 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControl of Microrobots with Reinforcement Learning under On-Device Compute Constraints
Dec 31, 2025An important function of autonomous microrobots is the ability to perform robust movement over terrain. This paper explores an edge ML approach to microrobot locomotion, allowing for on-device, lower latency control under compute, memory, and power constraints. This paper explores the locomotion of a sub-centimeter quadrupedal microrobot via reinforcement learning (RL) and deploys the resulting controller on an ultra-small system-on-chip (SoC), SC$μ$M-3C, featuring an ARM Cortex-M0 microcontroller running at 5 MHz. We train a compact FP32 multilayer perceptron (MLP) policy with two hidden layers ($[128, 64]$) in a massively parallel GPU simulation and enhance robustness by utilizing domain randomization over simulation parameters. We then study integer (Int8) quantization (per-tensor and per-feature) to allow for higher inference update rates on our resource-limited hardware, and we connect hardware power budgets to achievable update frequency via a cycles-per-update model for inference on our Cortex-M0. We propose a resource-aware gait scheduling viewpoint: given a device power budget, we can select the gait mode (trot/intermediate/gallop) that maximizes expected RL reward at a corresponding feasible update frequency. Finally, we deploy our MLP policy on a real-world large-scale robot on uneven terrain, qualitatively noting that domain-randomized training can improve out-of-distribution stability. We do not claim real-world large-robot empirical zero-shot transfer in this work.
Rank-Aware Agglomeration of Foundation Models for Immunohistochemistry Image Cell Counting
Nov 16, 2025Accurate cell counting in immunohistochemistry (IHC) images is critical for quantifying protein expression and aiding cancer diagnosis. However, the task remains challenging due to the chromogen overlap, variable biomarker staining, and diverse cellular morphologies. Regression-based counting methods offer advantages over detection-based ones in handling overlapped cells, yet rarely support end-to-end multi-class counting. Moreover, the potential of foundation models remains largely underexplored in this paradigm. To address these limitations, we propose a rank-aware agglomeration framework that selectively distills knowledge from multiple strong foundation models, leveraging their complementary representations to handle IHC heterogeneity and obtain a compact yet effective student model, CountIHC. Unlike prior task-agnostic agglomeration strategies that either treat all teachers equally or rely on feature similarity, we design a Rank-Aware Teacher Selecting (RATS) strategy that models global-to-local patch rankings to assess each teacher's inherent counting capacity and enable sample-wise teacher selection. For multi-class cell counting, we introduce a fine-tuning stage that reformulates the task as vision-language alignment. Discrete semantic anchors derived from structured text prompts encode both category and quantity information, guiding the regression of class-specific density maps and improving counting for overlapping cells. Extensive experiments demonstrate that CountIHC surpasses state-of-the-art methods across 12 IHC biomarkers and 5 tissue types, while exhibiting high agreement with pathologists' assessments. Its effectiveness on H&E-stained data further confirms the scalability of the proposed method.
Toward Real-World Cooperative and Competitive Soccer with Quadrupedal Robot Teams
May 20, 2025Achieving coordinated teamwork among legged robots requires both fine-grained locomotion control and long-horizon strategic decision-making. Robot soccer offers a compelling testbed for this challenge, combining dynamic, competitive, and multi-agent interactions. In this work, we present a hierarchical multi-agent reinforcement learning (MARL) framework that enables fully autonomous and decentralized quadruped robot soccer. First, a set of highly dynamic low-level skills is trained for legged locomotion and ball manipulation, such as walking, dribbling, and kicking. On top of these, a high-level strategic planning policy is trained with Multi-Agent Proximal Policy Optimization (MAPPO) via Fictitious Self-Play (FSP). This learning framework allows agents to adapt to diverse opponent strategies and gives rise to sophisticated team behaviors, including coordinated passing, interception, and dynamic role allocation. With an extensive ablation study, the proposed learning method shows significant advantages in the cooperative and competitive multi-agent soccer game. We deploy the learned policies to real quadruped robots relying solely on onboard proprioception and decentralized localization, with the resulting system supporting autonomous robot-robot and robot-human soccer matches on indoor and outdoor soccer courts.
LangWBC: Language-directed Humanoid Whole-Body Control via End-to-end Learning
Apr 30, 2025General-purpose humanoid robots are expected to interact intuitively with humans, enabling seamless integration into daily life. Natural language provides the most accessible medium for this purpose. However, translating language into humanoid whole-body motion remains a significant challenge, primarily due to the gap between linguistic understanding and physical actions. In this work, we present an end-to-end, language-directed policy for real-world humanoid whole-body control. Our approach combines reinforcement learning with policy distillation, allowing a single neural network to interpret language commands and execute corresponding physical actions directly. To enhance motion diversity and compositionality, we incorporate a Conditional Variational Autoencoder (CVAE) structure. The resulting policy achieves agile and versatile whole-body behaviors conditioned on language inputs, with smooth transitions between various motions, enabling adaptation to linguistic variations and the emergence of novel motions. We validate the efficacy and generalizability of our method through extensive simulations and real-world experiments, demonstrating robust whole-body control. Please see our website at LangWBC.github.io for more information.
Demonstrating Berkeley Humanoid Lite: An Open-source, Accessible, and Customizable 3D-printed Humanoid Robot
Apr 24, 2025Despite significant interest and advancements in humanoid robotics, most existing commercially available hardware remains high-cost, closed-source, and non-transparent within the robotics community. This lack of accessibility and customization hinders the growth of the field and the broader development of humanoid technologies. To address these challenges and promote democratization in humanoid robotics, we demonstrate Berkeley Humanoid Lite, an open-source humanoid robot designed to be accessible, customizable, and beneficial for the entire community. The core of this design is a modular 3D-printed gearbox for the actuators and robot body. All components can be sourced from widely available e-commerce platforms and fabricated using standard desktop 3D printers, keeping the total hardware cost under $5,000 (based on U.S. market prices). The design emphasizes modularity and ease of fabrication. To address the inherent limitations of 3D-printed gearboxes, such as reduced strength and durability compared to metal alternatives, we adopted a cycloidal gear design, which provides an optimal form factor in this context. Extensive testing was conducted on the 3D-printed actuators to validate their durability and alleviate concerns about the reliability of plastic components. To demonstrate the capabilities of Berkeley Humanoid Lite, we conducted a series of experiments, including the development of a locomotion controller using reinforcement learning. These experiments successfully showcased zero-shot policy transfer from simulation to hardware, highlighting the platform's suitability for research validation. By fully open-sourcing the hardware design, embedded code, and training and deployment frameworks, we aim for Berkeley Humanoid Lite to serve as a pivotal step toward democratizing the development of humanoid robotics. All resources are available at https://lite.berkeley-humanoid.org.
Variable-frame CNNLSTM for Breast Nodule Classification using Ultrasound Videos
Feb 17, 2025



The intersection of medical imaging and artificial intelligence has become an important research direction in intelligent medical treatment, particularly in the analysis of medical images using deep learning for clinical diagnosis. Despite the advances, existing keyframe classification methods lack extraction of time series features, while ultrasonic video classification based on three-dimensional convolution requires uniform frame numbers across patients, resulting in poor feature extraction efficiency and model classification performance. This study proposes a novel video classification method based on CNN and LSTM, introducing NLP's long and short sentence processing scheme into video classification for the first time. The method reduces CNN-extracted image features to 1x512 dimension, followed by sorting and compressing feature vectors for LSTM training. Specifically, feature vectors are sorted by patient video frame numbers and populated with padding value 0 to form variable batches, with invalid padding values compressed before LSTM training to conserve computing resources. Experimental results demonstrate that our variable-frame CNNLSTM method outperforms other approaches across all metrics, showing improvements of 3-6% in F1 score and 1.5% in specificity compared to keyframe methods. The variable-frame CNNLSTM also achieves better accuracy and precision than equal-frame CNNLSTM. These findings validate the effectiveness of our approach in classifying variable-frame ultrasound videos and suggest potential applications in other medical imaging modalities.
Lumina-Video: Efficient and Flexible Video Generation with Multi-scale Next-DiT
Feb 10, 2025Recent advancements have established Diffusion Transformers (DiTs) as a dominant framework in generative modeling. Building on this success, Lumina-Next achieves exceptional performance in the generation of photorealistic images with Next-DiT. However, its potential for video generation remains largely untapped, with significant challenges in modeling the spatiotemporal complexity inherent to video data. To address this, we introduce Lumina-Video, a framework that leverages the strengths of Next-DiT while introducing tailored solutions for video synthesis. Lumina-Video incorporates a Multi-scale Next-DiT architecture, which jointly learns multiple patchifications to enhance both efficiency and flexibility. By incorporating the motion score as an explicit condition, Lumina-Video also enables direct control of generated videos' dynamic degree. Combined with a progressive training scheme with increasingly higher resolution and FPS, and a multi-source training scheme with mixed natural and synthetic data, Lumina-Video achieves remarkable aesthetic quality and motion smoothness at high training and inference efficiency. We additionally propose Lumina-V2A, a video-to-audio model based on Next-DiT, to create synchronized sounds for generated videos. Codes are released at https://www.github.com/Alpha-VLLM/Lumina-Video.
IMAGINE-E: Image Generation Intelligence Evaluation of State-of-the-art Text-to-Image Models
Jan 23, 2025



With the rapid development of diffusion models, text-to-image(T2I) models have made significant progress, showcasing impressive abilities in prompt following and image generation. Recently launched models such as FLUX.1 and Ideogram2.0, along with others like Dall-E3 and Stable Diffusion 3, have demonstrated exceptional performance across various complex tasks, raising questions about whether T2I models are moving towards general-purpose applicability. Beyond traditional image generation, these models exhibit capabilities across a range of fields, including controllable generation, image editing, video, audio, 3D, and motion generation, as well as computer vision tasks like semantic segmentation and depth estimation. However, current evaluation frameworks are insufficient to comprehensively assess these models' performance across expanding domains. To thoroughly evaluate these models, we developed the IMAGINE-E and tested six prominent models: FLUX.1, Ideogram2.0, Midjourney, Dall-E3, Stable Diffusion 3, and Jimeng. Our evaluation is divided into five key domains: structured output generation, realism, and physical consistency, specific domain generation, challenging scenario generation, and multi-style creation tasks. This comprehensive assessment highlights each model's strengths and limitations, particularly the outstanding performance of FLUX.1 and Ideogram2.0 in structured and specific domain tasks, underscoring the expanding applications and potential of T2I models as foundational AI tools. This study provides valuable insights into the current state and future trajectory of T2I models as they evolve towards general-purpose usability. Evaluation scripts will be released at https://github.com/jylei16/Imagine-e.
Online Omnidirectional Jumping Trajectory Planning for Quadrupedal Robots on Uneven Terrains
Nov 07, 2024Natural terrain complexity often necessitates agile movements like jumping in animals to improve traversal efficiency. To enable similar capabilities in quadruped robots, complex real-time jumping maneuvers are required. Current research does not adequately address the problem of online omnidirectional jumping and neglects the robot's kinodynamic constraints during trajectory generation. This paper proposes a general and complete cascade online optimization framework for omnidirectional jumping for quadruped robots. Our solution systematically encompasses jumping trajectory generation, a trajectory tracking controller, and a landing controller. It also incorporates environmental perception to navigate obstacles that standard locomotion cannot bypass, such as jumping from high platforms. We introduce a novel jumping plane to parameterize omnidirectional jumping motion and formulate a tightly coupled optimization problem accounting for the kinodynamic constraints, simultaneously optimizing CoM trajectory, Ground Reaction Forces (GRFs), and joint states. To meet the online requirements, we propose an accelerated evolutionary algorithm as the trajectory optimizer to address the complexity of kinodynamic constraints. To ensure stability and accuracy in environmental perception post-landing, we introduce a coarse-to-fine relocalization method that combines global Branch and Bound (BnB) search with Maximum a Posteriori (MAP) estimation for precise positioning during navigation and jumping. The proposed framework achieves jump trajectory generation in approximately 0.1 seconds with a warm start and has been successfully validated on two quadruped robots on uneven terrains. Additionally, we extend the framework's versatility to humanoid robots.
Interactive Navigation with Adaptive Non-prehensile Mobile Manipulation
Oct 17, 2024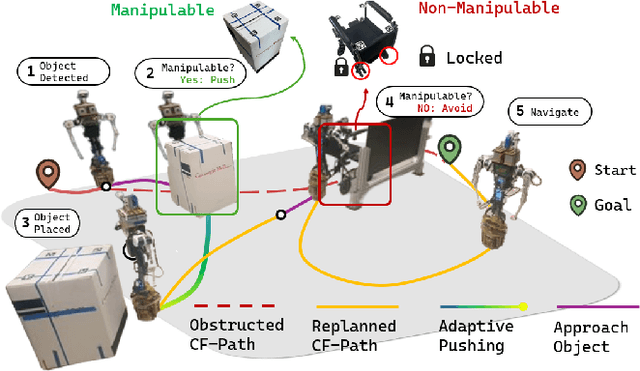
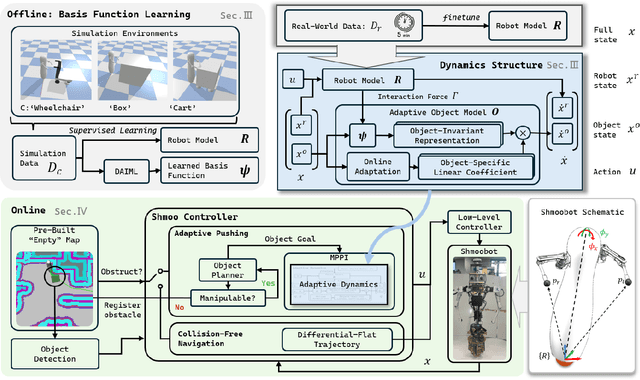
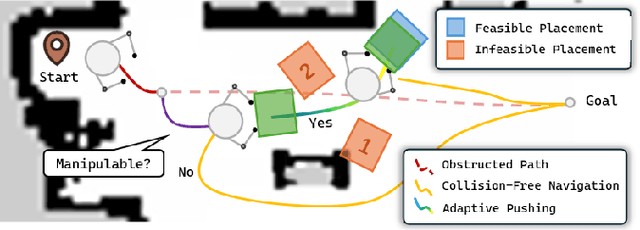
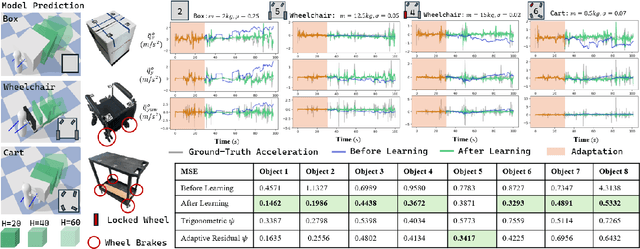
This paper introduces a framework for interactive navigation through adaptive non-prehensile mobile manipulation. A key challenge in this process is handling objects with unknown dynamics, which are difficult to infer from visual observation. To address this, we propose an adaptive dynamics model for common movable indoor objects via learned SE(2) dynamics representations. This model is integrated into Model Predictive Path Integral (MPPI) control to guide the robot's interactions. Additionally, the learned dynamics help inform decision-making when navigating around objects that cannot be manipulated.Our approach is validated in both simulation and real-world scenarios, demonstrating its ability to accurately represent object dynamics and effectively manipulate various objects. We further highlight its success in the Navigation Among Movable Objects (NAMO) task by deploying the proposed framework on a dynamically balancing mobile robot, Shmoobot. Project website: https://cmushmoobot.github.io/AdaptivePushing/.