 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARGUS: Stacked Multi-View Identity Mosaic Injection for Subject-Preserving Video Generation
Jun 10, 2026Subject-preserving video generation is not solved by frontal-face similarity alone: a generated person must remain recognizable across motion, large viewpoint changes, expression shifts, occlusion, scale variation, and conflicts among text, first-frame, and identity references. We argue that the central bottleneck is the point-reference paradigm, which collapses identity into a single static observation entangled with pose, accessories, lighting, background, and camera statistics. We introduce Argus, a Wan-based framework centered on Stacked Multi-View Identity Mosaic Injection (SMII). SMII converts MLLM-selected image/video identity evidence into a 3*3 stacked mosaic, synchronizes the mosaic with the current diffusion time, and injects it as negative-time read-only memory in Wan's native token space. This turns identity from an external clean adapter or a single reference image into a compact dynamic distribution. Around SMII, an MLLM Identity Director selects informative identity moments and resolves condition conflicts, while no-cross-pair counterfactual training, Temporal Identity Annealing, and Adaptive Self-Likeness Guidance improve robustness without paired subject-video supervision. We further release HardID-Celeb, a public-figure identity-stress benchmark, and introduce YawScore and OccScore to probe large-yaw and first-frame-occlusion robustness. Argus achieves state-of-the-art results on OpenS2V-Eval Human-Domain, reaching 64.38 Total Score, 71.86 FaceSim, 51.62 NexusScore, and 79.14 NaturalScore. On HardID-Celeb, Argus obtains 76.80 FaceSim and improves YawScore and OccScore by 12.60 and 15.10 points over the strongest baselines, demonstrating that dynamic identity memory and large-scale counterfactual self-supervision are highly effective for subject-preserving video generation.
VTouch++: A Multimodal Dataset with Vision-Based Tactile Enhancement for Bimanual Manipulation
Apr 22, 2026Embodied intelligence has advanced rapidly in recent years; however, bimanual manipulation-especially in contact-rich tasks remains challenging. This is largely due to the lack of datasets with rich physical interaction signals, systematic task organization, and sufficient scale. To address these limitations, we introduce the VTOUCH dataset. It leverages vision based tactile sensing to provide high-fidelity physical interaction signals, adopts a matrix-style task design to enable systematic learning, and employs automated data collection pipelines covering real-world, demand-driven scenarios to ensure scalability. To further validate the effectiveness of the dataset, we conduct extensive quantitative experiments on cross-modal retrieval as well as real-robot evaluation. Finally, we demonstrate real-world performance through generalizable inference across multiple robots, policies, and tasks.
GeoLoco: Leveraging 3D Geometric Priors from Visual Foundation Model for Robust RGB-Only Humanoid Locomotion
Mar 08, 2026The prevailing paradigm of perceptive humanoid locomotion relies heavily on active depth sensors. However, this depth-centric approach fundamentally discards the rich semantic and dense appearance cues of the visual world, severing low-level control from the high-level reasoning essential for general embodied intelligence. While monocular RGB offers a ubiquitous, information-dense alternative, end-to-end reinforcement learning from raw 2D pixels suffers from extreme sample inefficiency and catastrophic sim-to-real collapse due to the inherent loss of geometric scale. To break this deadlock, we propose GeoLoco, a purely RGB-driven locomotion framework that conceptualizes monocular images as high-dimensional 3D latent representations by harnessing the powerful geometric priors of a frozen, scale-aware Visual Foundation Model (VFM). Rather than naive feature concatenation, we design a proprioceptive-query multi-head cross-attention mechanism that dynamically attends to task-critical topological features conditioned on the robot's real-time gait phase. Crucially, to prevent the policy from overfitting to superficial textures, we introduce a dual-head auxiliary learning scheme. This explicit regularization forces the high-dimensional latent space to strictly align with the physical terrain geometry, ensuring robust zero-shot sim-to-real transfer. Trained exclusively in simulation, GeoLoco achieves robust zero-shot transfer to the Unitree G1 humanoid and successfully negotiates challenging terrains.
Precision over Diversity: High-Precision Reward Generalizes to Robust Instruction Following
Jan 08, 2026A central belief in scaling reinforcement learning with verifiable rewards for instruction following (IF) tasks is that, a diverse mixture of verifiable hard and unverifiable soft constraints is essential for generalizing to unseen instructions. In this work, we challenge this prevailing consensus through a systematic empirical investigation. Counter-intuitively, we find that models trained on hard-only constraints consistently outperform those trained on mixed datasets. Extensive experiments reveal that reward precision, rather than constraint diversity, is the primary driver of effective alignment. The LLM judge suffers from a low recall rate in detecting false response, which leads to severe reward hacking, thereby undermining the benefits of diversity. Furthermore, analysis of the attention mechanism reveals that high-precision rewards develop a transferable meta-skill for IF. Motivated by these insights, we propose a simple yet effective data-centric refinement strategy that prioritizes reward precision. Evaluated on five benchmarks, our approach outperforms competitive baselines by 13.4\% in performance while achieving a 58\% reduction in training time, maintaining strong generalization beyond instruction following. Our findings advocate for a paradigm shift: moving away from the indiscriminate pursuit of data diversity toward high-precision rewards.
InternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
Jan 05, 2026Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal Large Language Models (MLLMs) and demonstrate exceptional proficiency in semantic understanding, but they inherently lack the capability to deduce physical world dynamics. Consequently, recent approaches have shifted toward World Models, typically formulated via video prediction; however, these methods often suffer from a lack of semantic grounding and exhibit brittleness when handling prediction errors. To synergize semantic understanding with dynamic predictive capabilities, we present InternVLA-A1. This model employs a unified Mixture-of-Transformers architecture, coordinating three experts for scene understanding, visual foresight generation, and action execution. These components interact seamlessly through a unified masked self-attention mechanism. Building upon InternVL3 and Qwen3-VL, we instantiate InternVLA-A1 at 2B and 3B parameter scales. We pre-train these models on hybrid synthetic-real datasets spanning InternData-A1 and Agibot-World, covering over 533M frames. This hybrid training strategy effectively harnesses the diversity of synthetic simulation data while minimizing the sim-to-real gap. We evaluated InternVLA-A1 across 12 real-world robotic tasks and simulation benchmark. It significantly outperforms leading models like pi0 and GR00T N1.5, achieving a 14.5\% improvement in daily tasks and a 40\%-73.3\% boost in dynamic settings, such as conveyor belt sorting.
Next Tokens Denoising for Speech Synthesis
Jul 30, 2025While diffusion and autoregressive (AR) models have significantly advanced generative modeling, they each present distinct limitations. AR models, which rely on causal attention, cannot exploit future context and suffer from slow generation speeds. Conversely, diffusion models struggle with key-value (KV) caching. To overcome these challenges, we introduce Dragon-FM, a novel text-to-speech (TTS) design that unifies AR and flow-matching. This model processes 48 kHz audio codec tokens in chunks at a compact 12.5 tokens per second rate. This design enables AR modeling across chunks, ensuring global coherence, while parallel flow-matching within chunks facilitates fast iterative denoising. Consequently, the proposed model can utilize KV-cache across chunks and incorporate future context within each chunk. Furthermore, it bridges continuous and discrete feature modeling, demonstrating that continuous AR flow-matching can predict discrete tokens with finite scalar quantizers. This efficient codec and fast chunk-autoregressive architecture also makes the proposed model particularly effective for generating extended content. Experiment for demos of our work} on podcast datasets demonstrate its capability to efficiently generate high-quality zero-shot podcasts.
SynPo: Boosting Training-Free Few-Shot Medical Segmentation via High-Quality Negative Prompts
Jun 18, 2025The advent of Large Vision Models (LVMs) offers new opportunities for few-shot medical image segmentation. However, existing training-free methods based on LVMs fail to effectively utilize negative prompts, leading to poor performance on low-contrast medical images. To address this issue, we propose SynPo, a training-free few-shot method based on LVMs (e.g., SAM), with the core insight: improving the quality of negative prompts. To select point prompts in a more reliable confidence map, we design a novel Confidence Map Synergy Module by combining the strengths of DINOv2 and SAM. Based on the confidence map, we select the top-k pixels as the positive points set and choose the negative points set using a Gaussian distribution, followed by independent K-means clustering for both sets. Then, these selected points are leveraged as high-quality prompts for SAM to get the segmentation results. Extensive experiments demonstrate that SynPo achieves performance comparable to state-of-the-art training-based few-shot methods.
Astra: Toward General-Purpose Mobile Robots via Hierarchical Multimodal Learning
Jun 06, 2025Modern robot navigation systems encounter difficulties in diverse and complex indoor environments. Traditional approaches rely on multiple modules with small models or rule-based systems and thus lack adaptability to new environments. To address this, we developed Astra, a comprehensive dual-model architecture, Astra-Global and Astra-Local, for mobile robot navigation. Astra-Global, a multimodal LLM, processes vision and language inputs to perform self and goal localization using a hybrid topological-semantic graph as the global map, and outperforms traditional visual place recognition methods. Astra-Local, a multitask network, handles local path planning and odometry estimation. Its 4D spatial-temporal encoder, trained through self-supervised learning, generates robust 4D features for downstream tasks. The planning head utilizes flow matching and a novel masked ESDF loss to minimize collision risks for generating local trajectories, and the odometry head integrates multi-sensor inputs via a transformer encoder to predict the relative pose of the robot. Deployed on real in-house mobile robots, Astra achieves high end-to-end mission success rate across diverse indoor environments.
YH-MINER: Multimodal Intelligent System for Natural Ecological Reef Metric Extraction
May 29, 2025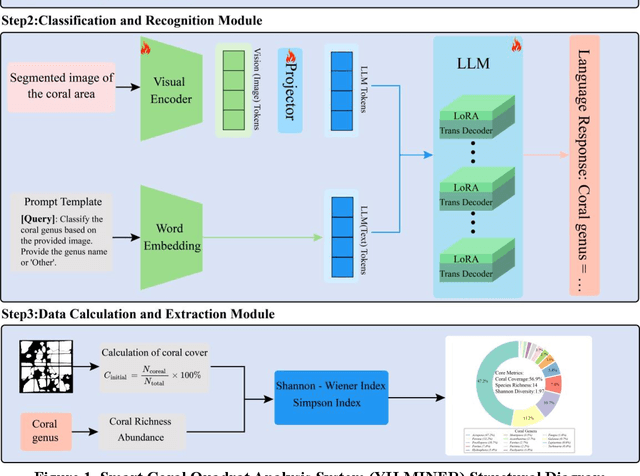
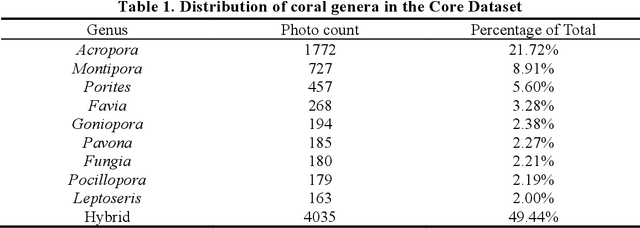
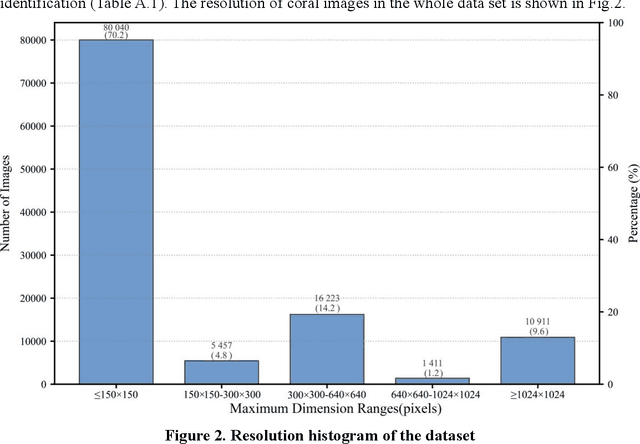

Coral reefs, crucial for sustaining marine biodiversity and ecological processes (e.g., nutrient cycling, habitat provision), face escalating threats, underscoring the need for efficient monitoring. Coral reef ecological monitoring faces dual challenges of low efficiency in manual analysis and insufficient segmentation accuracy in complex underwater scenarios. This study develops the YH-MINER system, establishing an intelligent framework centered on the Multimodal Large Model (MLLM) for "object detection-semantic segmentation-prior input". The system uses the object detection module (mAP@0.5=0.78) to generate spatial prior boxes for coral instances, driving the segment module to complete pixel-level segmentation in low-light and densely occluded scenarios. The segmentation masks and finetuned classification instructions are fed into the Qwen2-VL-based multimodal model as prior inputs, achieving a genus-level classification accuracy of 88% and simultaneously extracting core ecological metrics. Meanwhile, the system retains the scalability of the multimodal model through standardized interfaces, laying a foundation for future integration into multimodal agent-based underwater robots and supporting the full-process automation of "image acquisition-prior generation-real-time analysis".
Lumina-Video: Efficient and Flexible Video Generation with Multi-scale Next-DiT
Feb 10, 2025Recent advancements have established Diffusion Transformers (DiTs) as a dominant framework in generative modeling. Building on this success, Lumina-Next achieves exceptional performance in the generation of photorealistic images with Next-DiT. However, its potential for video generation remains largely untapped, with significant challenges in modeling the spatiotemporal complexity inherent to video data. To address this, we introduce Lumina-Video, a framework that leverages the strengths of Next-DiT while introducing tailored solutions for video synthesis. Lumina-Video incorporates a Multi-scale Next-DiT architecture, which jointly learns multiple patchifications to enhance both efficiency and flexibility. By incorporating the motion score as an explicit condition, Lumina-Video also enables direct control of generated videos' dynamic degree. Combined with a progressive training scheme with increasingly higher resolution and FPS, and a multi-source training scheme with mixed natural and synthetic data, Lumina-Video achieves remarkable aesthetic quality and motion smoothness at high training and inference efficiency. We additionally propose Lumina-V2A, a video-to-audio model based on Next-DiT, to create synchronized sounds for generated videos. Codes are released at https://www.github.com/Alpha-VLLM/Lumina-Video.