 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Size, Many Fits: Aligning Diverse Group-Wise Click Preferences in Large-Scale Advertising Image Generation
Feb 02, 2026Advertising image generation has increasingly focused on online metrics like Click-Through Rate (CTR), yet existing approaches adopt a ``one-size-fits-all" strategy that optimizes for overall CTR while neglecting preference diversity among user groups. This leads to suboptimal performance for specific groups, limiting targeted marketing effectiveness. To bridge this gap, we present \textit{One Size, Many Fits} (OSMF), a unified framework that aligns diverse group-wise click preferences in large-scale advertising image generation. OSMF begins with product-aware adaptive grouping, which dynamically organizes users based on their attributes and product characteristics, representing each group with rich collective preference features. Building on these groups, preference-conditioned image generation employs a Group-aware Multimodal Large Language Model (G-MLLM) to generate tailored images for each group. The G-MLLM is pre-trained to simultaneously comprehend group features and generate advertising images. Subsequently, we fine-tune the G-MLLM using our proposed Group-DPO for group-wise preference alignment, which effectively enhances each group's CTR on the generated images. To further advance this field, we introduce the Grouped Advertising Image Preference Dataset (GAIP), the first large-scale public dataset of group-wise image preferences, including around 600K groups built from 40M users. Extensive experiments demonstrate that our framework achieves the state-of-the-art performance in both offline and online settings. Our code and datasets will be released at https://github.com/JD-GenX/OSMF.
StableWorld: Towards Stable and Consistent Long Interactive Video Generation
Jan 21, 2026In this paper, we explore the overlooked challenge of stability and temporal consistency in interactive video generation, which synthesizes dynamic and controllable video worlds through interactive behaviors such as camera movements and text prompts. Despite remarkable progress in world modeling, current methods still suffer from severe instability and temporal degradation, often leading to spatial drift and scene collapse during long-horizon interactions. To better understand this issue, we initially investigate the underlying causes of instability and identify that the major source of error accumulation originates from the same scene, where generated frames gradually deviate from the initial clean state and propagate errors to subsequent frames. Building upon this observation, we propose a simple yet effective method, \textbf{StableWorld}, a Dynamic Frame Eviction Mechanism. By continuously filtering out degraded frames while retaining geometrically consistent ones, StableWorld effectively prevents cumulative drift at its source, leading to more stable and temporal consistency of interactive generation. Promising results on multiple interactive video models, \eg, Matrix-Game, Open-Oasis, and Hunyuan-GameCraft, demonstrate that StableWorld is model-agnostic and can be applied to different interactive video generation frameworks to substantially improve stability, temporal consistency, and generalization across diverse interactive scenarios.
ProGuard: Towards Proactive Multimodal Safeguard
Dec 29, 2025The rapid evolution of generative models has led to a continuous emergence of multimodal safety risks, exposing the limitations of existing defense methods. To address these challenges, we propose ProGuard, a vision-language proactive guard that identifies and describes out-of-distribution (OOD) safety risks without the need for model adjustments required by traditional reactive approaches. We first construct a modality-balanced dataset of 87K samples, each annotated with both binary safety labels and risk categories under a hierarchical multimodal safety taxonomy, effectively mitigating modality bias and ensuring consistent moderation across text, image, and text-image inputs. Based on this dataset, we train our vision-language base model purely through reinforcement learning (RL) to achieve efficient and concise reasoning. To approximate proactive safety scenarios in a controlled setting, we further introduce an OOD safety category inference task and augment the RL objective with a synonym-bank-based similarity reward that encourages the model to generate concise descriptions for unseen unsafe categories. Experimental results show that ProGuard achieves performance comparable to closed-source large models on binary safety classification, substantially outperforms existing open-source guard models on unsafe content categorization. Most notably, ProGuard delivers a strong proactive moderation ability, improving OOD risk detection by 52.6% and OOD risk description by 64.8%.
LongVie 2: Multimodal Controllable Ultra-Long Video World Model
Dec 15, 2025Building video world models upon pretrained video generation systems represents an important yet challenging step toward general spatiotemporal intelligence. A world model should possess three essential properties: controllability, long-term visual quality, and temporal consistency. To this end, we take a progressive approach-first enhancing controllability and then extending toward long-term, high-quality generation. We present LongVie 2, an end-to-end autoregressive framework trained in three stages: (1) Multi-modal guidance, which integrates dense and sparse control signals to provide implicit world-level supervision and improve controllability; (2) Degradation-aware training on the input frame, bridging the gap between training and long-term inference to maintain high visual quality; and (3) History-context guidance, which aligns contextual information across adjacent clips to ensure temporal consistency. We further introduce LongVGenBench, a comprehensive benchmark comprising 100 high-resolution one-minute videos covering diverse real-world and synthetic environments. Extensive experiments demonstrate that LongVie 2 achieves state-of-the-art performance in long-range controllability, temporal coherence, and visual fidelity, and supports continuous video generation lasting up to five minutes, marking a significant step toward unified video world modeling.
SafeRBench: A Comprehensive Benchmark for Safety Assessment in Large Reasoning Models
Nov 19, 2025Large Reasoning Models (LRMs) improve answer quality through explicit chain-of-thought, yet this very capability introduces new safety risks: harmful content can be subtly injected, surface gradually, or be justified by misleading rationales within the reasoning trace. Existing safety evaluations, however, primarily focus on output-level judgments and rarely capture these dynamic risks along the reasoning process. In this paper, we present SafeRBench, the first benchmark that assesses LRM safety end-to-end -- from inputs and intermediate reasoning to final outputs. (1) Input Characterization: We pioneer the incorporation of risk categories and levels into input design, explicitly accounting for affected groups and severity, and thereby establish a balanced prompt suite reflecting diverse harm gradients. (2) Fine-Grained Output Analysis: We introduce a micro-thought chunking mechanism to segment long reasoning traces into semantically coherent units, enabling fine-grained evaluation across ten safety dimensions. (3) Human Safety Alignment: We validate LLM-based evaluations against human annotations specifically designed to capture safety judgments. Evaluations on 19 LRMs demonstrate that SafeRBench enables detailed, multidimensional safety assessment, offering insights into risks and protective mechanisms from multiple perspectives.
RealDPO: Real or Not Real, that is the Preference
Oct 16, 2025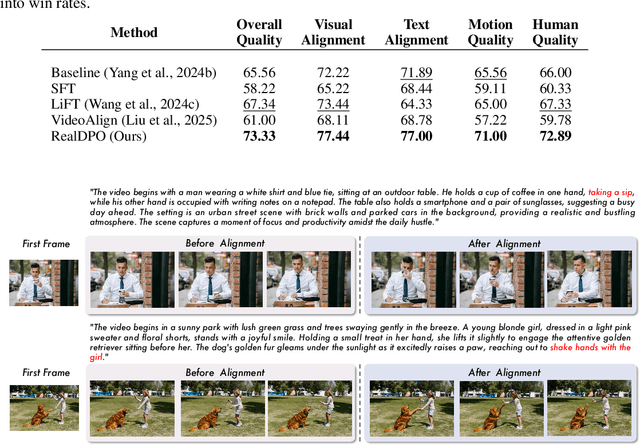

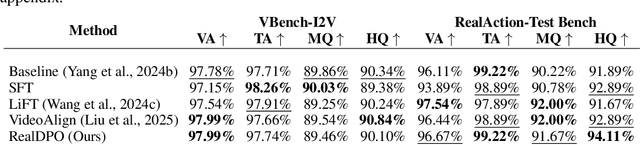
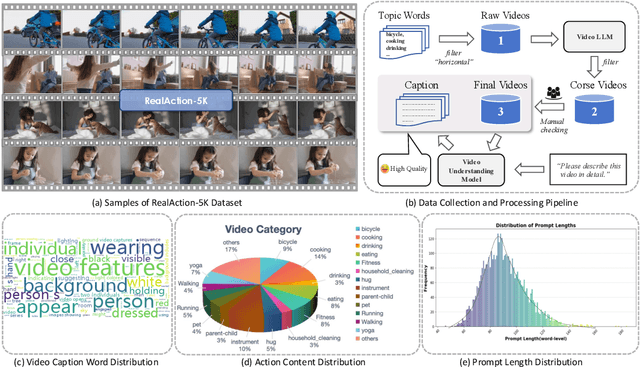
Video generative models have recently achieved notable advancements in synthesis quality. However, generating complex motions remains a critical challenge, as existing models often struggle to produce natural, smooth, and contextually consistent movements. This gap between generated and real-world motions limits their practical applicability. To address this issue, we introduce RealDPO, a novel alignment paradigm that leverages real-world data as positive samples for preference learning, enabling more accurate motion synthesis. Unlike traditional supervised fine-tuning (SFT), which offers limited corrective feedback, RealDPO employs Direct Preference Optimization (DPO) with a tailored loss function to enhance motion realism. By contrasting real-world videos with erroneous model outputs, RealDPO enables iterative self-correction, progressively refining motion quality. To support post-training in complex motion synthesis, we propose RealAction-5K, a curated dataset of high-quality videos capturing human daily activities with rich and precise motion details. Extensive experiments demonstrate that RealDPO significantly improves video quality, text alignment, and motion realism compared to state-of-the-art models and existing preference optimization techniques.
FreeMorph: Tuning-Free Generalized Image Morphing with Diffusion Model
Jul 02, 2025



We present FreeMorph, the first tuning-free method for image morphing that accommodates inputs with different semantics or layouts. Unlike existing methods that rely on finetuning pre-trained diffusion models and are limited by time constraints and semantic/layout discrepancies, FreeMorph delivers high-fidelity image morphing without requiring per-instance training. Despite their efficiency and potential, tuning-free methods face challenges in maintaining high-quality results due to the non-linear nature of the multi-step denoising process and biases inherited from the pre-trained diffusion model. In this paper, we introduce FreeMorph to address these challenges by integrating two key innovations. 1) We first propose a guidance-aware spherical interpolation design that incorporates explicit guidance from the input images by modifying the self-attention modules, thereby addressing identity loss and ensuring directional transitions throughout the generated sequence. 2) We further introduce a step-oriented variation trend that blends self-attention modules derived from each input image to achieve controlled and consistent transitions that respect both inputs. Our extensive evaluations demonstrate that FreeMorph outperforms existing methods, being 10x ~ 50x faster and establishing a new state-of-the-art for image morphing.
Rethinking Cross-Modal Interaction in Multimodal Diffusion Transformers
Jun 09, 2025



Multimodal Diffusion Transformers (MM-DiTs) have achieved remarkable progress in text-driven visual generation. However, even state-of-the-art MM-DiT models like FLUX struggle with achieving precise alignment between text prompts and generated content. We identify two key issues in the attention mechanism of MM-DiT, namely 1) the suppression of cross-modal attention due to token imbalance between visual and textual modalities and 2) the lack of timestep-aware attention weighting, which hinder the alignment. To address these issues, we propose \textbf{Temperature-Adjusted Cross-modal Attention (TACA)}, a parameter-efficient method that dynamically rebalances multimodal interactions through temperature scaling and timestep-dependent adjustment. When combined with LoRA fine-tuning, TACA significantly enhances text-image alignment on the T2I-CompBench benchmark with minimal computational overhead. We tested TACA on state-of-the-art models like FLUX and SD3.5, demonstrating its ability to improve image-text alignment in terms of object appearance, attribute binding, and spatial relationships. Our findings highlight the importance of balancing cross-modal attention in improving semantic fidelity in text-to-image diffusion models. Our codes are publicly available at \href{https://github.com/Vchitect/TACA}
V-STaR: Benchmarking Video-LLMs on Video Spatio-Temporal Reasoning
Mar 14, 2025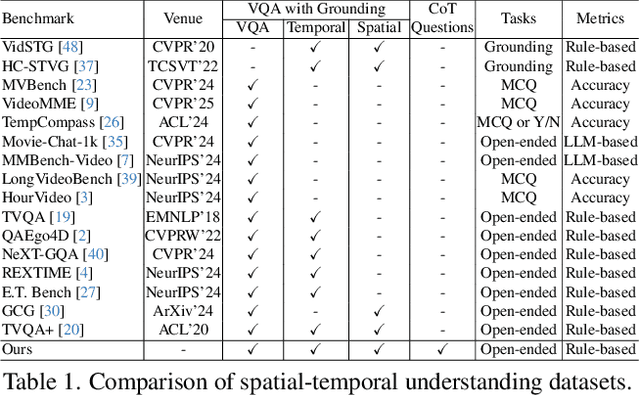
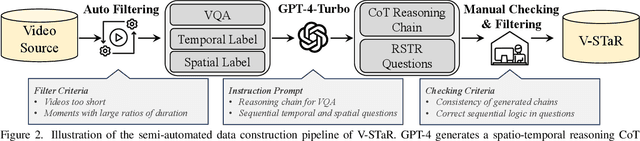

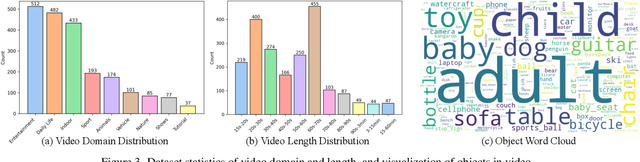
Human processes video reasoning in a sequential spatio-temporal reasoning logic, we first identify the relevant frames ("when") and then analyse the spatial relationships ("where") between key objects, and finally leverage these relationships to draw inferences ("what"). However, can Video Large Language Models (Video-LLMs) also "reason through a sequential spatio-temporal logic" in videos? Existing Video-LLM benchmarks primarily focus on assessing object presence, neglecting relational reasoning. Consequently, it is difficult to measure whether a model truly comprehends object interactions (actions/events) in videos or merely relies on pre-trained "memory" of co-occurrences as biases in generating answers. In this work, we introduce a Video Spatio-Temporal Reasoning (V-STaR) benchmark to address these shortcomings. The key idea is to decompose video understanding into a Reverse Spatio-Temporal Reasoning (RSTR) task that simultaneously evaluates what objects are present, when events occur, and where they are located while capturing the underlying Chain-of-thought (CoT) logic. To support this evaluation, we construct a dataset to elicit the spatial-temporal reasoning process of Video-LLMs. It contains coarse-to-fine CoT questions generated by a semi-automated GPT-4-powered pipeline, embedding explicit reasoning chains to mimic human cognition. Experiments from 14 Video-LLMs on our V-STaR reveal significant gaps between current Video-LLMs and the needs for robust and consistent spatio-temporal reasoning.
Lumina-Video: Efficient and Flexible Video Generation with Multi-scale Next-DiT
Feb 10, 2025Recent advancements have established Diffusion Transformers (DiTs) as a dominant framework in generative modeling. Building on this success, Lumina-Next achieves exceptional performance in the generation of photorealistic images with Next-DiT. However, its potential for video generation remains largely untapped, with significant challenges in modeling the spatiotemporal complexity inherent to video data. To address this, we introduce Lumina-Video, a framework that leverages the strengths of Next-DiT while introducing tailored solutions for video synthesis. Lumina-Video incorporates a Multi-scale Next-DiT architecture, which jointly learns multiple patchifications to enhance both efficiency and flexibility. By incorporating the motion score as an explicit condition, Lumina-Video also enables direct control of generated videos' dynamic degree. Combined with a progressive training scheme with increasingly higher resolution and FPS, and a multi-source training scheme with mixed natural and synthetic data, Lumina-Video achieves remarkable aesthetic quality and motion smoothness at high training and inference efficiency. We additionally propose Lumina-V2A, a video-to-audio model based on Next-DiT, to create synchronized sounds for generated videos. Codes are released at https://www.github.com/Alpha-VLLM/Lumina-Video.