 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Consistent Quantization for Fully Unsupervised Image Retrieval
Paper and Code
Jun 20, 2022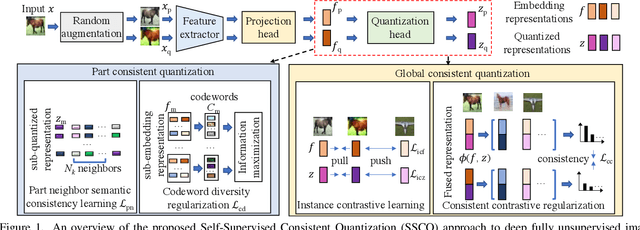
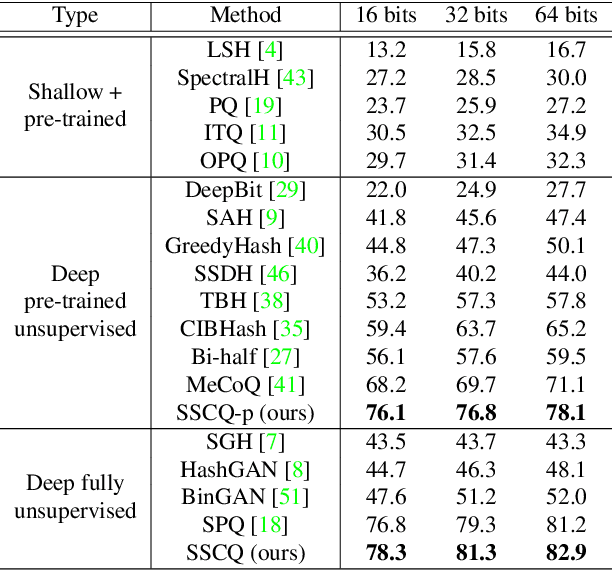
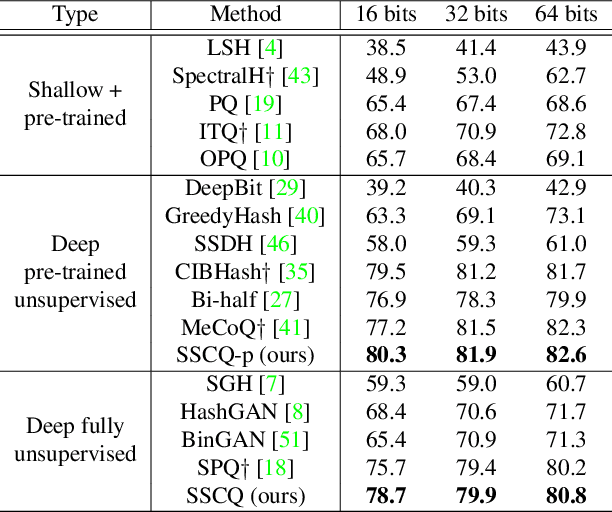
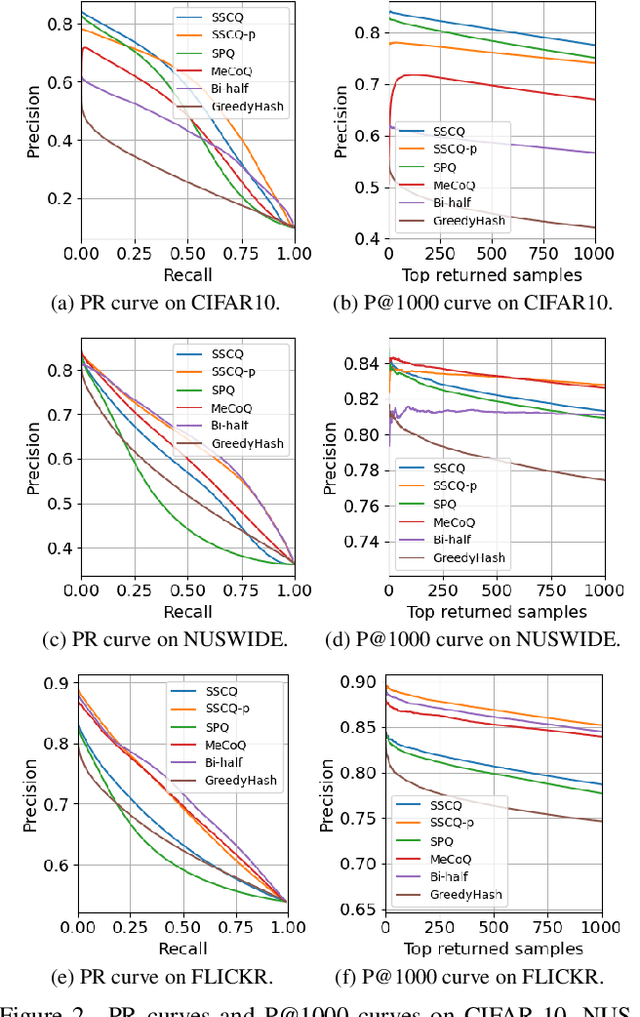
Unsupervised image retrieval aims to learn an efficient retrieval system without expensive data annotations, but most existing methods rely heavily on handcrafted feature descriptors or pre-trained feature extractors. To minimize human supervision, recent advance proposes deep fully unsupervised image retrieval aiming at training a deep model from scratch to jointly optimize visual features and quantization codes. However, existing approach mainly focuses on instance contrastive learning without considering underlying semantic structure information, resulting in sub-optimal performance. In this work, we propose a novel self-supervised consistent quantization approach to deep fully unsupervised image retrieval, which consists of part consistent quantization and global consistent quantization. In part consistent quantization, we devise part neighbor semantic consistency learning with codeword diversity regularization. This allows to discover underlying neighbor structure information of sub-quantized representations as self-supervision. In global consistent quantization, we employ contrastive learning for both embedding and quantized representations and fuses these representations for consistent contrastive regularization between instances. This can make up for the loss of useful representation information during quantization and regularize consistency between instances. With a unified learning objective of part and global consistent quantization, our approach exploits richer self-supervision cues to facilitate model learning. Extensive experiments on three benchmark datasets show the superiority of our approach over the state-of-the-art methods.