 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance-Guided Refinement for Visual Aerial Navigation using Editable Gaussian Splatting in FalconGym 2.0
Oct 02, 2025Visual policy design is crucial for aerial navigation. However, state-of-the-art visual policies often overfit to a single track and their performance degrades when track geometry changes. We develop FalconGym 2.0, a photorealistic simulation framework built on Gaussian Splatting (GSplat) with an Edit API that programmatically generates diverse static and dynamic tracks in milliseconds. Leveraging FalconGym 2.0's editability, we propose a Performance-Guided Refinement (PGR) algorithm, which concentrates visual policy's training on challenging tracks while iteratively improving its performance. Across two case studies (fixed-wing UAVs and quadrotors) with distinct dynamics and environments, we show that a single visual policy trained with PGR in FalconGym 2.0 outperforms state-of-the-art baselines in generalization and robustness: it generalizes to three unseen tracks with 100% success without per-track retraining and maintains higher success rates under gate-pose perturbations. Finally, we demonstrate that the visual policy trained with PGR in FalconGym 2.0 can be zero-shot sim-to-real transferred to a quadrotor hardware, achieving a 98.6% success rate (69 / 70 gates) over 30 trials spanning two three-gate tracks and a moving-gate track.
Towards Unified Probabilistic Verification and Validation of Vision-Based Autonomy
Aug 19, 2025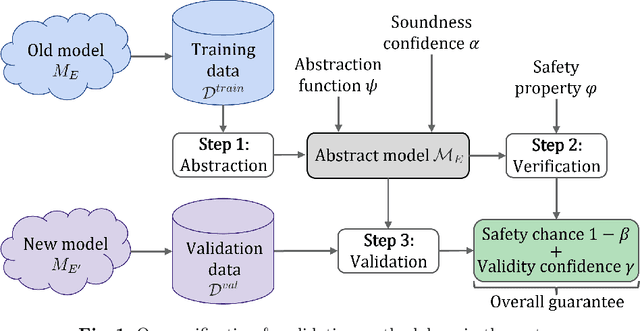
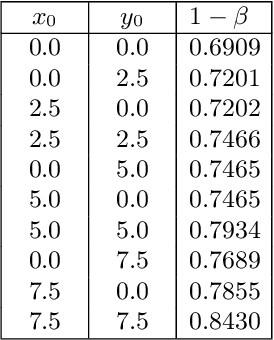
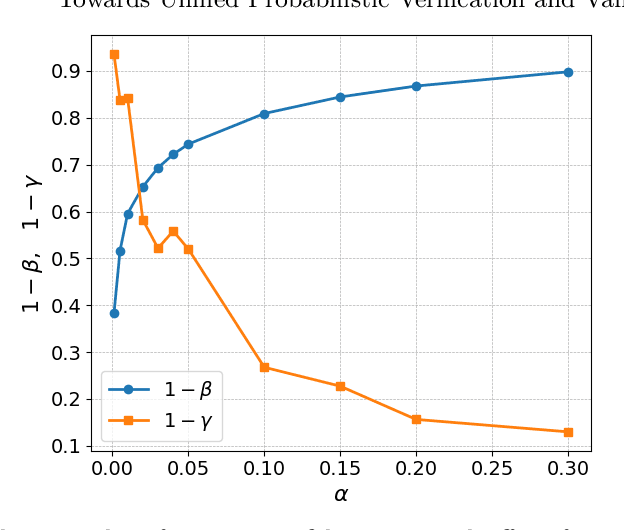
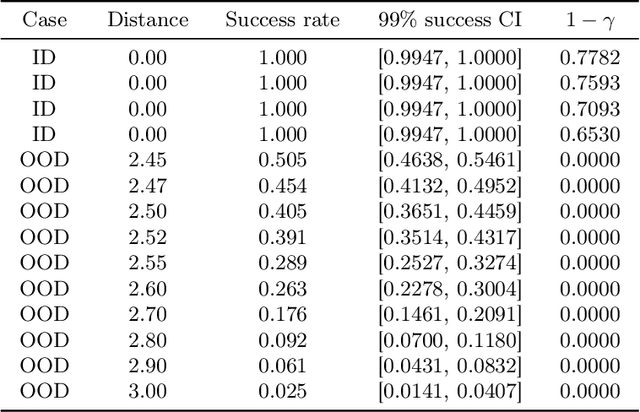
Precise and comprehensive situational awareness is a critical capability of modern autonomous systems. Deep neural networks that perceive task-critical details from rich sensory signals have become ubiquitous; however, their black-box behavior and sensitivity to environmental uncertainty and distribution shifts make them challenging to verify formally. Abstraction-based verification techniques for vision-based autonomy produce safety guarantees contingent on rigid assumptions, such as bounded errors or known unique distributions. Such overly restrictive and inflexible assumptions limit the validity of the guarantees, especially in diverse and uncertain test-time environments. We propose a methodology that unifies the verification models of perception with their offline validation. Our methodology leverages interval MDPs and provides a flexible end-to-end guarantee that adapts directly to the out-of-distribution test-time conditions. We evaluate our methodology on a synthetic perception Markov chain with well-defined state estimation distributions and a mountain car benchmark. Our findings reveal that we can guarantee tight yet rigorous bounds on overall system safety.
FalconWing: An Open-Source Platform for Ultra-Light Fixed-Wing Aircraft Research
May 02, 2025
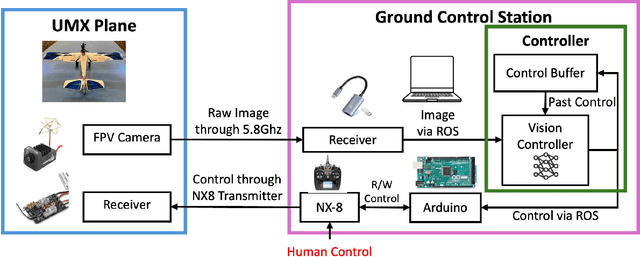


We present FalconWing -- an open-source, ultra-lightweight (150 g) fixed-wing platform for autonomy research. The hardware platform integrates a small camera, a standard airframe, offboard computation, and radio communication for manual overrides. We demonstrate FalconWing's capabilities by developing and deploying a purely vision-based control policy for autonomous landing (without IMU or motion capture) using a novel real-to-sim-to-real learning approach. Our learning approach: (1) constructs a photorealistic simulation environment via 3D Gaussian splatting trained on real-world images; (2) identifies nonlinear dynamics from vision-estimated real-flight data; and (3) trains a multi-modal Vision Transformer (ViT) policy through simulation-only imitation learning. The ViT architecture fuses single RGB image with the history of control actions via self-attention, preserving temporal context while maintaining real-time 20 Hz inference. When deployed zero-shot on the hardware platform, this policy achieves an 80% success rate in vision-based autonomous landings. Together with the hardware specifications, we also open-source the system dynamics, the software for photorealistic simulator and the learning approach.
Zero-Shot Sim-to-Real Visual Quadrotor Control with Hard Constraints
Mar 04, 2025



We present the first framework demonstrating zero-shot sim-to-real transfer of visual control policies learned in a Neural Radiance Field (NeRF) environment for quadrotors to fly through racing gates. Robust transfer from simulation to real flight poses a major challenge, as standard simulators often lack sufficient visual fidelity. To address this, we construct a photorealistic simulation environment of quadrotor racing tracks, called FalconGym, which provides effectively unlimited synthetic images for training. Within FalconGym, we develop a pipelined approach for crossing gates that combines (i) a Neural Pose Estimator (NPE) coupled with a Kalman filter to reliably infer quadrotor poses from single-frame RGB images and IMU data, and (ii) a self-attention-based multi-modal controller that adaptively integrates visual features and pose estimation. This multi-modal design compensates for perception noise and intermittent gate visibility. We train this controller purely in FalconGym with imitation learning and deploy the resulting policy to real hardware with no additional fine-tuning. Simulation experiments on three distinct tracks (circle, U-turn and figure-8) demonstrate that our controller outperforms a vision-only state-of-the-art baseline in both success rate and gate-crossing accuracy. In 30 live hardware flights spanning three tracks and 120 gates, our controller achieves a 95.8% success rate and an average error of just 10 cm when flying through 38 cm-radius gates.
From Dashcam Videos to Driving Simulations: Stress Testing Automated Vehicles against Rare Events
Nov 25, 2024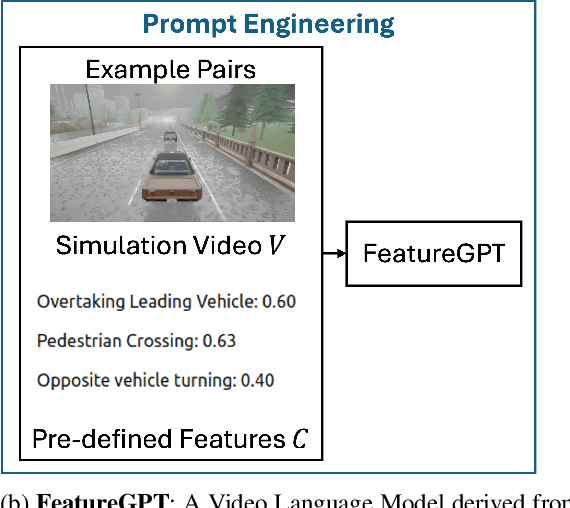
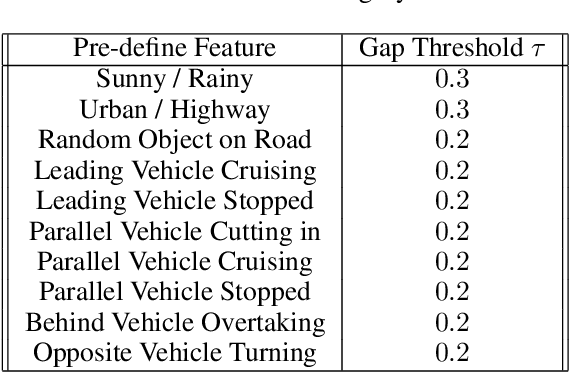

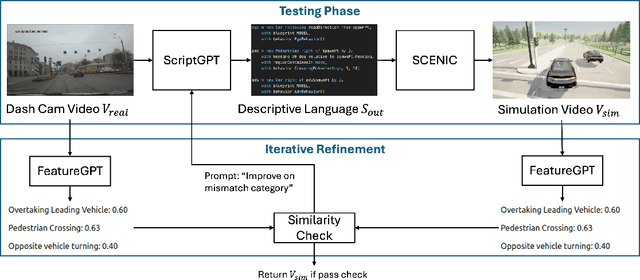
Testing Automated Driving Systems (ADS) in simulation with realistic driving scenarios is important for verifying their performance. However, converting real-world driving videos into simulation scenarios is a significant challenge due to the complexity of interpreting high-dimensional video data and the time-consuming nature of precise manual scenario reconstruction. In this work, we propose a novel framework that automates the conversion of real-world car crash videos into detailed simulation scenarios for ADS testing. Our approach leverages prompt-engineered Video Language Models(VLM) to transform dashcam footage into SCENIC scripts, which define the environment and driving behaviors in the CARLA simulator, enabling the generation of realistic simulation scenarios. Importantly, rather than solely aiming for one-to-one scenario reconstruction, our framework focuses on capturing the essential driving behaviors from the original video while offering flexibility in parameters such as weather or road conditions to facilitate search-based testing. Additionally, we introduce a similarity metric that helps iteratively refine the generated scenario through feedback by comparing key features of driving behaviors between the real and simulated videos. Our preliminary results demonstrate substantial time efficiency, finishing the real-to-sim conversion in minutes with full automation and no human intervention, while maintaining high fidelity to the original driving events.
MuST: Multimodal Spatiotemporal Graph-Transformer for Hospital Readmission Prediction
Nov 11, 2023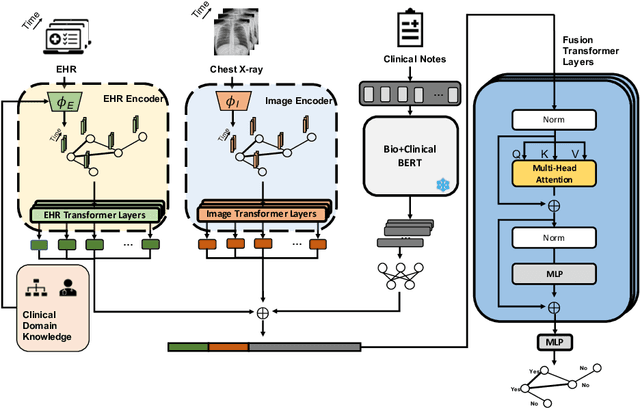


Hospital readmission prediction is considered an essential approach to decreasing readmission rates, which is a key factor in assessing the quality and efficacy of a healthcare system. Previous studies have extensively utilized three primary modalities, namely electronic health records (EHR), medical images, and clinical notes, to predict hospital readmissions. However, the majority of these studies did not integrate information from all three modalities or utilize the spatiotemporal relationships present in the dataset. This study introduces a novel model called the Multimodal Spatiotemporal Graph-Transformer (MuST) for predicting hospital readmissions. By employing Graph Convolution Networks and temporal transformers, we can effectively capture spatial and temporal dependencies in EHR and chest radiographs. We then propose a fusion transformer to combine the spatiotemporal features from the two modalities mentioned above with the features from clinical notes extracted by a pre-trained, domain-specific transformer. We assess the effectiveness of our methods using the latest publicly available dataset, MIMIC-IV. The experimental results indicate that the inclusion of multimodal features in MuST improves its performance in comparison to unimodal methods. Furthermore, our proposed pipeline outperforms the current leading methods in the prediction of hospital readmissions.
Watch out for the risky actors: Assessing risk in dynamic environments for safe driving
Oct 19, 2021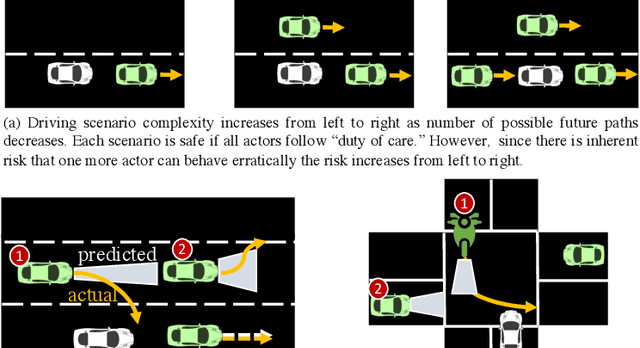
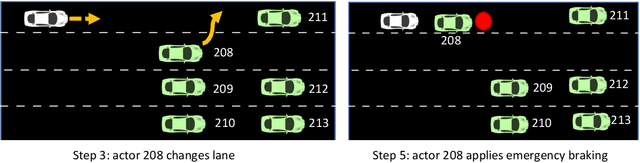
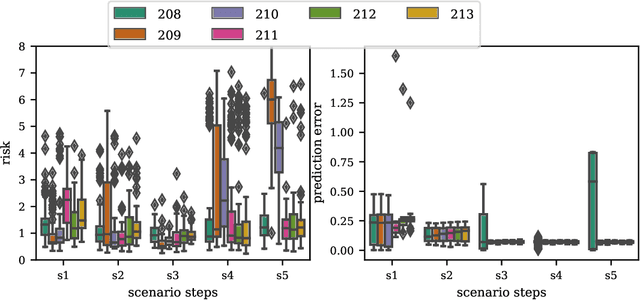
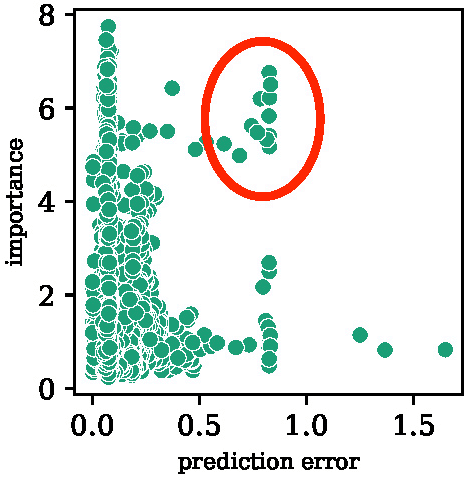
Driving in a dynamic environment that consists of other actors is inherently a risky task as each actor influences the driving decision and may significantly limit the number of choices in terms of navigation and safety plan. The risk encountered by the Ego actor depends on the driving scenario and the uncertainty associated with predicting the future trajectories of the other actors in the driving scenario. However, not all objects pose a similar risk. Depending on the object's type, trajectory, position, and the associated uncertainty with these quantities; some objects pose a much higher risk than others. The higher the risk associated with an actor, the more attention must be directed towards that actor in terms of resources and safety planning. In this paper, we propose a novel risk metric to calculate the importance of each actor in the world and demonstrate its usefulness through a case study.