 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColor When It Counts: Grayscale-Guided Online Triggering for Always-On Streaming Video Sensing
Mar 23, 2026Always-on sensing is essential for next-generation edge/wearable AI systems, yet continuous high-fidelity RGB video capture remains prohibitively expensive for resource-constrained mobile and edge platforms. We present a new paradigm for efficient streaming video understanding: grayscale-always, color-on-demand. Through preliminary studies, we discover that color is not always necessary. Sparse RGB frames suffice for comparable performance when temporal structure is preserved via continuous grayscale streams. Building on this insight, we propose ColorTrigger, an online training-free trigger that selectively activates color capture based on windowed grayscale affinity analysis. Designed for real-time edge deployment, ColorTrigger uses lightweight quadratic programming to detect chromatic redundancy causally, coupled with credit-budgeted control and dynamic token routing to jointly reduce sensing and inference costs. On streaming video understanding benchmarks, ColorTrigger achieves 91.6% of full-color baseline performance while using only 8.1% RGB frames, demonstrating substantial color redundancy in natural videos and enabling practical always-on video sensing on resource-constrained devices.
Egocentric Co-Pilot: Web-Native Smart-Glasses Agents for Assistive Egocentric AI
Mar 01, 2026What if accessing the web did not require a screen, a stable desk, or even free hands? For people navigating crowded cities, living with low vision, or experiencing cognitive overload, smart glasses coupled with AI agents could turn the web into an always-on assistive layer over daily life. We present Egocentric Co-Pilot, a web-native neuro-symbolic framework that runs on smart glasses and uses a Large Language Model (LLM) to orchestrate a toolbox of perception, reasoning, and web tools. An egocentric reasoning core combines Temporal Chain-of-Thought with Hierarchical Context Compression to support long-horizon question answering and decision support over continuous first-person video, far beyond a single model's context window. Additionally, a lightweight multimodal intent layer maps noisy speech and gaze into structured commands. We further implement and evaluate a cloud-native WebRTC pipeline integrating streaming speech, video, and control messages into a unified channel for smart glasses and browsers. In parallel, we deploy an on-premise WebSocket baseline, exposing concrete trade-offs between local inference and cloud offloading in terms of latency, mobility, and resource use. Experiments on Egolife and HD-EPIC demonstrate competitive or state-of-the-art egocentric QA performance, and a human-in-the-loop study on smart glasses shows higher task completion and user satisfaction than leading commercial baselines. Taken together, these results indicate that web-connected egocentric co-pilots can be a practical path toward more accessible, context-aware assistance in everyday life. By grounding operation in web-native communication primitives and modular, auditable tool use, Egocentric Co-Pilot offers a concrete blueprint for assistive, always-on web agents that support education, accessibility, and social inclusion for people who may benefit most from contextual, egocentric AI.
EgoGraph: Temporal Knowledge Graph for Egocentric Video Understanding
Feb 27, 2026Ultra-long egocentric videos spanning multiple days present significant challenges for video understanding. Existing approaches still rely on fragmented local processing and limited temporal modeling, restricting their ability to reason over such extended sequences. To address these limitations, we introduce EgoGraph, a training-free and dynamic knowledge-graph construction framework that explicitly encodes long-term, cross-entity dependencies in egocentric video streams. EgoGraph employs a novel egocentric schema that unifies the extraction and abstraction of core entities, such as people, objects, locations, and events, and structurally reasons about their attributes and interactions, yielding a significantly richer and more coherent semantic representation than traditional clip-based video models. Crucially, we develop a temporal relational modeling strategy that captures temporal dependencies across entities and accumulates stable long-term memory over multiple days, enabling complex temporal reasoning. Extensive experiments on the EgoLifeQA and EgoR1-bench benchmarks demonstrate that EgoGraph achieves state-of-the-art performance on long-term video question answering, validating its effectiveness as a new paradigm for ultra-long egocentric video understanding.
Optimizing Multimodal LLMs for Egocentric Video Understanding: A Solution for the HD-EPIC VQA Challenge
Jan 15, 2026Multimodal Large Language Models (MLLMs) struggle with complex video QA benchmarks like HD-EPIC VQA due to ambiguous queries/options, poor long-range temporal reasoning, and non-standardized outputs. We propose a framework integrating query/choice pre-processing, domain-specific Qwen2.5-VL fine-tuning, a novel Temporal Chain-of-Thought (T-CoT) prompting for multi-step reasoning, and robust post-processing. This system achieves 41.6% accuracy on HD-EPIC VQA, highlighting the need for holistic pipeline optimization in demanding video understanding. Our code, fine-tuned models are available at https://github.com/YoungSeng/Egocentric-Co-Pilot.
Plug-and-Play Clarifier: A Zero-Shot Multimodal Framework for Egocentric Intent Disambiguation
Nov 12, 2025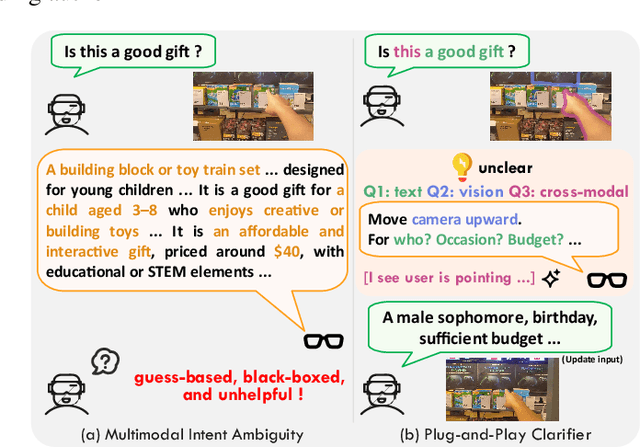
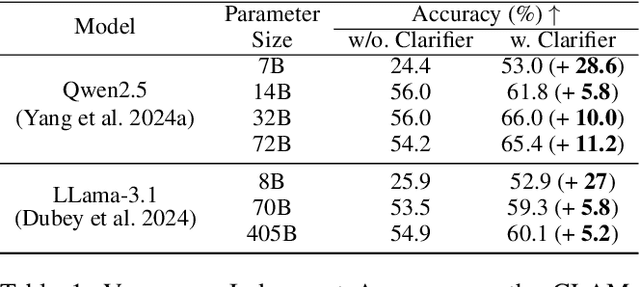
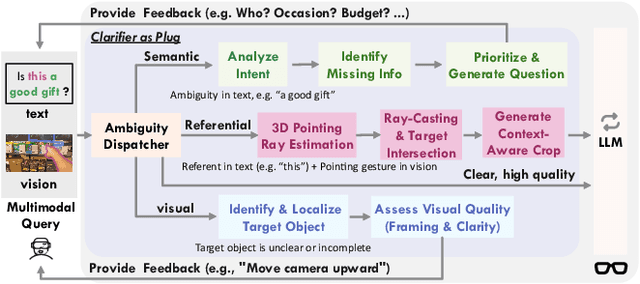
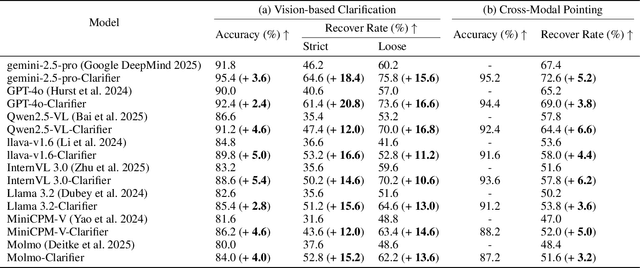
The performance of egocentric AI agents is fundamentally limited by multimodal intent ambiguity. This challenge arises from a combination of underspecified language, imperfect visual data, and deictic gestures, which frequently leads to task failure. Existing monolithic Vision-Language Models (VLMs) struggle to resolve these multimodal ambiguous inputs, often failing silently or hallucinating responses. To address these ambiguities, we introduce the Plug-and-Play Clarifier, a zero-shot and modular framework that decomposes the problem into discrete, solvable sub-tasks. Specifically, our framework consists of three synergistic modules: (1) a text clarifier that uses dialogue-driven reasoning to interactively disambiguate linguistic intent, (2) a vision clarifier that delivers real-time guidance feedback, instructing users to adjust their positioning for improved capture quality, and (3) a cross-modal clarifier with grounding mechanism that robustly interprets 3D pointing gestures and identifies the specific objects users are pointing to. Extensive experiments demonstrate that our framework improves the intent clarification performance of small language models (4--8B) by approximately 30%, making them competitive with significantly larger counterparts. We also observe consistent gains when applying our framework to these larger models. Furthermore, our vision clarifier increases corrective guidance accuracy by over 20%, and our cross-modal clarifier improves semantic answer accuracy for referential grounding by 5%. Overall, our method provides a plug-and-play framework that effectively resolves multimodal ambiguity and significantly enhances user experience in egocentric interaction.
Training-free Zero-shot Composed Image Retrieval with Local Concept Reranking
Dec 14, 2023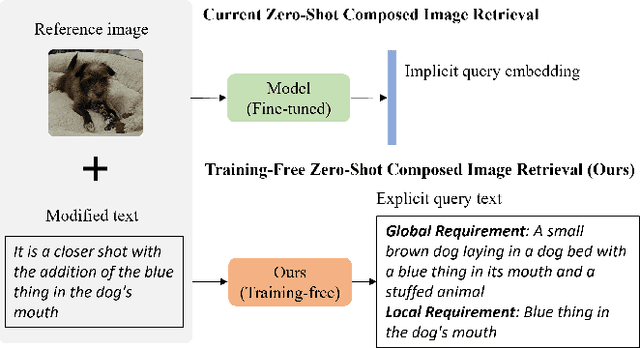
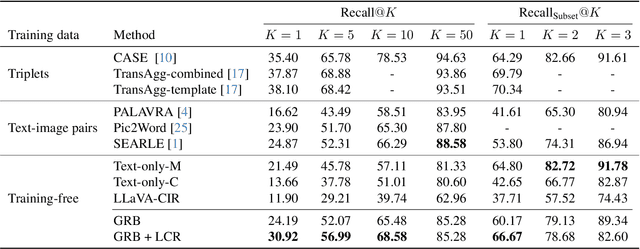
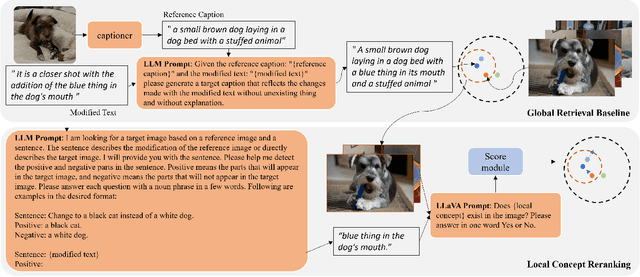

Composed image retrieval attempts to retrieve an image of interest from gallery images through a composed query of a reference image and its corresponding modified text. It has recently attracted attention due to the collaboration of information-rich images and concise language to precisely express the requirements of target images. Most of the existing composed image retrieval methods follow a supervised learning paradigm to perform training on a costly triplet dataset composed of a reference image, modified text, and a corresponding target image. To alleviate the demand for difficult-to-obtain labeled triplet data, recent methods have introduced zero-shot composed image retrieval (ZS-CIR), which aims to retrieve the target image without the supervision of human-labeled triplets but instead relies on image-text pairs or self-generated triplets. However, these methods are less computationally efficient due to the requirement of training and also less understandable, assuming that the interaction between image and text is conducted with implicit query embedding. In this work, we present a new Training-Free zero-shot Composed Image Retrieval (TFCIR) method which translates the query into explicit human-understandable text. This helps improve computation efficiency while maintaining the generalization of foundation models. Further, we introduce a Local Concept Reranking (LCR) mechanism to focus on discriminative local information extracted from the modified instruction. Extensive experiments on three ZS-CIR benchmarks show that the proposed approach can achieve comparable performances with state-of-the-art methods and significantly outperforms other training-free methods on the open domain datasets, CIRR and CIRCO, as well as the fashion domain dataset, FashionIQ.
Benchmarking Robustness of Text-Image Composed Retrieval
Nov 30, 2023
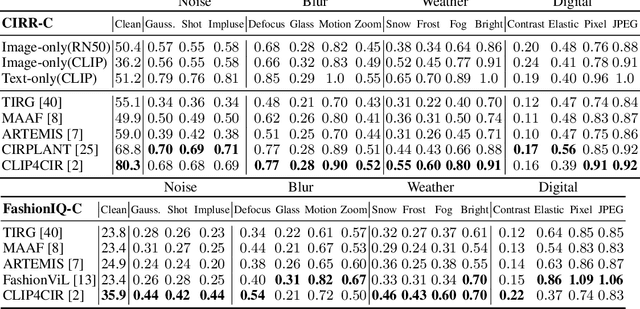


Text-image composed retrieval aims to retrieve the target image through the composed query, which is specified in the form of an image plus some text that describes desired modifications to the input image. It has recently attracted attention due to its ability to leverage both information-rich images and concise language to precisely express the requirements for target images. However, the robustness of these approaches against real-world corruptions or further text understanding has never been studied. In this paper, we perform the first robustness study and establish three new diversified benchmarks for systematic analysis of text-image composed retrieval against natural corruptions in both vision and text and further probe textural understanding. For natural corruption analysis, we introduce two new large-scale benchmark datasets, CIRR-C and FashionIQ-C for testing in open domain and fashion domain respectively, both of which apply 15 visual corruptions and 7 textural corruptions. For textural understanding analysis, we introduce a new diagnostic dataset CIRR-D by expanding the original raw data with synthetic data, which contains modified text to better probe textual understanding ability including numerical variation, attribute variation, object removal, background variation, and fine-grained evaluation. The code and benchmark datasets are available at https://github.com/SunTongtongtong/Benchmark-Robustness-Text-Image-Compose-Retrieval.
FSAR: Federated Skeleton-based Action Recognition with Adaptive Topology Structure and Knowledge Distillation
Jun 19, 2023



Existing skeleton-based action recognition methods typically follow a centralized learning paradigm, which can pose privacy concerns when exposing human-related videos. Federated Learning (FL) has attracted much attention due to its outstanding advantages in privacy-preserving. However, directly applying FL approaches to skeleton videos suffers from unstable training. In this paper, we investigate and discover that the heterogeneous human topology graph structure is the crucial factor hindering training stability. To address this limitation, we pioneer a novel Federated Skeleton-based Action Recognition (FSAR) paradigm, which enables the construction of a globally generalized model without accessing local sensitive data. Specifically, we introduce an Adaptive Topology Structure (ATS), separating generalization and personalization by learning a domain-invariant topology shared across clients and a domain-specific topology decoupled from global model aggregation.Furthermore, we explore Multi-grain Knowledge Distillation (MKD) to mitigate the discrepancy between clients and server caused by distinct updating patterns through aligning shallow block-wise motion features. Extensive experiments on multiple datasets demonstrate that FSAR outperforms state-of-the-art FL-based methods while inherently protecting privacy.
Federated Zero-Shot Learning with Mid-Level Semantic Knowledge Transfer
Aug 29, 2022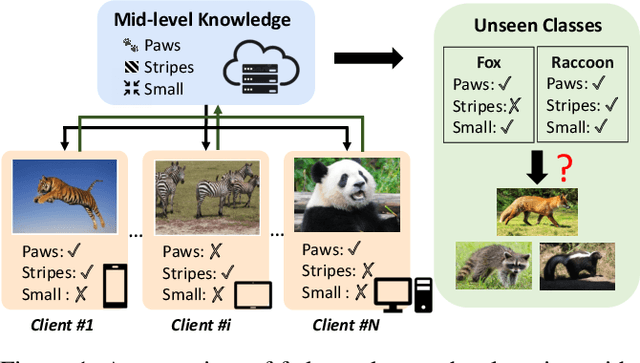
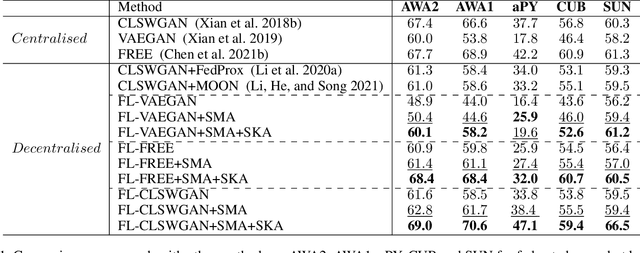
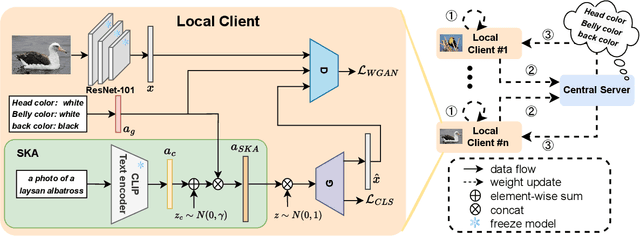
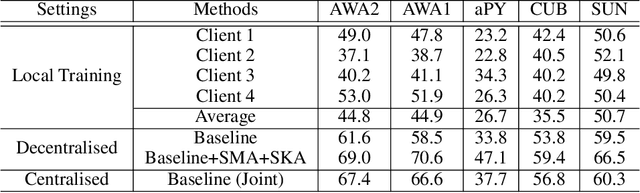
Conventional centralised deep learning paradigms are not feasible when data from different sources cannot be shared due to data privacy or transmission limitation. To resolve this problem, federated learning has been introduced to transfer knowledge across multiple sources (clients) with non-shared data while optimising a globally generalised central model (server). Existing federated learning paradigms mostly focus on transferring holistic high-level knowledge (such as class) across models, which are closely related to specific objects of interest so may suffer from inverse attack. In contrast, in this work, we consider transferring mid-level semantic knowledge (such as attribute) which is not sensitive to specific objects of interest and therefore is more privacy-preserving and scalable. To this end, we formulate a new Federated Zero-Shot Learning (FZSL) paradigm to learn mid-level semantic knowledge at multiple local clients with non-shared local data and cumulatively aggregate a globally generalised central model for deployment. To improve model discriminative ability, we propose to explore semantic knowledge augmentation from external knowledge for enriching the mid-level semantic space in FZSL. Extensive experiments on five zeroshot learning benchmark datasets validate the effectiveness of our approach for optimising a generalisable federated learning model with mid-level semantic knowledge transfer.
Decentralised Person Re-Identification with Selective Knowledge Aggregation
Oct 21, 2021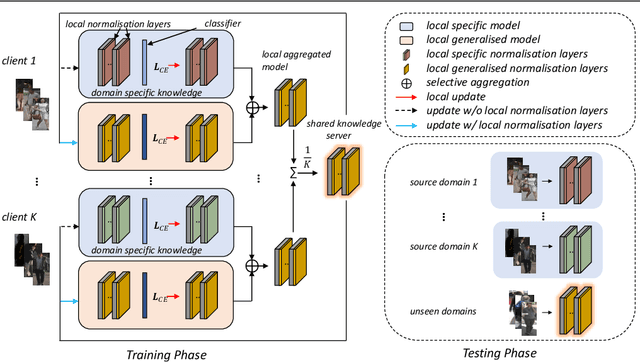
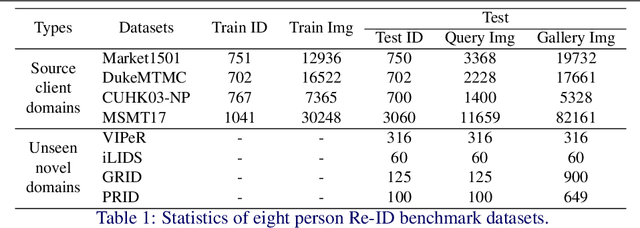
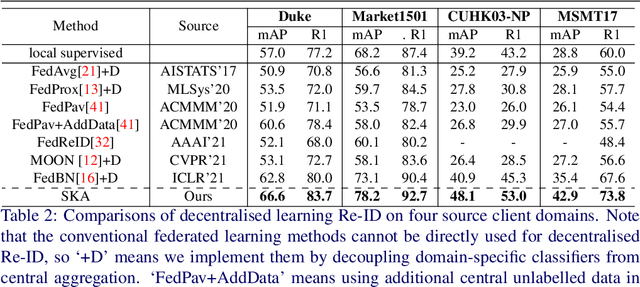
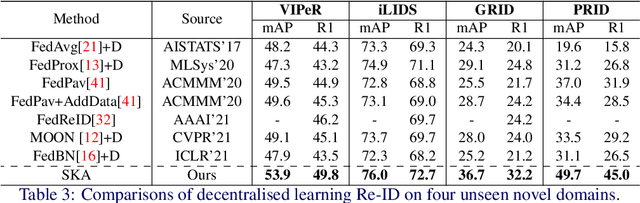
Existing person re-identification (Re-ID) methods mostly follow a centralised learning paradigm which shares all training data to a collection for model learning. This paradigm is limited when data from different sources cannot be shared due to privacy concerns. To resolve this problem, two recent works have introduced decentralised (federated) Re-ID learning for constructing a globally generalised model (server)without any direct access to local training data nor shared data across different source domains (clients). However, these methods are poor on how to adapt the generalised model to maximise its performance on individual client domain Re-ID tasks having different Re-ID label spaces, due to a lack of understanding of data heterogeneity across domains. We call this poor 'model personalisation'. In this work, we present a new Selective Knowledge Aggregation approach to decentralised person Re-ID to optimise the trade-off between model personalisation and generalisation. Specifically, we incorporate attentive normalisation into the normalisation layers in a deep ReID model and propose to learn local normalisation layers specific to each domain, which are decoupled from the global model aggregation in federated Re-ID learning. This helps to preserve model personalisation knowledge on each local client domain and learn instance-specific information. Further, we introduce a dual local normalisation mechanism to learn generalised normalisation layers in each local model, which are then transmitted to the global model for central aggregation. This facilitates selective knowledge aggregation on the server to construct a global generalised model for out-of-the-box deployment on unseen novel domains. Extensive experiments on eight person Re-ID datasets show that the proposed approach to decentralised Re-ID significantly outperforms the state-of-the-art decentralised methods.