 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVDAWorld: World Modelling via VLM-Directed Abstraction and Simulation
Dec 11, 2025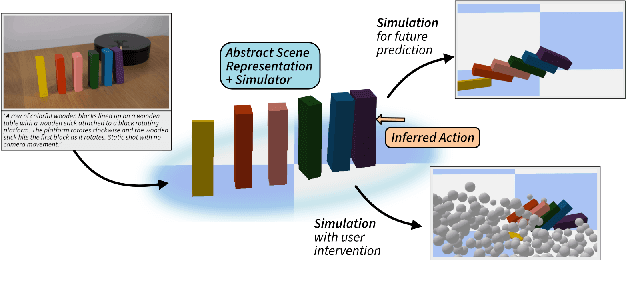
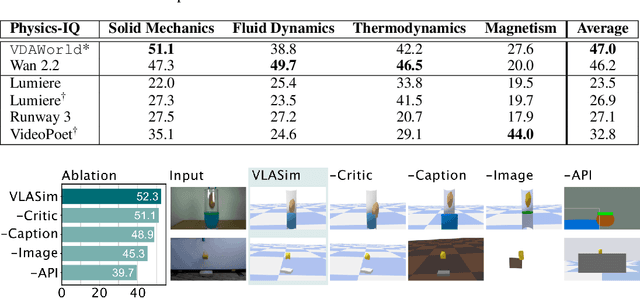
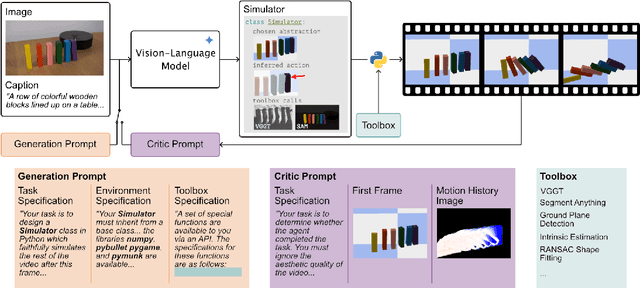

Generative video models, a leading approach to world modeling, face fundamental limitations. They often violate physical and logical rules, lack interactivity, and operate as opaque black boxes ill-suited for building structured, queryable worlds. To overcome these challenges, we propose a new paradigm focused on distilling an image caption pair into a tractable, abstract representation optimized for simulation. We introduce VDAWorld, a framework where a Vision-Language Model (VLM) acts as an intelligent agent to orchestrate this process. The VLM autonomously constructs a grounded (2D or 3D) scene representation by selecting from a suite of vision tools, and accordingly chooses a compatible physics simulator (e.g., rigid body, fluid) to act upon it. VDAWorld can then infer latent dynamics from the static scene to predict plausible future states. Our experiments show that this combination of intelligent abstraction and adaptive simulation results in a versatile world model capable of producing high quality simulations across a wide range of dynamic scenarios.
FOCUS - Multi-View Foot Reconstruction From Synthetically Trained Dense Correspondences
Feb 10, 2025



Surface reconstruction from multiple, calibrated images is a challenging task - often requiring a large number of collected images with significant overlap. We look at the specific case of human foot reconstruction. As with previous successful foot reconstruction work, we seek to extract rich per-pixel geometry cues from multi-view RGB images, and fuse these into a final 3D object. Our method, FOCUS, tackles this problem with 3 main contributions: (i) SynFoot2, an extension of an existing synthetic foot dataset to include a new data type: dense correspondence with the parameterized foot model FIND; (ii) an uncertainty-aware dense correspondence predictor trained on our synthetic dataset; (iii) two methods for reconstructing a 3D surface from dense correspondence predictions: one inspired by Structure-from-Motion, and one optimization-based using the FIND model. We show that our reconstruction achieves state-of-the-art reconstruction quality in a few-view setting, performing comparably to state-of-the-art when many views are available, and runs substantially faster. We release our synthetic dataset to the research community. Code is available at: https://github.com/OllieBoyne/FOCUS
LUCES-MV: A Multi-View Dataset for Near-Field Point Light Source Photometric Stereo
Dec 21, 2024The biggest improvements in Photometric Stereo (PS) field has recently come from adoption of differentiable volumetric rendering techniques such as NeRF or Neural SDF achieving impressive reconstruction error of 0.2mm on DiLiGenT-MV benchmark. However, while there are sizeable datasets for environment lit objects such as Digital Twin Catalogue (DTS), there are only several small Photometric Stereo datasets which often lack challenging objects (simple, smooth, untextured) and practical, small form factor (near-field) light setup. To address this, we propose LUCES-MV, the first real-world, multi-view dataset designed for near-field point light source photometric stereo. Our dataset includes 15 objects with diverse materials, each imaged under varying light conditions from an array of 15 LEDs positioned 30 to 40 centimeters from the camera center. To facilitate transparent end-to-end evaluation, our dataset provides not only ground truth normals and ground truth object meshes and poses but also light and camera calibration images. We evaluate state-of-the-art near-field photometric stereo algorithms, highlighting their strengths and limitations across different material and shape complexities. LUCES-MV dataset offers an important benchmark for developing more robust, accurate and scalable real-world Photometric Stereo based 3D reconstruction methods.
NPLMV-PS: Neural Point-Light Multi-View Photometric Stereo
May 20, 2024


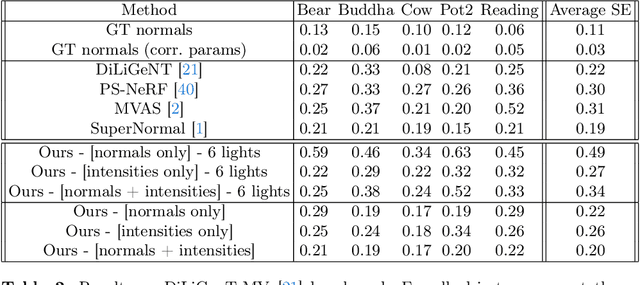
In this work we present a novel multi-view photometric stereo (PS) method. Like many works in 3D reconstruction we are leveraging neural shape representations and learnt renderers. However, our work differs from the state-of-the-art multi-view PS methods such as PS-NeRF or SuperNormal we explicity leverage per-pixel intensity renderings rather than relying mainly on estimated normals. We model point light attenuation and explicitly raytrace cast shadows in order to best approximate each points incoming radiance. This is used as input to a fully neural material renderer that uses minimal prior assumptions and it is jointly optimised with the surface. Finally, estimated normal and segmentation maps can also incorporated in order to maximise the surface accuracy. Our method is among the first to outperform the classical approach of DiLiGenT-MV and achieves average 0.2mm Chamfer distance for objects imaged at approx 1.5m distance away with approximate 400x400 resolution. Moreover, we show robustness to poor normals in low light count scenario, achieving 0.27mm Chamfer distance when pixel rendering is used instead of estimated normals.
VRS-NeRF: Visual Relocalization with Sparse Neural Radiance Field
Apr 14, 2024



Visual relocalization is a key technique to autonomous driving, robotics, and virtual/augmented reality. After decades of explorations, absolute pose regression (APR), scene coordinate regression (SCR), and hierarchical methods (HMs) have become the most popular frameworks. However, in spite of high efficiency, APRs and SCRs have limited accuracy especially in large-scale outdoor scenes; HMs are accurate but need to store a large number of 2D descriptors for matching, resulting in poor efficiency. In this paper, we propose an efficient and accurate framework, called VRS-NeRF, for visual relocalization with sparse neural radiance field. Precisely, we introduce an explicit geometric map (EGM) for 3D map representation and an implicit learning map (ILM) for sparse patches rendering. In this localization process, EGP provides priors of spare 2D points and ILM utilizes these sparse points to render patches with sparse NeRFs for matching. This allows us to discard a large number of 2D descriptors so as to reduce the map size. Moreover, rendering patches only for useful points rather than all pixels in the whole image reduces the rendering time significantly. This framework inherits the accuracy of HMs and discards their low efficiency. Experiments on 7Scenes, CambridgeLandmarks, and Aachen datasets show that our method gives much better accuracy than APRs and SCRs, and close performance to HMs but is much more efficient.
PRAM: Place Recognition Anywhere Model for Efficient Visual Localization
Apr 11, 2024



Humans localize themselves efficiently in known environments by first recognizing landmarks defined on certain objects and their spatial relationships, and then verifying the location by aligning detailed structures of recognized objects with those in the memory. Inspired by this, we propose the place recognition anywhere model (PRAM) to perform visual localization as efficiently as humans do. PRAM consists of two main components - recognition and registration. In detail, first of all, a self-supervised map-centric landmark definition strategy is adopted, making places in either indoor or outdoor scenes act as unique landmarks. Then, sparse keypoints extracted from images, are utilized as the input to a transformer-based deep neural network for landmark recognition; these keypoints enable PRAM to recognize hundreds of landmarks with high time and memory efficiency. Keypoints along with recognized landmark labels are further used for registration between query images and the 3D landmark map. Different from previous hierarchical methods, PRAM discards global and local descriptors, and reduces over 90% storage. Since PRAM utilizes recognition and landmark-wise verification to replace global reference search and exhaustive matching respectively, it runs 2.4 times faster than prior state-of-the-art approaches. Moreover, PRAM opens new directions for visual localization including multi-modality localization, map-centric feature learning, and hierarchical scene coordinate regression.
ReCoRe: Regularized Contrastive Representation Learning of World Model
Dec 14, 2023


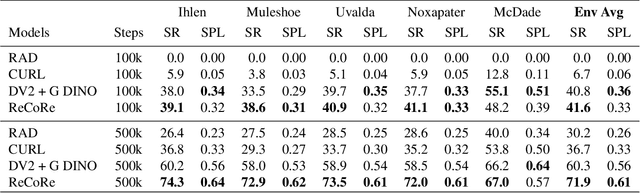
While recent model-free Reinforcement Learning (RL) methods have demonstrated human-level effectiveness in gaming environments, their success in everyday tasks like visual navigation has been limited, particularly under significant appearance variations. This limitation arises from (i) poor sample efficiency and (ii) over-fitting to training scenarios. To address these challenges, we present a world model that learns invariant features using (i) contrastive unsupervised learning and (ii) an intervention-invariant regularizer. Learning an explicit representation of the world dynamics i.e. a world model, improves sample efficiency while contrastive learning implicitly enforces learning of invariant features, which improves generalization. However, the naive integration of contrastive loss to world models fails due to a lack of supervisory signals to the visual encoder, as world-model-based RL methods independently optimize representation learning and agent policy. To overcome this issue, we propose an intervention-invariant regularizer in the form of an auxiliary task such as depth prediction, image denoising, etc., that explicitly enforces invariance to style-interventions. Our method outperforms current state-of-the-art model-based and model-free RL methods and significantly on out-of-distribution point navigation task evaluated on the iGibson benchmark. We further demonstrate that our approach, with only visual observations, outperforms recent language-guided foundation models for point navigation, which is essential for deployment on robots with limited computation capabilities. Finally, we demonstrate that our proposed model excels at the sim-to-real transfer of its perception module on Gibson benchmark.
LanGWM: Language Grounded World Model
Nov 29, 2023Recent advances in deep reinforcement learning have showcased its potential in tackling complex tasks. However, experiments on visual control tasks have revealed that state-of-the-art reinforcement learning models struggle with out-of-distribution generalization. Conversely, expressing higher-level concepts and global contexts is relatively easy using language. Building upon recent success of the large language models, our main objective is to improve the state abstraction technique in reinforcement learning by leveraging language for robust action selection. Specifically, we focus on learning language-grounded visual features to enhance the world model learning, a model-based reinforcement learning technique. To enforce our hypothesis explicitly, we mask out the bounding boxes of a few objects in the image observation and provide the text prompt as descriptions for these masked objects. Subsequently, we predict the masked objects along with the surrounding regions as pixel reconstruction, similar to the transformer-based masked autoencoder approach. Our proposed LanGWM: Language Grounded World Model achieves state-of-the-art performance in out-of-distribution test at the 100K interaction steps benchmarks of iGibson point navigation tasks. Furthermore, our proposed technique of explicit language-grounded visual representation learning has the potential to improve models for human-robot interaction because our extracted visual features are language grounded.
A Neural Height-Map Approach for the Binocular Photometric Stereo Problem
Nov 10, 2023
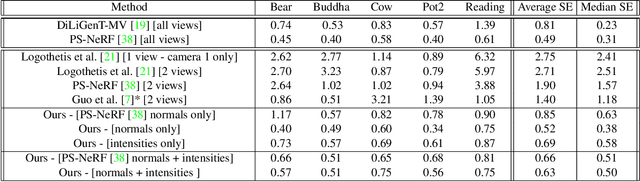
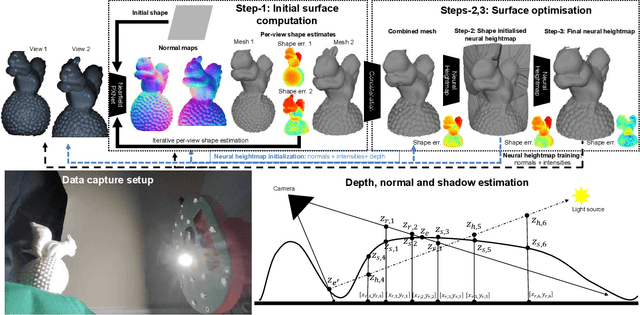
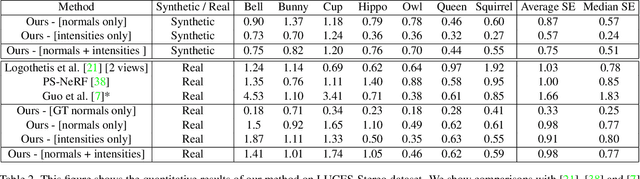
In this work we propose a novel, highly practical, binocular photometric stereo (PS) framework, which has same acquisition speed as single view PS, however significantly improves the quality of the estimated geometry. As in recent neural multi-view shape estimation frameworks such as NeRF, SIREN and inverse graphics approaches to multi-view photometric stereo (e.g. PS-NeRF) we formulate shape estimation task as learning of a differentiable surface and texture representation by minimising surface normal discrepancy for normals estimated from multiple varying light images for two views as well as discrepancy between rendered surface intensity and observed images. Our method differs from typical multi-view shape estimation approaches in two key ways. First, our surface is represented not as a volume but as a neural heightmap where heights of points on a surface are computed by a deep neural network. Second, instead of predicting an average intensity as PS-NeRF or introducing lambertian material assumptions as Guo et al., we use a learnt BRDF and perform near-field per point intensity rendering. Our method achieves the state-of-the-art performance on the DiLiGenT-MV dataset adapted to binocular stereo setup as well as a new binocular photometric stereo dataset - LUCES-ST.
FOUND: Foot Optimization with Uncertain Normals for Surface Deformation Using Synthetic Data
Oct 27, 2023



Surface reconstruction from multi-view images is a challenging task, with solutions often requiring a large number of sampled images with high overlap. We seek to develop a method for few-view reconstruction, for the case of the human foot. To solve this task, we must extract rich geometric cues from RGB images, before carefully fusing them into a final 3D object. Our FOUND approach tackles this, with 4 main contributions: (i) SynFoot, a synthetic dataset of 50,000 photorealistic foot images, paired with ground truth surface normals and keypoints; (ii) an uncertainty-aware surface normal predictor trained on our synthetic dataset; (iii) an optimization scheme for fitting a generative foot model to a series of images; and (iv) a benchmark dataset of calibrated images and high resolution ground truth geometry. We show that our normal predictor outperforms all off-the-shelf equivalents significantly on real images, and our optimization scheme outperforms state-of-the-art photogrammetry pipelines, especially for a few-view setting. We release our synthetic dataset and baseline 3D scans to the research community.