 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Grounding of Large Language Models from Perception Streams
Apr 08, 2026Embodied-AI agents must reason about how objects move and interact in 3-D space over time, yet existing smaller frontier Large Language Models (LLMs) still mis-handle fine-grained spatial relations, metric distances, and temporal orderings. We introduce the general framework Formally Explainable Spatio-Temporal Scenes (FESTS) that injects verifiable spatio-temporal supervision into an LLM by compiling natural-language queries into Spatial Regular Expression (SpRE) -- a language combining regular expression syntax with S4u spatial logic and extended here with universal and existential quantification. The pipeline matches each SpRE against any structured video log and exports aligned (query, frames, match, explanation) tuples, enabling unlimited training data without manual labels. Training a 3-billion-parameter model on 27k such tuples boosts frame-level F1 from 48.5% to 87.5%, matching GPT-4.1 on complex spatio-temporal reasoning while remaining two orders of magnitude smaller, and, hence, enabling spatio-temporal intelligence for Video LLM.
Performance-Guided Refinement for Visual Aerial Navigation using Editable Gaussian Splatting in FalconGym 2.0
Oct 02, 2025Visual policy design is crucial for aerial navigation. However, state-of-the-art visual policies often overfit to a single track and their performance degrades when track geometry changes. We develop FalconGym 2.0, a photorealistic simulation framework built on Gaussian Splatting (GSplat) with an Edit API that programmatically generates diverse static and dynamic tracks in milliseconds. Leveraging FalconGym 2.0's editability, we propose a Performance-Guided Refinement (PGR) algorithm, which concentrates visual policy's training on challenging tracks while iteratively improving its performance. Across two case studies (fixed-wing UAVs and quadrotors) with distinct dynamics and environments, we show that a single visual policy trained with PGR in FalconGym 2.0 outperforms state-of-the-art baselines in generalization and robustness: it generalizes to three unseen tracks with 100% success without per-track retraining and maintains higher success rates under gate-pose perturbations. Finally, we demonstrate that the visual policy trained with PGR in FalconGym 2.0 can be zero-shot sim-to-real transferred to a quadrotor hardware, achieving a 98.6% success rate (69 / 70 gates) over 30 trials spanning two three-gate tracks and a moving-gate track.
BR-MPPI: Barrier Rate guided MPPI for Enforcing Multiple Inequality Constraints with Learned Signed Distance Field
Jun 08, 2025Model Predictive Path Integral (MPPI) controller is used to solve unconstrained optimal control problems and Control Barrier Function (CBF) is a tool to impose strict inequality constraints, a.k.a, barrier constraints. In this work, we propose an integration of these two methods that employ CBF-like conditions to guide the control sampling procedure of MPPI. CBFs provide an inequality constraint restricting the rate of change of barrier functions by a classK function of the barrier itself. We instead impose the CBF condition as an equality constraint by choosing a parametric linear classK function and treating this parameter as a state in an augmented system. The time derivative of this parameter acts as an additional control input that is designed by MPPI. A cost function is further designed to reignite Nagumo's theorem at the boundary of the safe set by promoting specific values of classK parameter to enforce safety. Our problem formulation results in an MPPI subject to multiple state and control-dependent equality constraints which are non-trivial to satisfy with randomly sampled control inputs. We therefore also introduce state transformations and control projection operations, inspired by the literature on path planning for manifolds, to resolve the aforementioned issue. We show empirically through simulations and experiments on quadrotor that our proposed algorithm exhibits better sampled efficiency and enhanced capability to operate closer to the safe set boundary over vanilla MPPI.
MRTA-Sim: A Modular Simulator for Multi-Robot Allocation, Planning, and Control in Open-World Environments
Apr 21, 2025



This paper introduces MRTA-Sim, a Python/ROS2/Gazebo simulator for testing approaches to Multi-Robot Task Allocation (MRTA) problems on simulated robots in complex, indoor environments. Grid-based approaches to MRTA problems can be too restrictive for use in complex, dynamic environments such in warehouses, department stores, hospitals, etc. However, approaches that operate in free-space often operate at a layer of abstraction above the control and planning layers of a robot and make an assumption on approximate travel time between points of interest in the system. These abstractions can neglect the impact of the tight space and multi-agent interactions on the quality of the solution. Therefore, MRTA solutions should be tested with the navigation stacks of the robots in mind, taking into account robot planning, conflict avoidance between robots, and human interaction and avoidance. This tool connects the allocation output of MRTA solvers to individual robot planning using the NAV2 stack and local, centralized multi-robot deconfliction using Control Barrier Function-Quadrtic Programs (CBF-QPs), creating a platform closer to real-world operation for more comprehensive testing of these approaches. The simulation architecture is modular so that users can swap out methods at different levels of the stack. We show the use of our system with a Satisfiability Modulo Theories (SMT)-based approach to dynamic MRTA on a fleet of indoor delivery robots.
Safe Navigation in Uncertain Crowded Environments Using Risk Adaptive CVaR Barrier Functions
Apr 09, 2025Robot navigation in dynamic, crowded environments poses a significant challenge due to the inherent uncertainties in the obstacle model. In this work, we propose a risk-adaptive approach based on the Conditional Value-at-Risk Barrier Function (CVaR-BF), where the risk level is automatically adjusted to accept the minimum necessary risk, achieving a good performance in terms of safety and optimization feasibility under uncertainty. Additionally, we introduce a dynamic zone-based barrier function which characterizes the collision likelihood by evaluating the relative state between the robot and the obstacle. By integrating risk adaptation with this new function, our approach adaptively expands the safety margin, enabling the robot to proactively avoid obstacles in highly dynamic environments. Comparisons and ablation studies demonstrate that our method outperforms existing social navigation approaches, and validate the effectiveness of our proposed framework.
From Dashcam Videos to Driving Simulations: Stress Testing Automated Vehicles against Rare Events
Nov 25, 2024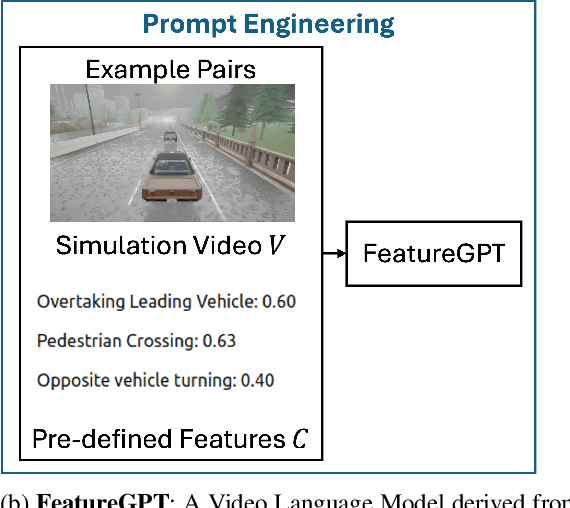
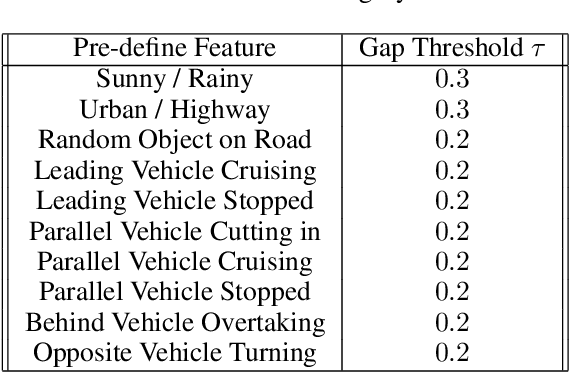

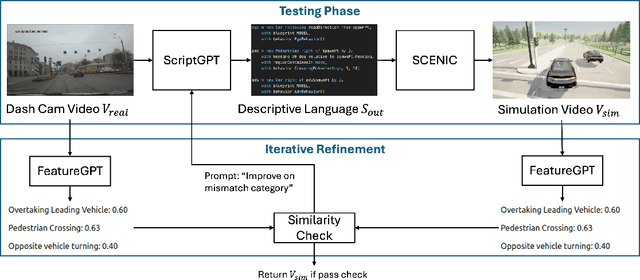
Testing Automated Driving Systems (ADS) in simulation with realistic driving scenarios is important for verifying their performance. However, converting real-world driving videos into simulation scenarios is a significant challenge due to the complexity of interpreting high-dimensional video data and the time-consuming nature of precise manual scenario reconstruction. In this work, we propose a novel framework that automates the conversion of real-world car crash videos into detailed simulation scenarios for ADS testing. Our approach leverages prompt-engineered Video Language Models(VLM) to transform dashcam footage into SCENIC scripts, which define the environment and driving behaviors in the CARLA simulator, enabling the generation of realistic simulation scenarios. Importantly, rather than solely aiming for one-to-one scenario reconstruction, our framework focuses on capturing the essential driving behaviors from the original video while offering flexibility in parameters such as weather or road conditions to facilitate search-based testing. Additionally, we introduce a similarity metric that helps iteratively refine the generated scenario through feedback by comparing key features of driving behaviors between the real and simulated videos. Our preliminary results demonstrate substantial time efficiency, finishing the real-to-sim conversion in minutes with full automation and no human intervention, while maintaining high fidelity to the original driving events.
Risk-aware MPPI for Stochastic Hybrid Systems
Nov 14, 2024



Path Planning for stochastic hybrid systems presents a unique challenge of predicting distributions of future states subject to a state-dependent dynamics switching function. In this work, we propose a variant of Model Predictive Path Integral Control (MPPI) to plan kinodynamic paths for such systems. Monte Carlo may be inaccurate when few samples are chosen to predict future states under state-dependent disturbances. We employ recently proposed Unscented Transform-based methods to capture stochasticity in the states as well as the state-dependent switching surfaces. This is in contrast to previous works that perform switching based only on the mean of predicted states. We focus our motion planning application on the navigation of a mobile robot in the presence of dynamically moving agents whose responses are based on sensor-constrained attention zones. We evaluate our framework on a simulated mobile robot and show faster convergence to a goal without collisions when the robot exploits the hybrid human dynamics versus when it does not.
Querying Perception Streams with Spatial Regular Expressions
Nov 08, 2024



Perception in fields like robotics, manufacturing, and data analysis generates large volumes of temporal and spatial data to effectively capture their environments. However, sorting through this data for specific scenarios is a meticulous and error-prone process, often dependent on the application, and lacks generality and reproducibility. In this work, we introduce SpREs as a novel querying language for pattern matching over perception streams containing spatial and temporal data derived from multi-modal dynamic environments. To highlight the capabilities of SpREs, we developed the STREM tool as both an offline and online pattern matching framework for perception data. We demonstrate the offline capabilities of STREM through a case study on a publicly available AV dataset (Woven Planet Perception) and its online capabilities through a case study integrating STREM in ROS with the CARLA simulator. We also conduct performance benchmark experiments on various SpRE queries. Using our matching framework, we are able to find over 20,000 matches within 296 ms making STREM applicable in runtime monitoring applications.
Repairing Neural Networks for Safety in Robotic Systems using Predictive Models
Nov 07, 2024



This paper introduces a new method for safety-aware robot learning, focusing on repairing policies using predictive models. Our method combines behavioral cloning with neural network repair in a two-step supervised learning framework. It first learns a policy from expert demonstrations and then applies repair subject to predictive models to enforce safety constraints. The predictive models can encompass various aspects relevant to robot learning applications, such as proprioceptive states and collision likelihood. Our experimental results demonstrate that the learned policy successfully adheres to a predefined set of safety constraints on two applications: mobile robot navigation, and real-world lower-leg prostheses. Additionally, we have shown that our method effectively reduces repeated interaction with the robot, leading to substantial time savings during the learning process.
Neural Configuration Distance Function for Continuum Robot Control
Sep 20, 2024This paper presents a novel method for modeling the shape of a continuum robot as a Neural Configuration Euclidean Distance Function (N-CEDF). By learning separate distance fields for each link and combining them through the kinematics chain, the learned N-CEDF provides an accurate and computationally efficient representation of the robot's shape. The key advantage of a distance function representation of a continuum robot is that it enables efficient collision checking for motion planning in dynamic and cluttered environments, even with point-cloud observations. We integrate the N-CEDF into a Model Predictive Path Integral (MPPI) controller to generate safe trajectories. The proposed approach is validated for continuum robots with various links in several simulated environments with static and dynamic obstacles.