 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage and Geometry Grounded Sparse Voxel Representations for Holistic Scene Understanding
Feb 17, 2026Existing 3D open-vocabulary scene understanding methods mostly emphasize distilling language features from 2D foundation models into 3D feature fields, but largely overlook the synergy among scene appearance, semantics, and geometry. As a result, scene understanding often deviates from the underlying geometric structure of scenes and becomes decoupled from the reconstruction process. In this work, we propose a novel approach that leverages language and geometry grounded sparse voxel representations to comprehensively model appearance, semantics, and geometry within a unified framework. Specifically, we use 3D sparse voxels as primitives and employ an appearance field, a density field, a feature field, and a confidence field to holistically represent a 3D scene. To promote synergy among the appearance, density, and feature fields, we construct a feature modulation module and distill language features from a 2D foundation model into our 3D scene model. In addition, we integrate geometric distillation into feature field distillation to transfer geometric knowledge from a geometry foundation model to our 3D scene representations via depth correlation regularization and pattern consistency regularization. These components work together to synergistically model the appearance, semantics, and geometry of the 3D scene within a unified framework. Extensive experiments demonstrate that our approach achieves superior overall performance compared with state-of-the-art methods in holistic scene understanding and reconstruction.
Nighttime Autonomous Driving Scene Reconstruction with Physically-Based Gaussian Splatting
Feb 14, 2026This paper focuses on scene reconstruction under nighttime conditions in autonomous driving simulation. Recent methods based on Neural Radiance Fields (NeRFs) and 3D Gaussian Splatting (3DGS) have achieved photorealistic modeling in autonomous driving scene reconstruction, but they primarily focus on normal-light conditions. Low-light driving scenes are more challenging to model due to their complex lighting and appearance conditions, which often causes performance degradation of existing methods. To address this problem, this work presents a novel approach that integrates physically based rendering into 3DGS to enhance nighttime scene reconstruction for autonomous driving. Specifically, our approach integrates physically based rendering into composite scene Gaussian representations and jointly optimizes Bidirectional Reflectance Distribution Function (BRDF) based material properties. We explicitly model diffuse components through a global illumination module and specular components by anisotropic spherical Gaussians. As a result, our approach improves reconstruction quality for outdoor nighttime driving scenes, while maintaining real-time rendering. Extensive experiments across diverse nighttime scenarios on two real-world autonomous driving datasets, including nuScenes and Waymo, demonstrate that our approach outperforms the state-of-the-art methods both quantitatively and qualitatively.
Spatial4D-Bench: A Versatile 4D Spatial Intelligence Benchmark
Dec 31, 20254D spatial intelligence involves perceiving and processing how objects move or change over time. Humans naturally possess 4D spatial intelligence, supporting a broad spectrum of spatial reasoning abilities. To what extent can Multimodal Large Language Models (MLLMs) achieve human-level 4D spatial intelligence? In this work, we present Spatial4D-Bench, a versatile 4D spatial intelligence benchmark designed to comprehensively assess the 4D spatial reasoning abilities of MLLMs. Unlike existing spatial intelligence benchmarks that are often small-scale or limited in diversity, Spatial4D-Bench provides a large-scale, multi-task evaluation benchmark consisting of ~40,000 question-answer pairs covering 18 well-defined tasks. We systematically organize these tasks into six cognitive categories: object understanding, scene understanding, spatial relationship understanding, spatiotemporal relationship understanding, spatial reasoning and spatiotemporal reasoning. Spatial4D-Bench thereby offers a structured and comprehensive benchmark for evaluating the spatial cognition abilities of MLLMs, covering a broad spectrum of tasks that parallel the versatility of human spatial intelligence. We benchmark various state-of-the-art open-source and proprietary MLLMs on Spatial4D-Bench and reveal their substantial limitations in a wide variety of 4D spatial reasoning aspects, such as route plan, action recognition, and physical plausibility reasoning. We hope that the findings provided in this work offer valuable insights to the community and that our benchmark can facilitate the development of more capable MLLMs toward human-level 4D spatial intelligence. More resources can be found on our project page.
MoVieDrive: Multi-Modal Multi-View Urban Scene Video Generation
Aug 20, 2025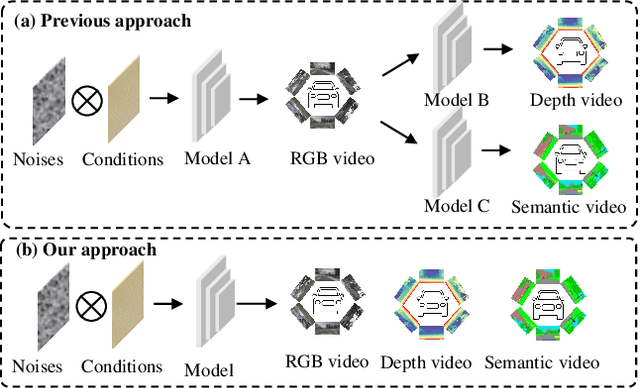
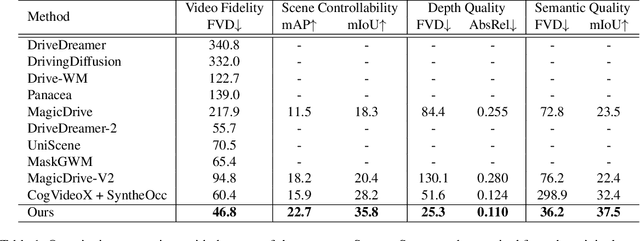
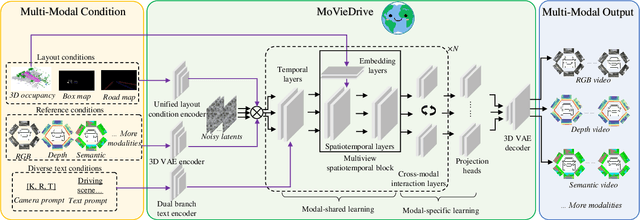
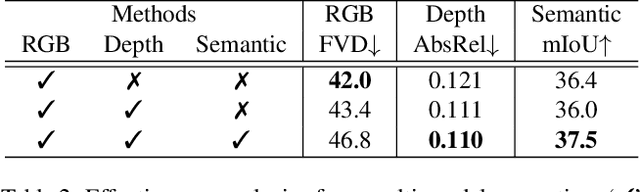
Video generation has recently shown superiority in urban scene synthesis for autonomous driving. Existing video generation approaches to autonomous driving primarily focus on RGB video generation and lack the ability to support multi-modal video generation. However, multi-modal data, such as depth maps and semantic maps, are crucial for holistic urban scene understanding in autonomous driving. Although it is feasible to use multiple models to generate different modalities, this increases the difficulty of model deployment and does not leverage complementary cues for multi-modal data generation. To address this problem, in this work, we propose a novel multi-modal multi-view video generation approach to autonomous driving. Specifically, we construct a unified diffusion transformer model composed of modal-shared components and modal-specific components. Then, we leverage diverse conditioning inputs to encode controllable scene structure and content cues into the unified diffusion model for multi-modal multi-view video generation. In this way, our approach is capable of generating multi-modal multi-view driving scene videos in a unified framework. Our experiments on the challenging real-world autonomous driving dataset, nuScenes, show that our approach can generate multi-modal multi-view urban scene videos with high fidelity and controllability, surpassing the state-of-the-art methods.
UniGaussian: Driving Scene Reconstruction from Multiple Camera Models via Unified Gaussian Representations
Nov 22, 2024



Urban scene reconstruction is crucial for real-world autonomous driving simulators. Although existing methods have achieved photorealistic reconstruction, they mostly focus on pinhole cameras and neglect fisheye cameras. In fact, how to effectively simulate fisheye cameras in driving scene remains an unsolved problem. In this work, we propose UniGaussian, a novel approach that learns a unified 3D Gaussian representation from multiple camera models for urban scene reconstruction in autonomous driving. Our contributions are two-fold. First, we propose a new differentiable rendering method that distorts 3D Gaussians using a series of affine transformations tailored to fisheye camera models. This addresses the compatibility issue of 3D Gaussian splatting with fisheye cameras, which is hindered by light ray distortion caused by lenses or mirrors. Besides, our method maintains real-time rendering while ensuring differentiability. Second, built on the differentiable rendering method, we design a new framework that learns a unified Gaussian representation from multiple camera models. By applying affine transformations to adapt different camera models and regularizing the shared Gaussians with supervision from different modalities, our framework learns a unified 3D Gaussian representation with input data from multiple sources and achieves holistic driving scene understanding. As a result, our approach models multiple sensors (pinhole and fisheye cameras) and modalities (depth, semantic, normal and LiDAR point clouds). Our experiments show that our method achieves superior rendering quality and fast rendering speed for driving scene simulation.
VQA-Diff: Exploiting VQA and Diffusion for Zero-Shot Image-to-3D Vehicle Asset Generation in Autonomous Driving
Jul 10, 2024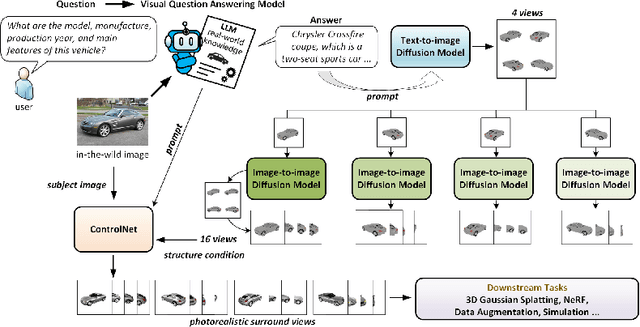
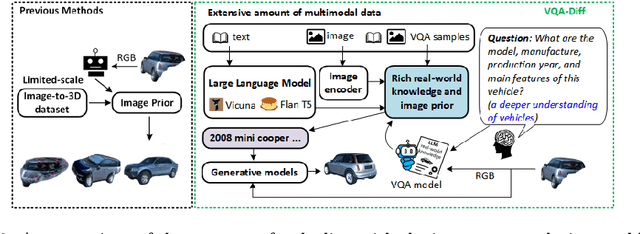
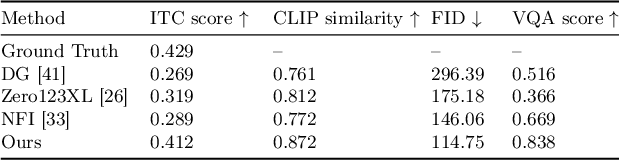
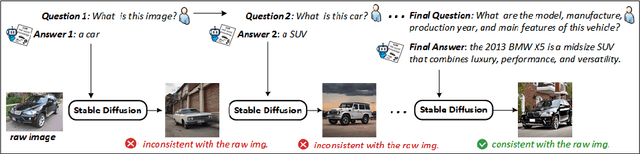
Generating 3D vehicle assets from in-the-wild observations is crucial to autonomous driving. Existing image-to-3D methods cannot well address this problem because they learn generation merely from image RGB information without a deeper understanding of in-the-wild vehicles (such as car models, manufacturers, etc.). This leads to their poor zero-shot prediction capability to handle real-world observations with occlusion or tricky viewing angles. To solve this problem, in this work, we propose VQA-Diff, a novel framework that leverages in-the-wild vehicle images to create photorealistic 3D vehicle assets for autonomous driving. VQA-Diff exploits the real-world knowledge inherited from the Large Language Model in the Visual Question Answering (VQA) model for robust zero-shot prediction and the rich image prior knowledge in the Diffusion model for structure and appearance generation. In particular, we utilize a multi-expert Diffusion Models strategy to generate the structure information and employ a subject-driven structure-controlled generation mechanism to model appearance information. As a result, without the necessity to learn from a large-scale image-to-3D vehicle dataset collected from the real world, VQA-Diff still has a robust zero-shot image-to-novel-view generation ability. We conduct experiments on various datasets, including Pascal 3D+, Waymo, and Objaverse, to demonstrate that VQA-Diff outperforms existing state-of-the-art methods both qualitatively and quantitatively.
Learning Effective NeRFs and SDFs Representations with 3D Generative Adversarial Networks for 3D Object Generation: Technical Report for ICCV 2023 OmniObject3D Challenge
Sep 28, 2023



In this technical report, we present a solution for 3D object generation of ICCV 2023 OmniObject3D Challenge. In recent years, 3D object generation has made great process and achieved promising results, but it remains a challenging task due to the difficulty of generating complex, textured and high-fidelity results. To resolve this problem, we study learning effective NeRFs and SDFs representations with 3D Generative Adversarial Networks (GANs) for 3D object generation. Specifically, inspired by recent works, we use the efficient geometry-aware 3D GANs as the backbone incorporating with label embedding and color mapping, which enables to train the model on different taxonomies simultaneously. Then, through a decoder, we aggregate the resulting features to generate Neural Radiance Fields (NeRFs) based representations for rendering high-fidelity synthetic images. Meanwhile, we optimize Signed Distance Functions (SDFs) to effectively represent objects with 3D meshes. Besides, we observe that this model can be effectively trained with only a few images of each object from a variety of classes, instead of using a great number of images per object or training one model per class. With this pipeline, we can optimize an effective model for 3D object generation. This solution is one of the final top-3-place solutions in the ICCV 2023 OmniObject3D Challenge.
Federated Zero-Shot Learning with Mid-Level Semantic Knowledge Transfer
Aug 29, 2022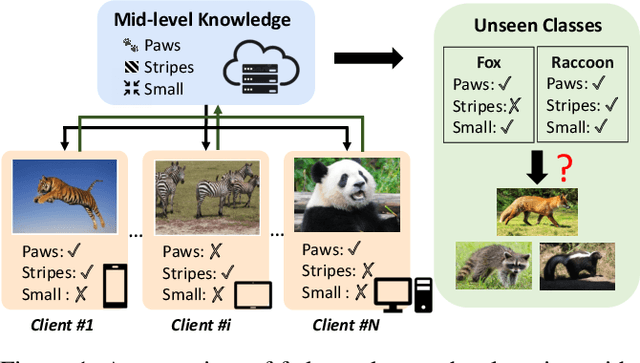
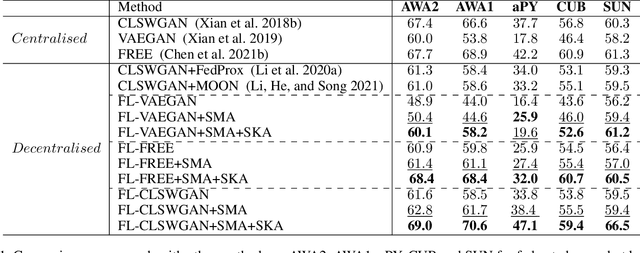
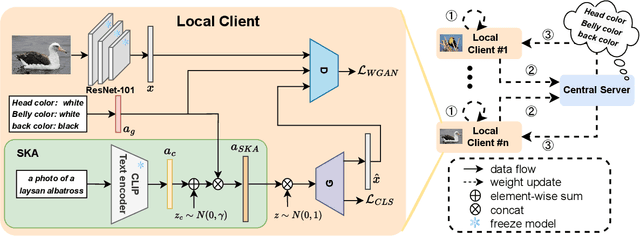
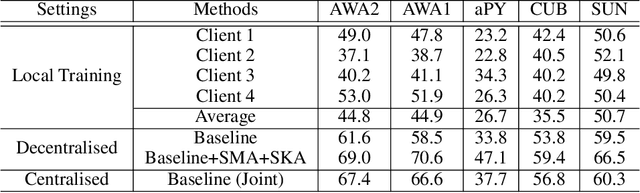
Conventional centralised deep learning paradigms are not feasible when data from different sources cannot be shared due to data privacy or transmission limitation. To resolve this problem, federated learning has been introduced to transfer knowledge across multiple sources (clients) with non-shared data while optimising a globally generalised central model (server). Existing federated learning paradigms mostly focus on transferring holistic high-level knowledge (such as class) across models, which are closely related to specific objects of interest so may suffer from inverse attack. In contrast, in this work, we consider transferring mid-level semantic knowledge (such as attribute) which is not sensitive to specific objects of interest and therefore is more privacy-preserving and scalable. To this end, we formulate a new Federated Zero-Shot Learning (FZSL) paradigm to learn mid-level semantic knowledge at multiple local clients with non-shared local data and cumulatively aggregate a globally generalised central model for deployment. To improve model discriminative ability, we propose to explore semantic knowledge augmentation from external knowledge for enriching the mid-level semantic space in FZSL. Extensive experiments on five zeroshot learning benchmark datasets validate the effectiveness of our approach for optimising a generalisable federated learning model with mid-level semantic knowledge transfer.
Self-Supervised Consistent Quantization for Fully Unsupervised Image Retrieval
Jun 20, 2022
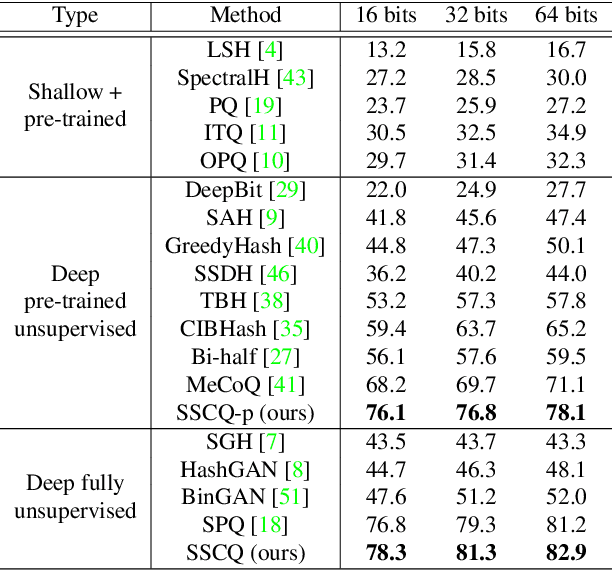
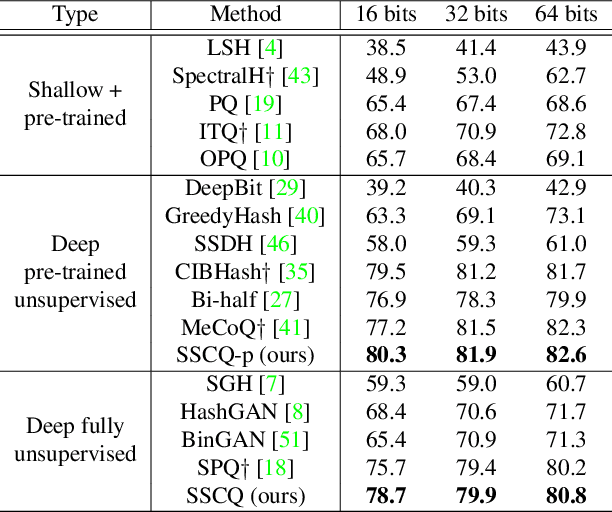
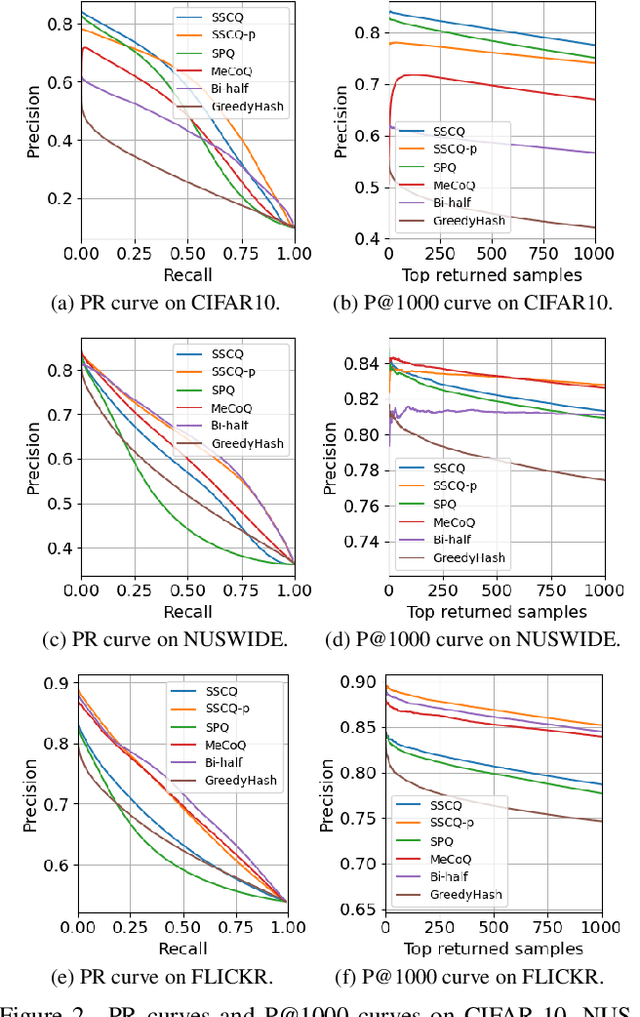
Unsupervised image retrieval aims to learn an efficient retrieval system without expensive data annotations, but most existing methods rely heavily on handcrafted feature descriptors or pre-trained feature extractors. To minimize human supervision, recent advance proposes deep fully unsupervised image retrieval aiming at training a deep model from scratch to jointly optimize visual features and quantization codes. However, existing approach mainly focuses on instance contrastive learning without considering underlying semantic structure information, resulting in sub-optimal performance. In this work, we propose a novel self-supervised consistent quantization approach to deep fully unsupervised image retrieval, which consists of part consistent quantization and global consistent quantization. In part consistent quantization, we devise part neighbor semantic consistency learning with codeword diversity regularization. This allows to discover underlying neighbor structure information of sub-quantized representations as self-supervision. In global consistent quantization, we employ contrastive learning for both embedding and quantized representations and fuses these representations for consistent contrastive regularization between instances. This can make up for the loss of useful representation information during quantization and regularize consistency between instances. With a unified learning objective of part and global consistent quantization, our approach exploits richer self-supervision cues to facilitate model learning. Extensive experiments on three benchmark datasets show the superiority of our approach over the state-of-the-art methods.
Learning Unbiased Transferability for Domain Adaptation by Uncertainty Modeling
Jun 02, 2022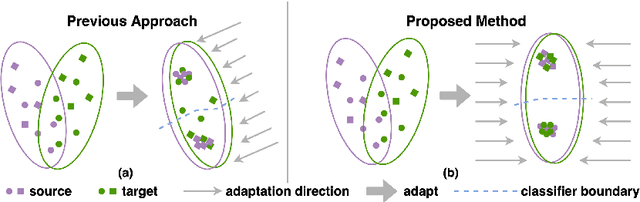
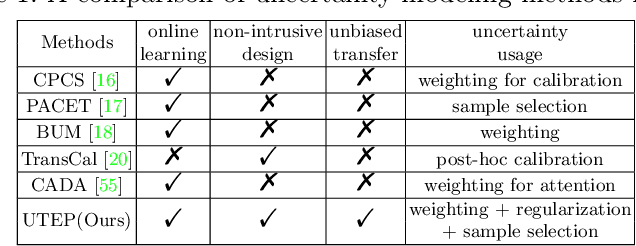
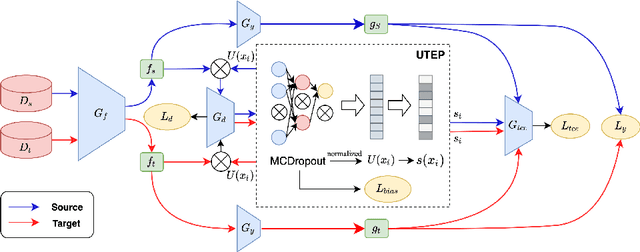
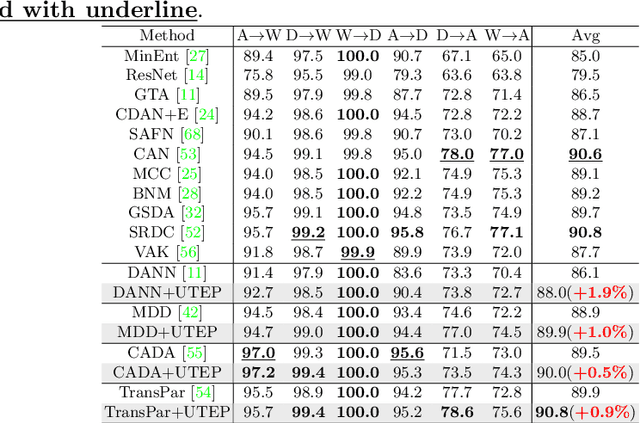
Domain adaptation (DA) aims to transfer knowledge learned from a labeled source domain to an unlabeled or a less labeled but related target domain. Ideally, the source and target distributions should be aligned to each other equally to achieve unbiased knowledge transfer. However, due to the significant imbalance between the amount of annotated data in the source and target domains, usually only the target distribution is aligned to the source domain, leading to adapting unnecessary source specific knowledge to the target domain, i.e., biased domain adaptation. To resolve this problem, in this work, we delve into the transferability estimation problem in domain adaptation and propose a non-intrusive Unbiased Transferability Estimation Plug-in (UTEP) by modeling the uncertainty of a discriminator in adversarial-based DA methods to optimize unbiased transfer. We theoretically analyze the effectiveness of the proposed approach to unbiased transferability learning in DA. Furthermore, to alleviate the impact of imbalanced annotated data, we utilize the estimated uncertainty for pseudo label selection of unlabeled samples in the target domain, which helps achieve better marginal and conditional distribution alignments between domains. Extensive experimental results on a high variety of DA benchmark datasets show that the proposed approach can be readily incorporated into various adversarial-based DA methods, achieving state-of-the-art performance.