 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Multi-Concept Image Editing
Feb 24, 2026Editing images with diffusion models without training remains challenging. While recent optimisation-based methods achieve strong zero-shot edits from text, they struggle to preserve identity or capture details that language alone cannot express. Many visual concepts such as facial structure, material texture, or object geometry are impossible to express purely through text prompts alone. To address this gap, we introduce a training-free framework for concept-based image editing, which unifies Optimised DDS with LoRA-driven concept composition, where the training data of the LoRA represent the concept. Our approach enables combining and controlling multiple visual concepts directly within the diffusion process, integrating semantic guidance from text with low-level cues from pretrained concept adapters. We further refine DDS for stability and controllability through ordered timesteps, regularisation, and negative-prompt guidance. Quantitative and qualitative results demonstrate consistent improvements over existing training-free diffusion editing methods on InstructPix2Pix and ComposLoRA benchmarks. Code will be made publicly available.
LUCES-MV: A Multi-View Dataset for Near-Field Point Light Source Photometric Stereo
Dec 21, 2024The biggest improvements in Photometric Stereo (PS) field has recently come from adoption of differentiable volumetric rendering techniques such as NeRF or Neural SDF achieving impressive reconstruction error of 0.2mm on DiLiGenT-MV benchmark. However, while there are sizeable datasets for environment lit objects such as Digital Twin Catalogue (DTS), there are only several small Photometric Stereo datasets which often lack challenging objects (simple, smooth, untextured) and practical, small form factor (near-field) light setup. To address this, we propose LUCES-MV, the first real-world, multi-view dataset designed for near-field point light source photometric stereo. Our dataset includes 15 objects with diverse materials, each imaged under varying light conditions from an array of 15 LEDs positioned 30 to 40 centimeters from the camera center. To facilitate transparent end-to-end evaluation, our dataset provides not only ground truth normals and ground truth object meshes and poses but also light and camera calibration images. We evaluate state-of-the-art near-field photometric stereo algorithms, highlighting their strengths and limitations across different material and shape complexities. LUCES-MV dataset offers an important benchmark for developing more robust, accurate and scalable real-world Photometric Stereo based 3D reconstruction methods.
DiaLoc: An Iterative Approach to Embodied Dialog Localization
Mar 11, 2024Multimodal learning has advanced the performance for many vision-language tasks. However, most existing works in embodied dialog research focus on navigation and leave the localization task understudied. The few existing dialog-based localization approaches assume the availability of entire dialog prior to localizaiton, which is impractical for deployed dialog-based localization. In this paper, we propose DiaLoc, a new dialog-based localization framework which aligns with a real human operator behavior. Specifically, we produce an iterative refinement of location predictions which can visualize current pose believes after each dialog turn. DiaLoc effectively utilizes the multimodal data for multi-shot localization, where a fusion encoder fuses vision and dialog information iteratively. We achieve state-of-the-art results on embodied dialog-based localization task, in single-shot (+7.08% in Acc5@valUnseen) and multi-shot settings (+10.85% in Acc5@valUnseen). DiaLoc narrows the gap between simulation and real-world applications, opening doors for future research on collaborative localization and navigation.
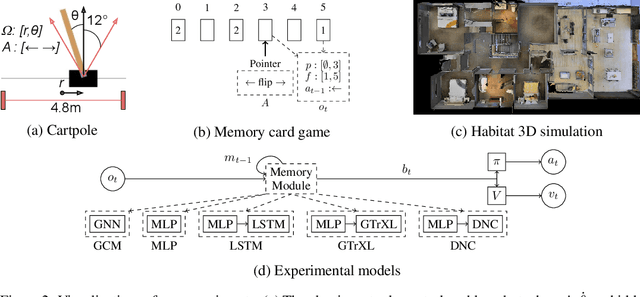
Revisiting Recurrent Reinforcement Learning with Memory Monoids
Feb 15, 2024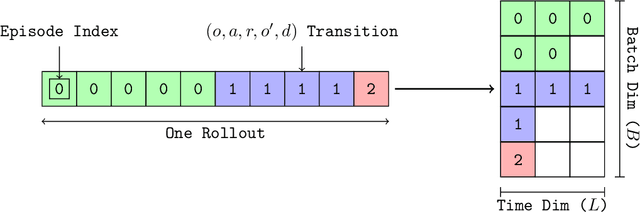
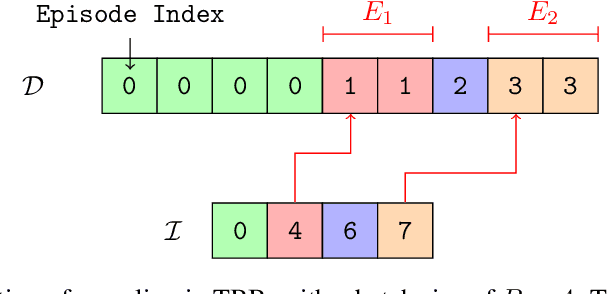
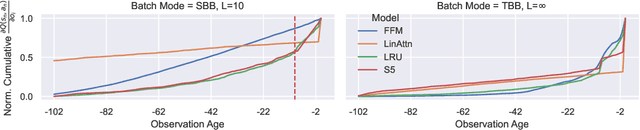

In RL, memory models such as RNNs and transformers address Partially Observable Markov Decision Processes (POMDPs) by mapping trajectories to latent Markov states. Neither model scales particularly well to long sequences, especially compared to an emerging class of memory models sometimes called linear recurrent models. We discover that the recurrent update of these models is a monoid, leading us to formally define a novel memory monoid framework. We revisit the traditional approach to batching in recurrent RL, highlighting both theoretical and empirical deficiencies. Leveraging the properties of memory monoids, we propose a new batching method that improves sample efficiency, increases the return, and simplifies the implementation of recurrent loss functions in RL.
ReCoRe: Regularized Contrastive Representation Learning of World Model
Dec 14, 2023


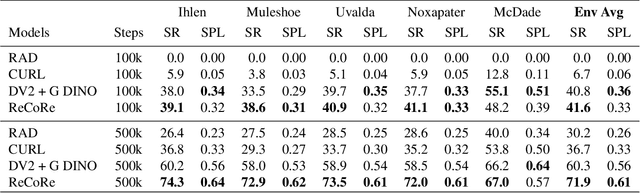
While recent model-free Reinforcement Learning (RL) methods have demonstrated human-level effectiveness in gaming environments, their success in everyday tasks like visual navigation has been limited, particularly under significant appearance variations. This limitation arises from (i) poor sample efficiency and (ii) over-fitting to training scenarios. To address these challenges, we present a world model that learns invariant features using (i) contrastive unsupervised learning and (ii) an intervention-invariant regularizer. Learning an explicit representation of the world dynamics i.e. a world model, improves sample efficiency while contrastive learning implicitly enforces learning of invariant features, which improves generalization. However, the naive integration of contrastive loss to world models fails due to a lack of supervisory signals to the visual encoder, as world-model-based RL methods independently optimize representation learning and agent policy. To overcome this issue, we propose an intervention-invariant regularizer in the form of an auxiliary task such as depth prediction, image denoising, etc., that explicitly enforces invariance to style-interventions. Our method outperforms current state-of-the-art model-based and model-free RL methods and significantly on out-of-distribution point navigation task evaluated on the iGibson benchmark. We further demonstrate that our approach, with only visual observations, outperforms recent language-guided foundation models for point navigation, which is essential for deployment on robots with limited computation capabilities. Finally, we demonstrate that our proposed model excels at the sim-to-real transfer of its perception module on Gibson benchmark.
Reinforcement Learning with Fast and Forgetful Memory
Oct 06, 2023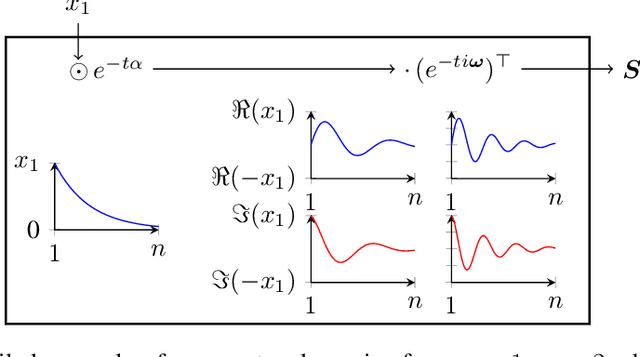
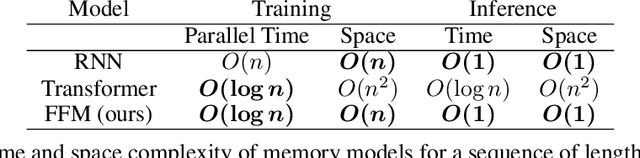
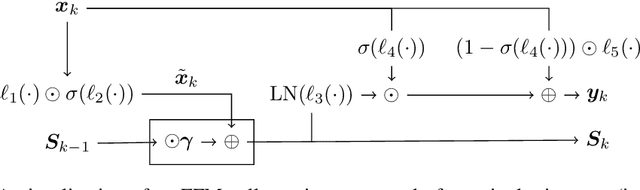
Nearly all real world tasks are inherently partially observable, necessitating the use of memory in Reinforcement Learning (RL). Most model-free approaches summarize the trajectory into a latent Markov state using memory models borrowed from Supervised Learning (SL), even though RL tends to exhibit different training and efficiency characteristics. Addressing this discrepancy, we introduce Fast and Forgetful Memory, an algorithm-agnostic memory model designed specifically for RL. Our approach constrains the model search space via strong structural priors inspired by computational psychology. It is a drop-in replacement for recurrent neural networks (RNNs) in recurrent RL algorithms, achieving greater reward than RNNs across various recurrent benchmarks and algorithms without changing any hyperparameters. Moreover, Fast and Forgetful Memory exhibits training speeds two orders of magnitude faster than RNNs, attributed to its logarithmic time and linear space complexity. Our implementation is available at https://github.com/proroklab/ffm.
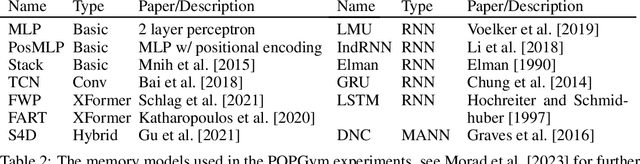
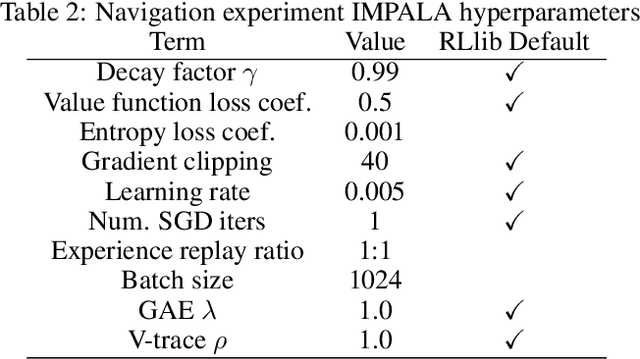
POPGym: Benchmarking Partially Observable Reinforcement Learning
Mar 03, 2023Real world applications of Reinforcement Learning (RL) are often partially observable, thus requiring memory. Despite this, partial observability is still largely ignored by contemporary RL benchmarks and libraries. We introduce Partially Observable Process Gym (POPGym), a two-part library containing (1) a diverse collection of 15 partially observable environments, each with multiple difficulties and (2) implementations of 13 memory model baselines -- the most in a single RL library. Existing partially observable benchmarks tend to fixate on 3D visual navigation, which is computationally expensive and only one type of POMDP. In contrast, POPGym environments are diverse, produce smaller observations, use less memory, and often converge within two hours of training on a consumer-grade GPU. We implement our high-level memory API and memory baselines on top of the popular RLlib framework, providing plug-and-play compatibility with various training algorithms, exploration strategies, and distributed training paradigms. Using POPGym, we execute the largest comparison across RL memory models to date. POPGym is available at https://github.com/proroklab/popgym.
Self-Supervised Consistent Quantization for Fully Unsupervised Image Retrieval
Jun 20, 2022
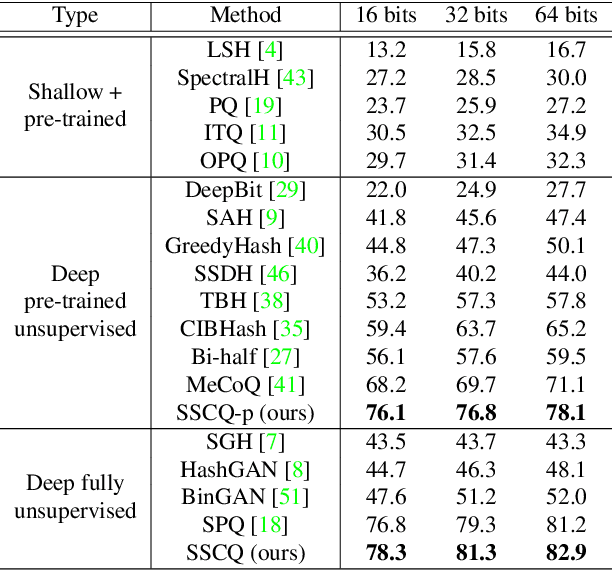
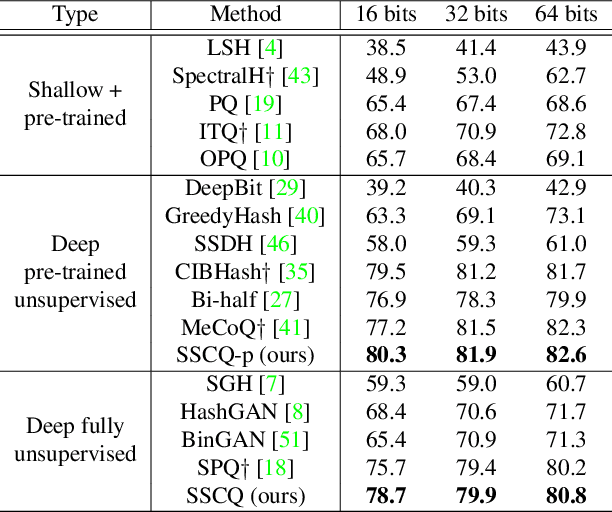
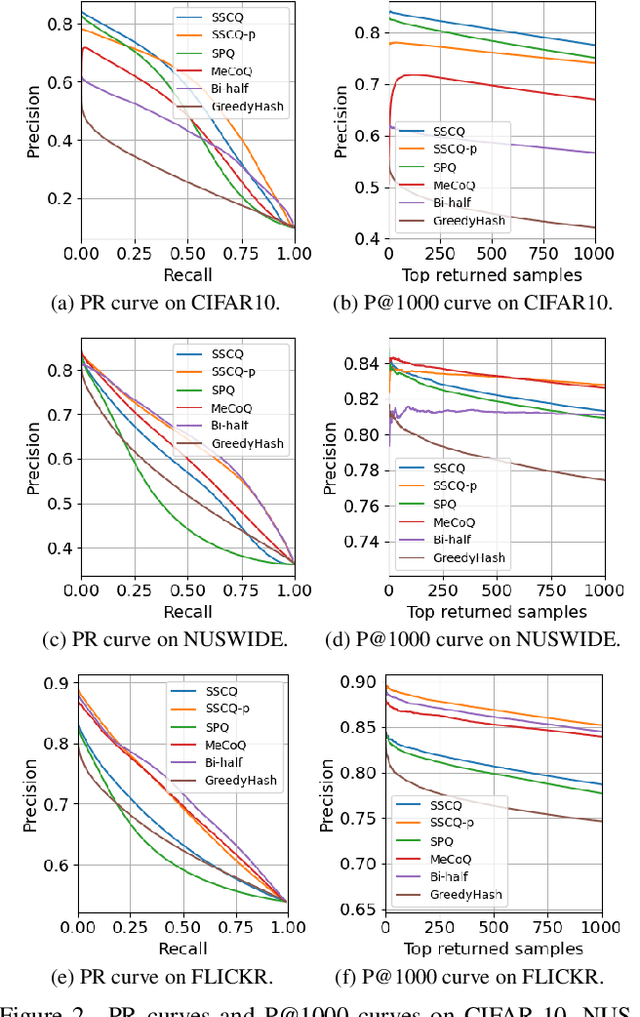
Unsupervised image retrieval aims to learn an efficient retrieval system without expensive data annotations, but most existing methods rely heavily on handcrafted feature descriptors or pre-trained feature extractors. To minimize human supervision, recent advance proposes deep fully unsupervised image retrieval aiming at training a deep model from scratch to jointly optimize visual features and quantization codes. However, existing approach mainly focuses on instance contrastive learning without considering underlying semantic structure information, resulting in sub-optimal performance. In this work, we propose a novel self-supervised consistent quantization approach to deep fully unsupervised image retrieval, which consists of part consistent quantization and global consistent quantization. In part consistent quantization, we devise part neighbor semantic consistency learning with codeword diversity regularization. This allows to discover underlying neighbor structure information of sub-quantized representations as self-supervision. In global consistent quantization, we employ contrastive learning for both embedding and quantized representations and fuses these representations for consistent contrastive regularization between instances. This can make up for the loss of useful representation information during quantization and regularize consistency between instances. With a unified learning objective of part and global consistent quantization, our approach exploits richer self-supervision cues to facilitate model learning. Extensive experiments on three benchmark datasets show the superiority of our approach over the state-of-the-art methods.
Graph Convolutional Memory for Deep Reinforcement Learning
Jun 27, 2021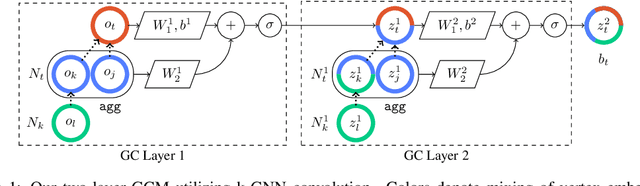
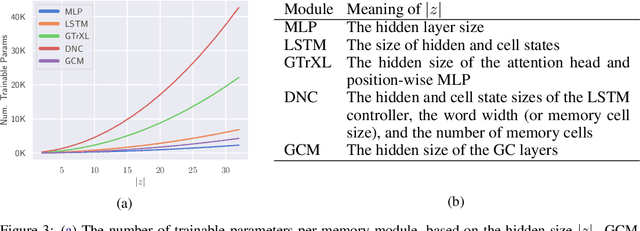
Solving partially-observable Markov decision processes (POMDPs) is critical when applying deep reinforcement learning (DRL) to real-world robotics problems, where agents have an incomplete view of the world. We present graph convolutional memory (GCM) for solving POMDPs using deep reinforcement learning. Unlike recurrent neural networks (RNNs) or transformers, GCM embeds domain-specific priors into the memory recall process via a knowledge graph. By encapsulating priors in the graph, GCM adapts to specific tasks but remains applicable to any DRL task. Using graph convolutions, GCM extracts hierarchical graph features, analogous to image features in a convolutional neural network (CNN). We show GCM outperforms long short-term memory (LSTM), gated transformers for reinforcement learning (GTrXL), and differentiable neural computers (DNCs) on control, long-term non-sequential recall, and 3D navigation tasks while using significantly fewer parameters.
Embodied Visual Navigation with Automatic Curriculum Learning in Real Environments
Sep 11, 2020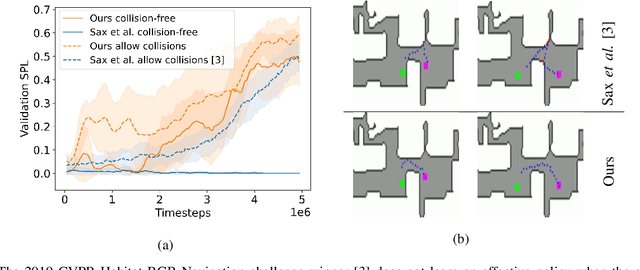
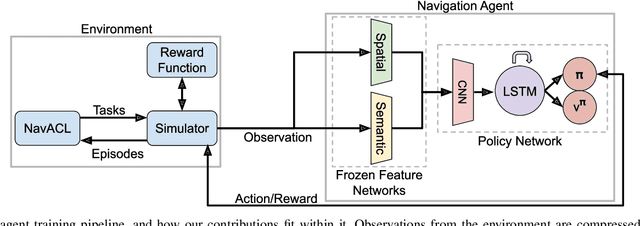
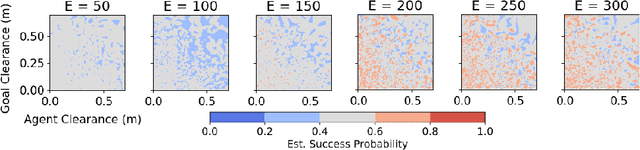
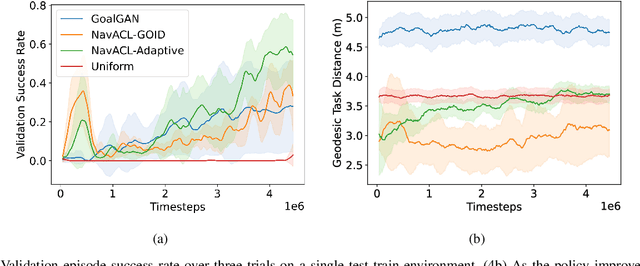
We present NavACL, a method of automatic curriculum learning tailored to the navigation task. NavACL is simple to train and efficiently selects relevant tasks using geometric features. In our experiments, deep reinforcement learning agents trained using NavACL in collision-free environments significantly outperform state-of-the-art agents trained with uniform sampling -- the current standard. Furthermore, our agents are able to navigate through unknown cluttered indoor environments to semantically-specified targets using only RGB images. Collision avoidance policies and frozen feature networks support transfer to unseen real-world environments, without any modification or retraining requirements. We evaluate our policies in simulation, and in the real world on a ground robot and a quadrotor drone. Videos of real-world results are available in the supplementary material