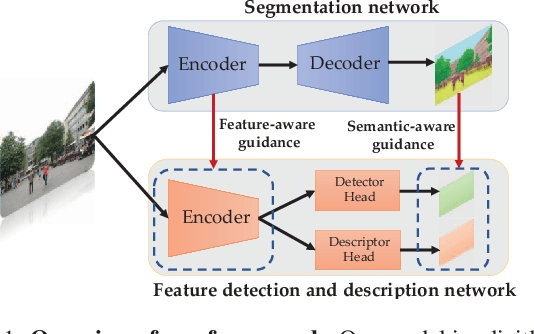
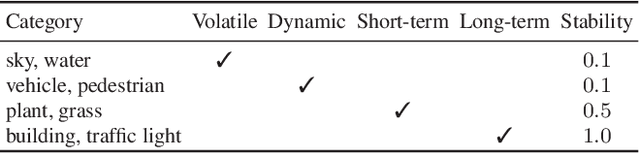

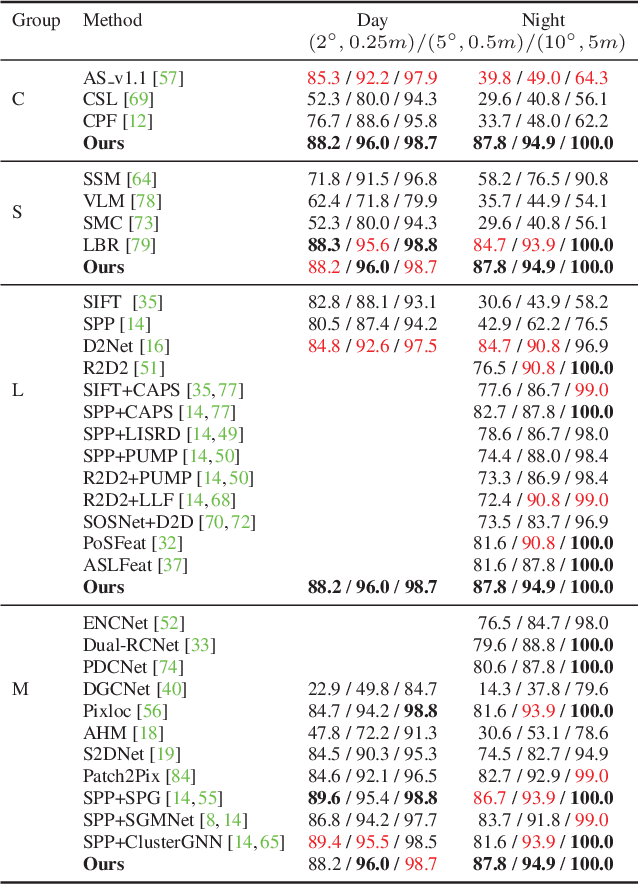
Visual localization is a fundamental task for various applications including autonomous driving and robotics. Prior methods focus on extracting large amounts of often redundant locally reliable features, resulting in limited efficiency and accuracy, especially in large-scale environments under challenging conditions. Instead, we propose to extract globally reliable features by implicitly embedding high-level semantics into both the detection and description processes. Specifically, our semantic-aware detector is able to detect keypoints from reliable regions (e.g. building, traffic lane) and suppress unreliable areas (e.g. sky, car) implicitly instead of relying on explicit semantic labels. This boosts the accuracy of keypoint matching by reducing the number of features sensitive to appearance changes and avoiding the need of additional segmentation networks at test time. Moreover, our descriptors are augmented with semantics and have stronger discriminative ability, providing more inliers at test time. Particularly, experiments on long-term large-scale visual localization Aachen Day-Night and RobotCar-Seasons datasets demonstrate that our model outperforms previous local features and gives competitive accuracy to advanced matchers but is about 2 and 3 times faster when using 2k and 4k keypoints, respectively.
IMP: Iterative Matching and Pose Estimation with Adaptive Pooling
Apr 28, 2023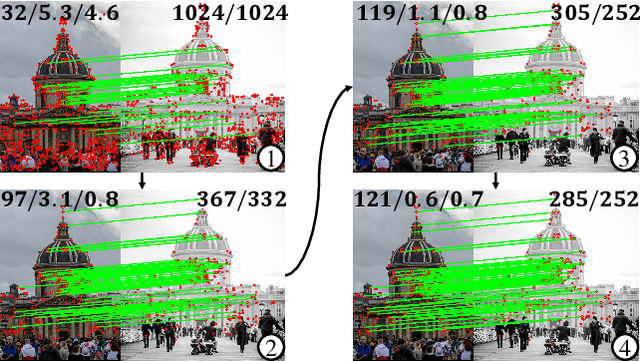
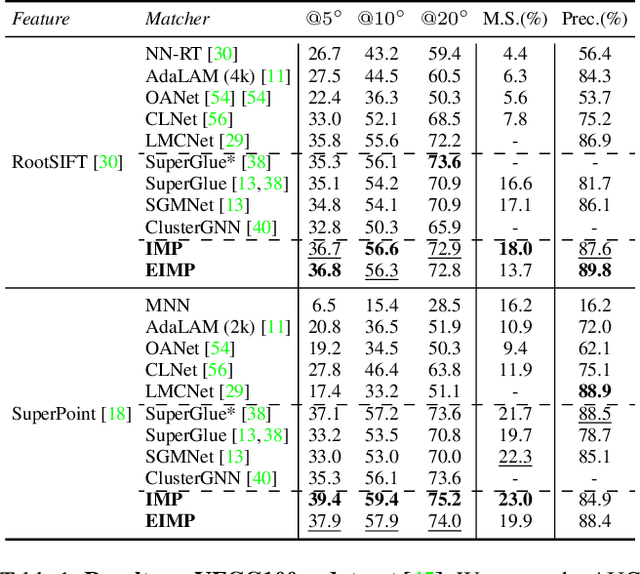
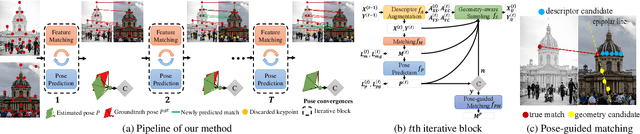
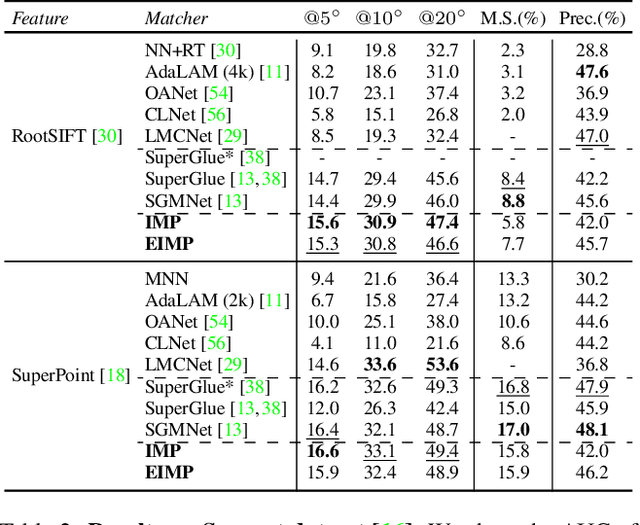
Previous methods solve feature matching and pose estimation using a two-stage process by first finding matches and then estimating the pose. As they ignore the geometric relationships between the two tasks, they focus on either improving the quality of matches or filtering potential outliers, leading to limited efficiency or accuracy. In contrast, we propose an iterative matching and pose estimation framework (IMP) leveraging the geometric connections between the two tasks: a few good matches are enough for a roughly accurate pose estimation; a roughly accurate pose can be used to guide the matching by providing geometric constraints. To this end, we implement a geometry-aware recurrent attention-based module which jointly outputs sparse matches and camera poses. Specifically, for each iteration, we first implicitly embed geometric information into the module via a pose-consistency loss, allowing it to predict geometry-aware matches progressively. Second, we introduce an \textbf{e}fficient IMP, called EIMP, to dynamically discard keypoints without potential matches, avoiding redundant updating and significantly reducing the quadratic time complexity of attention computation in transformers. Experiments on YFCC100m, Scannet, and Aachen Day-Night datasets demonstrate that the proposed method outperforms previous approaches in terms of accuracy and efficiency.
Semi-Supervised Statistical Inference for High-Dimensional Linear Regression with Blockwise Missing Data
Jun 07, 2021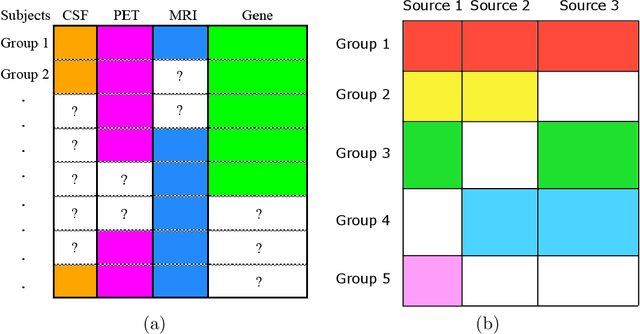

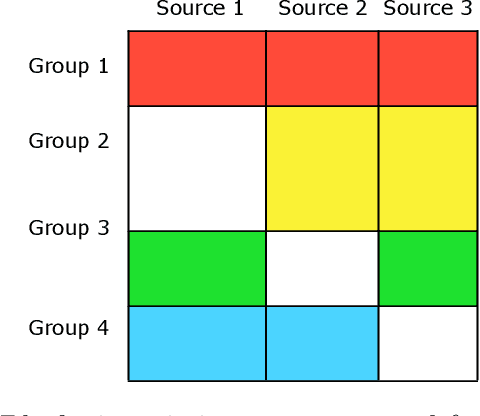

Blockwise missing data occurs frequently when we integrate multisource or multimodality data where different sources or modalities contain complementary information. In this paper, we consider a high-dimensional linear regression model with blockwise missing covariates and a partially observed response variable. Under this semi-supervised framework, we propose a computationally efficient estimator for the regression coefficient vector based on carefully constructed unbiased estimating equations and a multiple blockwise imputation procedure, and obtain its rates of convergence. Furthermore, building upon an innovative semi-supervised projected estimating equation technique that intrinsically achieves bias-correction of the initial estimator, we propose nearly unbiased estimators for the individual regression coefficients that are asymptotically normally distributed under mild conditions. By carefully analyzing these debiased estimators, asymptotically valid confidence intervals and statistical tests about each regression coefficient are constructed. Numerical studies and application analysis of the Alzheimer's Disease Neuroimaging Initiative data show that the proposed method performs better and benefits more from unsupervised samples than existing methods.
Active Terahertz Imaging Dataset for Concealed Object Detection
May 08, 2021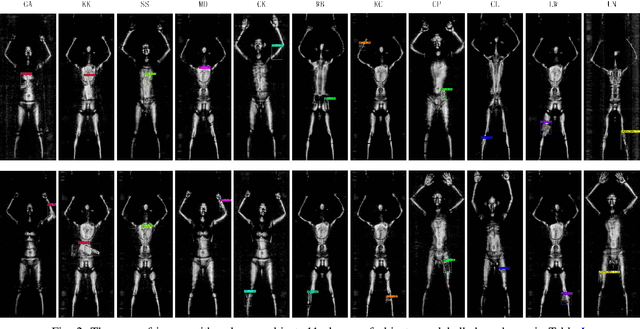
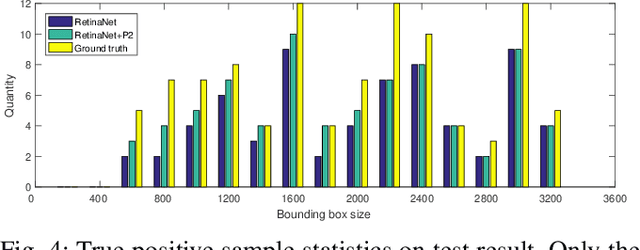
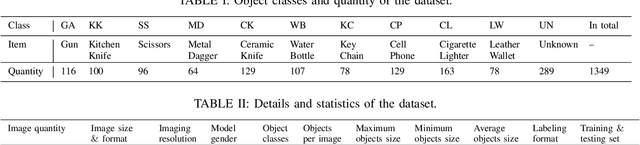

Concealed object detection in Terahertz imaging is an urgent need for public security and counter-terrorism. In this paper, we provide a public dataset for evaluating multi-object detection algorithms in active Terahertz imaging resolution 5 mm by 5 mm. To the best of our knowledge, this is the first public Terahertz imaging dataset prepared to evaluate object detection algorithms. Object detection on this dataset is much more difficult than on those standard public object detection datasets due to its inferior imaging quality. Facing the problem of imbalanced samples in object detection and hard training samples, we evaluate four popular detectors: YOLOv3, YOLOv4, FRCN-OHEM, and RetinaNet on this dataset. Experimental results indicate that the RetinaNet achieves the highest mAP. In addition, we demonstrate that hiding objects in different parts of the human body affect detection accuracy. The dataset is available at https://github.com/LingLIx/THz_Dataset.