 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHITTER: A HumanoId Table TEnnis Robot via Hierarchical Planning and Learning
Aug 28, 2025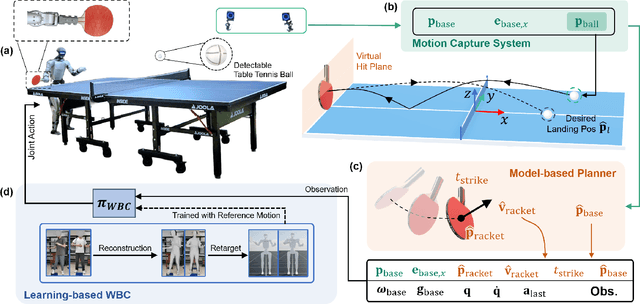
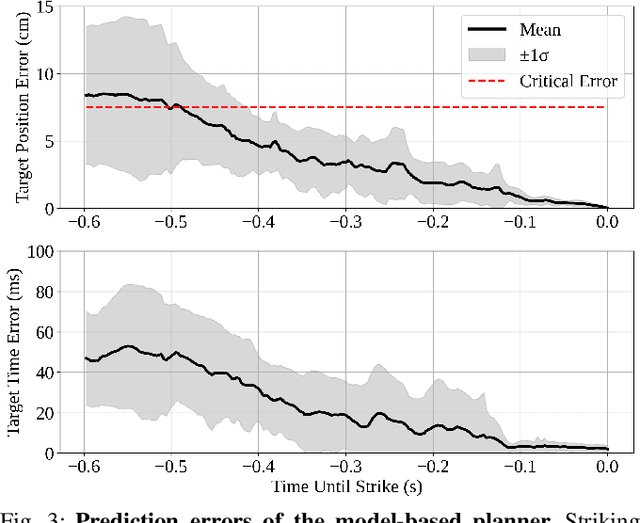
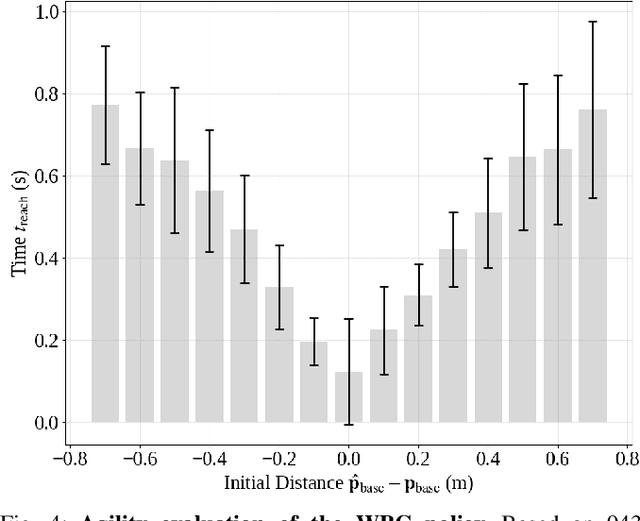

Humanoid robots have recently achieved impressive progress in locomotion and whole-body control, yet they remain constrained in tasks that demand rapid interaction with dynamic environments through manipulation. Table tennis exemplifies such a challenge: with ball speeds exceeding 5 m/s, players must perceive, predict, and act within sub-second reaction times, requiring both agility and precision. To address this, we present a hierarchical framework for humanoid table tennis that integrates a model-based planner for ball trajectory prediction and racket target planning with a reinforcement learning-based whole-body controller. The planner determines striking position, velocity and timing, while the controller generates coordinated arm and leg motions that mimic human strikes and maintain stability and agility across consecutive rallies. Moreover, to encourage natural movements, human motion references are incorporated during training. We validate our system on a general-purpose humanoid robot, achieving up to 106 consecutive shots with a human opponent and sustained exchanges against another humanoid. These results demonstrate real-world humanoid table tennis with sub-second reactive control, marking a step toward agile and interactive humanoid behaviors.
MRTA-Sim: A Modular Simulator for Multi-Robot Allocation, Planning, and Control in Open-World Environments
Apr 21, 2025



This paper introduces MRTA-Sim, a Python/ROS2/Gazebo simulator for testing approaches to Multi-Robot Task Allocation (MRTA) problems on simulated robots in complex, indoor environments. Grid-based approaches to MRTA problems can be too restrictive for use in complex, dynamic environments such in warehouses, department stores, hospitals, etc. However, approaches that operate in free-space often operate at a layer of abstraction above the control and planning layers of a robot and make an assumption on approximate travel time between points of interest in the system. These abstractions can neglect the impact of the tight space and multi-agent interactions on the quality of the solution. Therefore, MRTA solutions should be tested with the navigation stacks of the robots in mind, taking into account robot planning, conflict avoidance between robots, and human interaction and avoidance. This tool connects the allocation output of MRTA solvers to individual robot planning using the NAV2 stack and local, centralized multi-robot deconfliction using Control Barrier Function-Quadrtic Programs (CBF-QPs), creating a platform closer to real-world operation for more comprehensive testing of these approaches. The simulation architecture is modular so that users can swap out methods at different levels of the stack. We show the use of our system with a Satisfiability Modulo Theories (SMT)-based approach to dynamic MRTA on a fleet of indoor delivery robots.
Learning Smooth Humanoid Locomotion through Lipschitz-Constrained Policies
Oct 15, 2024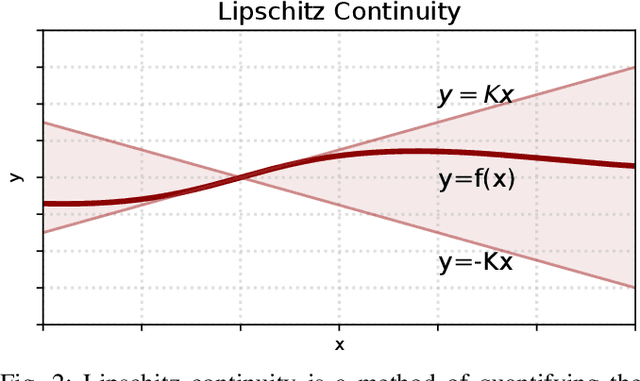
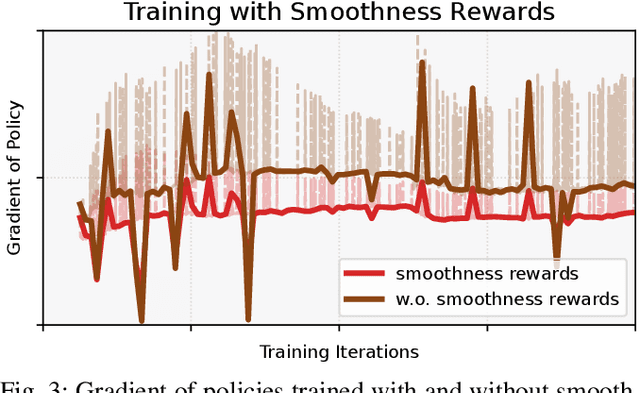
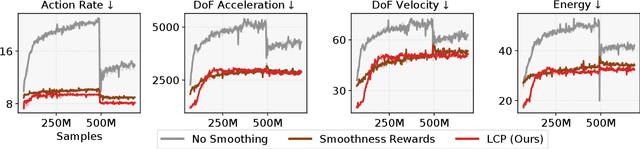
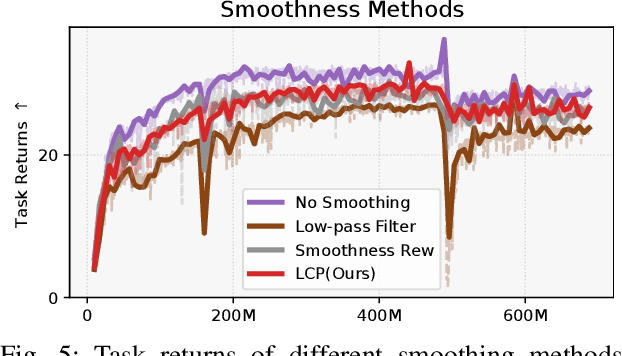
Reinforcement learning combined with sim-to-real transfer offers a general framework for developing locomotion controllers for legged robots. To facilitate successful deployment in the real world, smoothing techniques, such as low-pass filters and smoothness rewards, are often employed to develop policies with smooth behaviors. However, because these techniques are non-differentiable and usually require tedious tuning of a large set of hyperparameters, they tend to require extensive manual tuning for each robotic platform. To address this challenge and establish a general technique for enforcing smooth behaviors, we propose a simple and effective method that imposes a Lipschitz constraint on a learned policy, which we refer to as Lipschitz-Constrained Policies (LCP). We show that the Lipschitz constraint can be implemented in the form of a gradient penalty, which provides a differentiable objective that can be easily incorporated with automatic differentiation frameworks. We demonstrate that LCP effectively replaces the need for smoothing rewards or low-pass filters and can be easily integrated into training frameworks for many distinct humanoid robots. We extensively evaluate LCP in both simulation and real-world humanoid robots, producing smooth and robust locomotion controllers. All simulation and deployment code, along with complete checkpoints, is available on our project page: https://lipschitz-constrained-policy.github.io.
SMT-Based Dynamic Multi-Robot Task Allocation
Mar 18, 2024



Multi-Robot Task Allocation (MRTA) is a problem that arises in many application domains including package delivery, warehouse robotics, and healthcare. In this work, we consider the problem of MRTA for a dynamic stream of tasks with task deadlines and capacitated agents (capacity for more than one simultaneous task). Previous work commonly focuses on the static case, uses specialized algorithms for restrictive task specifications, or lacks guarantees. We propose an approach to Dynamic MRTA for capacitated robots that is based on Satisfiability Modulo Theories (SMT) solving and addresses these concerns. We show our approach is both sound and complete, and that the SMT encoding is general, enabling extension to a broader class of task specifications. We show how to leverage the incremental solving capabilities of SMT solvers, keeping learned information when allocating new tasks arriving online, and to solve non-incrementally, which we provide runtime comparisons of. Additionally, we provide an algorithm to start with a smaller but potentially incomplete encoding that can iteratively be adjusted to the complete encoding. We evaluate our method on a parameterized set of benchmarks encoding multi-robot delivery created from a graph abstraction of a hospital-like environment. The effectiveness of our approach is demonstrated using a range of encodings, including quantifier-free theories of uninterpreted functions and linear or bitvector arithmetic across multiple solvers.
Role of Uncertainty in Anticipatory Trajectory Prediction for a Ping-Pong Playing Robot
Dec 05, 2023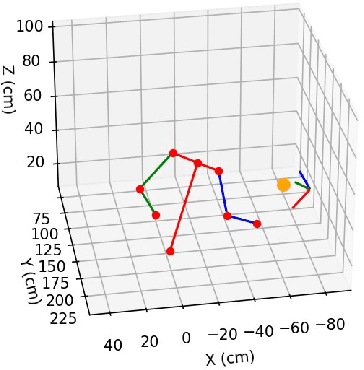
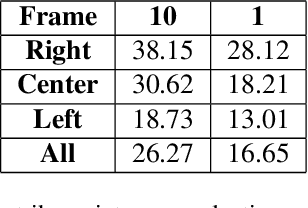

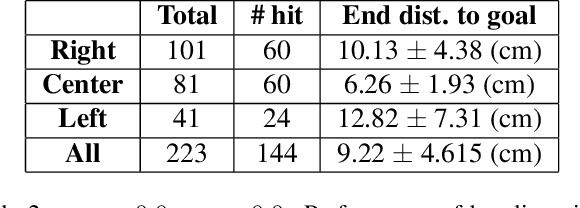
Robotic interaction in fast-paced environments presents a substantial challenge, particularly in tasks requiring the prediction of dynamic, non-stationary objects for timely and accurate responses. An example of such a task is ping-pong, where the physical limitations of a robot may prevent it from reaching its goal in the time it takes the ball to cross the table. The scene of a ping-pong match contains rich visual information of a player's movement that can allow future game state prediction, with varying degrees of uncertainty. To this aim, we present a visual modeling, prediction, and control system to inform a ping-pong playing robot utilizing visual model uncertainty to allow earlier motion of the robot throughout the game. We present demonstrations and metrics in simulation to show the benefit of incorporating model uncertainty, the limitations of current standard model uncertainty estimators, and the need for more verifiable model uncertainty estimation. Our code is publicly available.
DEC-LOS-RRT: Decentralized Path Planning for Multi-robot Systems with Line-of-sight Constrained Communication
Mar 04, 2022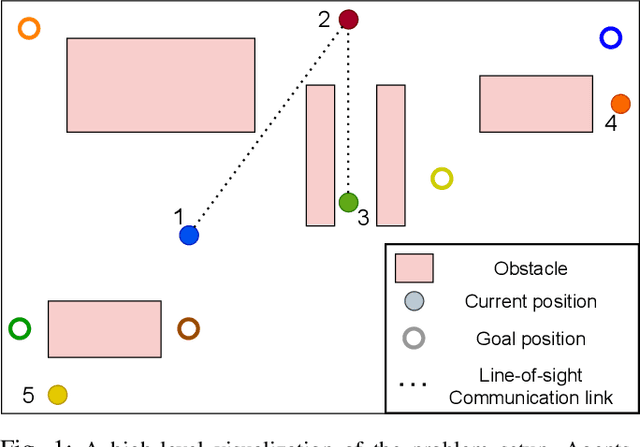
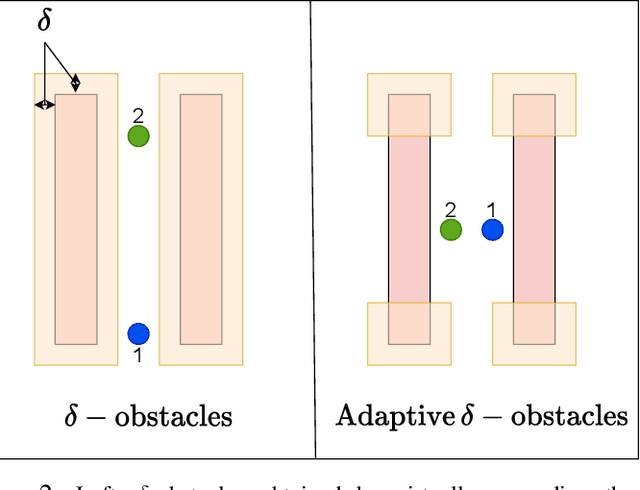
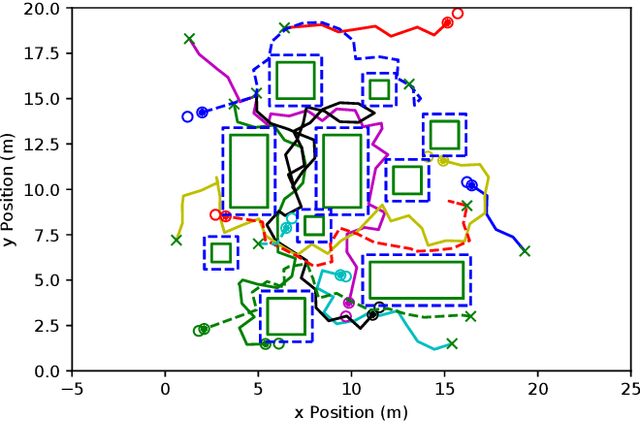
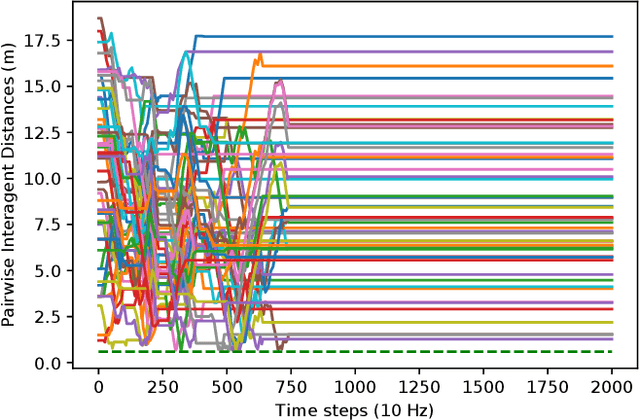
Decentralized planning for multi-agent systems, such as fleets of robots in a search-and-rescue operation, is often constrained by limitations on how agents can communicate with each other. One such limitation is the case when agents can communicate with each other only when they are in line-of-sight (LOS). Developing decentralized planning methods that guarantee safety is difficult in this case, as agents that are occluded from each other might not be able to communicate until it's too late to avoid a safety violation. In this paper, we develop a decentralized planning method that explicitly avoids situations where lack of visibility of other agents would lead to an unsafe situation. Building on top of an existing Rapidly-exploring Random Tree (RRT)-based approach, our method guarantees safety at each iteration. Simulation studies show the effectiveness of our method and compare the degradation in performance with respect to a clairvoyant decentralized planning algorithm where agents can communicate despite not being in LOS of each other.
* 8 pages, 8 figures, Presented at CCTA 2022
Who Leads and Who Follows in Strategic Classification?
Jun 23, 2021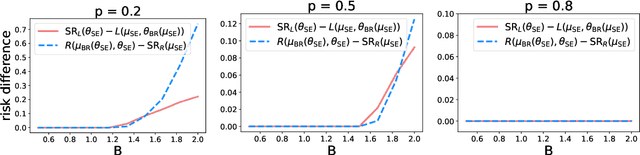
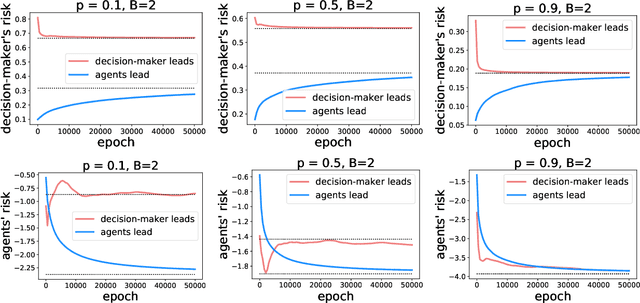
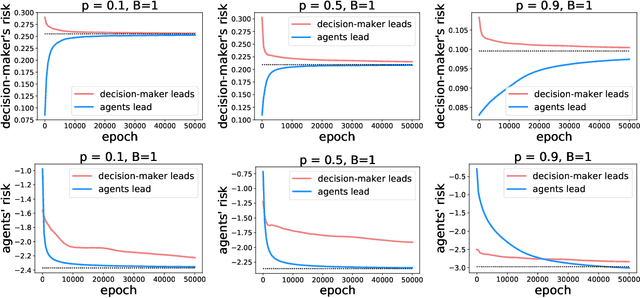
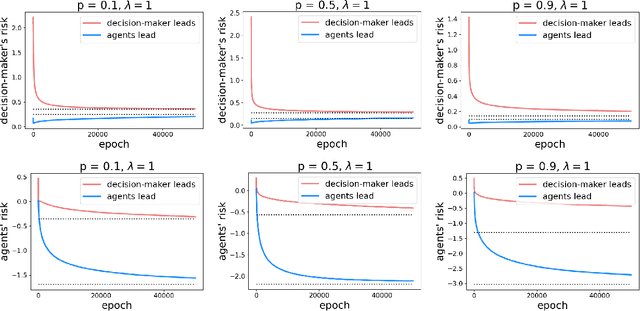
As predictive models are deployed into the real world, they must increasingly contend with strategic behavior. A growing body of work on strategic classification treats this problem as a Stackelberg game: the decision-maker "leads" in the game by deploying a model, and the strategic agents "follow" by playing their best response to the deployed model. Importantly, in this framing, the burden of learning is placed solely on the decision-maker, while the agents' best responses are implicitly treated as instantaneous. In this work, we argue that the order of play in strategic classification is fundamentally determined by the relative frequencies at which the decision-maker and the agents adapt to each other's actions. In particular, by generalizing the standard model to allow both players to learn over time, we show that a decision-maker that makes updates faster than the agents can reverse the order of play, meaning that the agents lead and the decision-maker follows. We observe in standard learning settings that such a role reversal can be desirable for both the decision-maker and the strategic agents. Finally, we show that a decision-maker with the freedom to choose their update frequency can induce learning dynamics that converge to Stackelberg equilibria with either order of play.
Zeroth-Order Methods for Convex-Concave Minmax Problems: Applications to Decision-Dependent Risk Minimization
Jun 16, 2021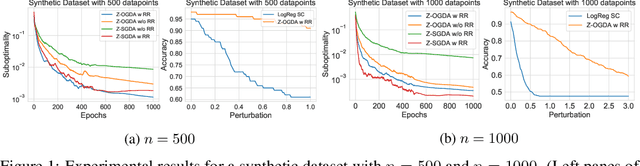

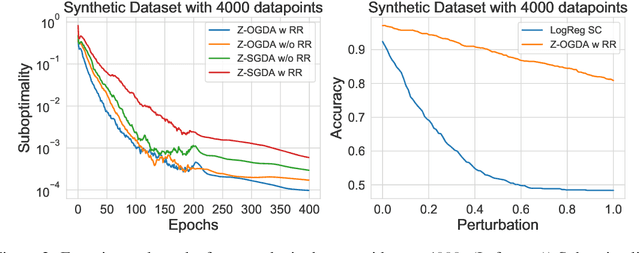
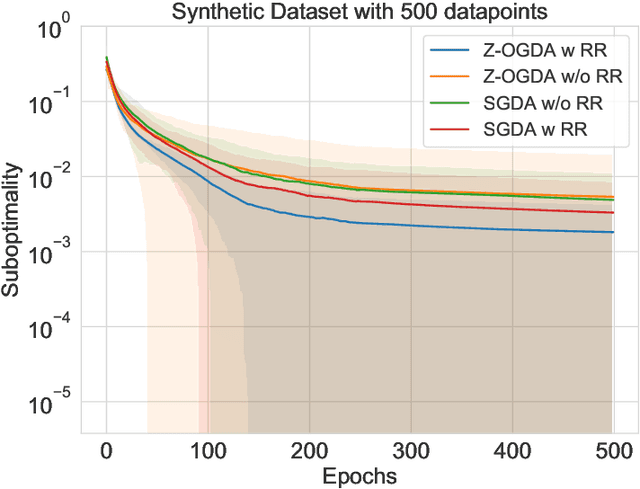
Min-max optimization is emerging as a key framework for analyzing problems of robustness to strategically and adversarially generated data. We propose a random reshuffling-based gradient free Optimistic Gradient Descent-Ascent algorithm for solving convex-concave min-max problems with finite sum structure. We prove that the algorithm enjoys the same convergence rate as that of zeroth-order algorithms for convex minimization problems. We further specialize the algorithm to solve distributionally robust, decision-dependent learning problems, where gradient information is not readily available. Through illustrative simulations, we observe that our proposed approach learns models that are simultaneously robust against adversarial distribution shifts and strategic decisions from the data sources, and outperforms existing methods from the strategic classification literature.
On the Stability of Nonlinear Receding Horizon Control: A Geometric Perspective
Mar 27, 2021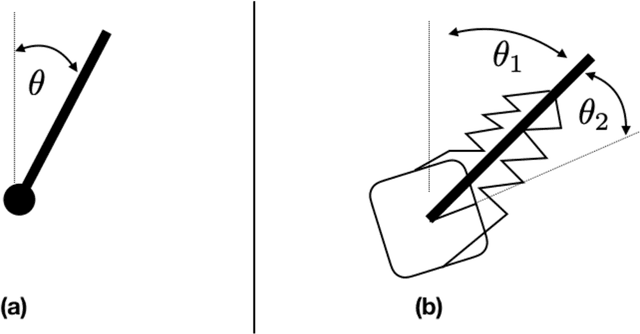
The widespread adoption of nonlinear Receding Horizon Control (RHC) strategies by industry has led to more than 30 years of intense research efforts to provide stability guarantees for these methods. However, current theoretical guarantees require that each (generally nonconvex) planning problem can be solved to (approximate) global optimality, which is an unrealistic requirement for the derivative-based local optimization methods generally used in practical implementations of RHC. This paper takes the first step towards understanding stability guarantees for nonlinear RHC when the inner planning problem is solved to first-order stationary points, but not necessarily global optima. Special attention is given to feedback linearizable systems, and a mixture of positive and negative results are provided. We establish that, under certain strong conditions, first-order solutions to RHC exponentially stabilize linearizable systems. Crucially, this guarantee requires that state costs applied to the planning problems are in a certain sense `compatible' with the global geometry of the system, and a simple counter-example demonstrates the necessity of this condition. These results highlight the need to rethink the role of global geometry in the context of optimization-based control.
Maximum Likelihood Constraint Inference from Stochastic Demonstrations
Feb 24, 2021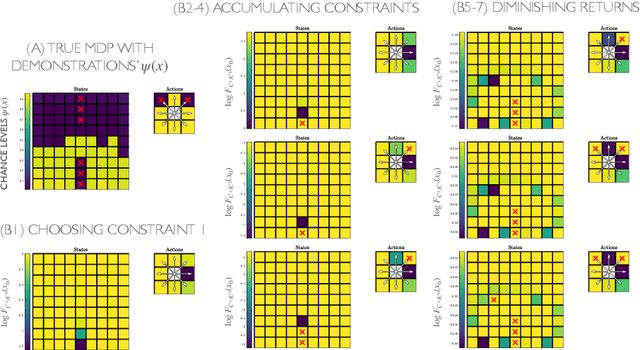
When an expert operates a perilous dynamic system, ideal constraint information is tacitly contained in their demonstrated trajectories and controls. The likelihood of these demonstrations can be computed, given the system dynamics and task objective, and the maximum likelihood constraints can be identified. Prior constraint inference work has focused mainly on deterministic models. Stochastic models, however, can capture the uncertainty and risk tolerance that are often present in real systems of interest. This paper extends maximum likelihood constraint inference to stochastic applications by using maximum causal entropy likelihoods. Furthermore, we propose an efficient algorithm that computes constraint likelihood and risk tolerance in a unified Bellman backup, allowing us to generalize to stochastic systems without increasing computational complexity.