 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Context Engineering Framework for Improving Enterprise AI Agents based on Digital-Twin MDP
Mar 23, 2026Despite rapid progress in AI agents for enterprise automation and decision-making, their real-world deployment and further performance gains remain constrained by limited data quality and quantity, complex real-world reasoning demands, difficulties with self-play, and the lack of reliable feedback signals. To address these challenges, we propose a lightweight, model-agnostic framework for improving LLM-based enterprise agents via offline reinforcement learning (RL). The proposed Context Engineering via DT-MDP (DT-MDP-CE) framework comprises three key components: (1) A Digital-Twin Markov Decision Process (DT-MDP), which abstracts the agent's reasoning behavior as a finite MDP; (2) A robust contrastive inverse RL, which, armed with the DT-MDP, to efficiently estimate a well-founded reward function and induces policies from mixed-quality offline trajectories; and (3) RL-guided context engineering, which uses the policy obtained from the integrated process of (1) and (2), to improve the agent's decision-making behavior. As a case study, we apply the framework to a representative task in the enterprise-oriented domain of IT automation. Extensive experimental results demonstrate consistent and significant improvements over baseline agents across a wide range of evaluation settings, suggesting that the framework can generalize to other agents sharing similar characteristics in enterprise environments.
RAMP: Reinforcement Adaptive Mixed Precision Quantization for Efficient On Device LLM Inference
Mar 18, 2026Post training quantization is essential for deploying large language models (LLMs) on resource constrained hardware, yet state of the art methods enforce uniform bit widths across layers, yielding suboptimal accuracy efficiency trade offs. We present RAMP (Reinforcement Adaptive Mixed Precision), an off policy Soft Actor Critic framework that learns per layer bit width assignments to minimize perplexity under a global bit budget. The policy conditions on an 11 dimensional embedding of activation statistics, weight properties, and structural descriptors, enabling zero shot transfer across model families and scales. To enable stable sub 4 bit quantization, we introduce Scale Folding, a preconditioning technique that migrates activation outliers into weights via per channel scaling and normalization layer compensation. A quality prioritized reward with asymmetric penalties and budget cliffs drives rapid convergence. On Llama 2 7B, RAMP achieves 5.54 perplexity at 3.68GB (3.65 effective bits), outperforming uniform 4 bit AWQ (5.60 at 3.90 GB) and GPTQ by 6% in size and 1% to3% in quality. Critically, a policy trained only on Llama 2 7B generalizes zero shot to Llama 2 13B and Mistral 7B, often surpassing target specific training, supporting the hypothesis that quantization sensitivity is primarily architectural. The HALO pipeline exports allocations to GGUF format for kernel free inference on CPUs, GPUs, and edge devices, retaining 99.5% of FP16 commonsense reasoning performance.
The Energy of Falsehood: Detecting Hallucinations via Diffusion Model Likelihoods
Feb 11, 2026Large Language Models (LLMs) frequently hallucinate plausible but incorrect assertions, a vulnerability often missed by uncertainty metrics when models are confidently wrong. We propose DiffuTruth, an unsupervised framework that reconceptualizes fact verification via non equilibrium thermodynamics, positing that factual truths act as stable attractors on a generative manifold while hallucinations are unstable. We introduce the Generative Stress Test, claims are corrupted with noise and reconstructed using a discrete text diffusion model. We define Semantic Energy, a metric measuring the semantic divergence between the original claim and its reconstruction using an NLI critic. Unlike vector space errors, Semantic Energy isolates deep factual contradictions. We further propose a Hybrid Calibration fusing this stability signal with discriminative confidence. Extensive experiments on FEVER demonstrate DiffuTruth achieves a state of the art unsupervised AUROC of 0.725, outperforming baselines by 1.5 percent through the correction of overconfident predictions. Furthermore, we show superior zero shot generalization on the multi hop HOVER dataset, outperforming baselines by over 4 percent, confirming the robustness of thermodynamic truth properties to distribution shifts.
Think Locally, Explain Globally: Graph-Guided LLM Investigations via Local Reasoning and Belief Propagation
Jan 25, 2026LLM agents excel when environments are mostly static and the needed information fits in a model's context window, but they often fail in open-ended investigations where explanations must be constructed by iteratively mining evidence from massive, heterogeneous operational data. These investigations exhibit hidden dependency structure: entities interact, signals co-vary, and the importance of a fact may only become clear after other evidence is discovered. Because the context window is bounded, agents must summarize intermediate findings before their significance is known, increasing the risk of discarding key evidence. ReAct-style agents are especially brittle in this regime. Their retrieve-summarize-reason loop makes conclusions sensitive to exploration order and introduces run-to-run non-determinism, producing a reliability gap where Pass-at-k may be high but Majority-at-k remains low. Simply sampling more rollouts or generating longer reasoning traces does not reliably stabilize results, since hypotheses cannot be autonomously checked as new evidence arrives and there is no explicit mechanism for belief bookkeeping and revision. In addition, ReAct entangles semantic reasoning with controller duties such as tool orchestration and state tracking, so execution errors and plan drift degrade reasoning while consuming scarce context. We address these issues by formulating investigation as abductive reasoning over a dependency graph and proposing EoG (Explanations over Graphs), a disaggregated framework in which an LLM performs bounded local evidence mining and labeling (cause vs symptom) while a deterministic controller manages traversal, state, and belief propagation to compute a minimal explanatory frontier. On a representative ITBench diagnostics task, EoG improves both accuracy and run-to-run consistency over ReAct baselines, including a 7x average gain in Majority-at-k entity F1.
Agentic Structured Graph Traversal for Root Cause Analysis of Code-related Incidents in Cloud Applications
Dec 26, 2025Cloud incidents pose major operational challenges in production, with unresolved production cloud incidents cost on average over $2M per hour. Prior research identifies code- and configuration-related issues as the predominant category of root causes in cloud incidents. This paper introduces PRAXIS, an orchestrator that manages and deploys an agentic workflow for diagnosing code- and configuration-caused cloud incidents. PRAXIS employs an LLM-driven structured traversal over two types of graph: (1) a service dependency graph (SDG) that captures microservice-level dependencies; and (2) a hammock-block program dependence graph (PDG) that captures code-level dependencies for each microservice. Together, these graphs encode microservice- and code-level dependencies and the LLM acts as a traversal policy over these graphs, moving between services and code dependencies to localize and explain failures. Compared to state-of-the-art ReAct baselines, PRAXIS improves RCA accuracy by up to 3.1x while reducing token consumption by 3.8x. PRAXIS is demonstrated on a set of 30 comprehensive real-world incidents that is being compiled into an RCA benchmark.
Characterizing GPU Resilience and Impact on AI/HPC Systems
Mar 14, 2025In this study, we characterize GPU failures in Delta, the current large-scale AI system with over 600 petaflops of peak compute throughput. The system comprises GPU and non-GPU nodes with modern AI accelerators, such as NVIDIA A40, A100, and H100 GPUs. The study uses two and a half years of data on GPU errors. We evaluate the resilience of GPU hardware components to determine the vulnerability of different GPU components to failure and their impact on the GPU and node availability. We measure the key propagation paths in GPU hardware, GPU interconnect (NVLink), and GPU memory. Finally, we evaluate the impact of the observed GPU errors on user jobs. Our key findings are: (i) Contrary to common beliefs, GPU memory is over 30x more reliable than GPU hardware in terms of MTBE (mean time between errors). (ii) The newly introduced GSP (GPU System Processor) is the most vulnerable GPU hardware component. (iii) NVLink errors did not always lead to user job failure, and we attribute it to the underlying error detection and retry mechanisms employed. (iv) We show multiple examples of hardware errors originating from one of the key GPU hardware components, leading to application failure. (v) We project the impact of GPU node availability on larger scales with emulation and find that significant overprovisioning between 5-20% would be necessary to handle GPU failures. If GPU availability were improved to 99.9%, the overprovisioning would be reduced by 4x.
Causal AI-based Root Cause Identification: Research to Practice at Scale
Feb 25, 2025



Modern applications are built as large, distributed systems spanning numerous modules, teams, and data centers. Despite robust engineering and recovery strategies, failures and performance issues remain inevitable, risking significant disruptions and affecting end users. Rapid and accurate root cause identification is therefore vital to ensure system reliability and maintain key service metrics. We have developed a novel causality-based Root Cause Identification (RCI) algorithm that emphasizes causation over correlation. This algorithm has been integrated into IBM Instana-bridging research to practice at scale-and is now in production use by enterprise customers. By leveraging "causal AI," Instana stands apart from typical Application Performance Management (APM) tools, pinpointing issues in near real-time. This paper highlights Instana's advanced failure diagnosis capabilities, discussing both the theoretical underpinnings and practical implementations of the RCI algorithm. Real-world examples illustrate how our causality-based approach enhances reliability and performance in today's complex system landscapes.
ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks
Feb 07, 2025



Realizing the vision of using AI agents to automate critical IT tasks depends on the ability to measure and understand effectiveness of proposed solutions. We introduce ITBench, a framework that offers a systematic methodology for benchmarking AI agents to address real-world IT automation tasks. Our initial release targets three key areas: Site Reliability Engineering (SRE), Compliance and Security Operations (CISO), and Financial Operations (FinOps). The design enables AI researchers to understand the challenges and opportunities of AI agents for IT automation with push-button workflows and interpretable metrics. ITBench includes an initial set of 94 real-world scenarios, which can be easily extended by community contributions. Our results show that agents powered by state-of-the-art models resolve only 13.8% of SRE scenarios, 25.2% of CISO scenarios, and 0% of FinOps scenarios. We expect ITBench to be a key enabler of AI-driven IT automation that is correct, safe, and fast.
Hierarchical Autoscaling for Large Language Model Serving with Chiron
Jan 14, 2025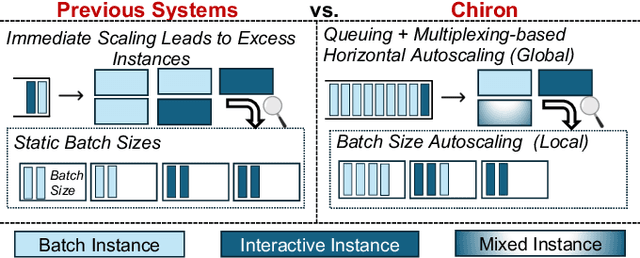
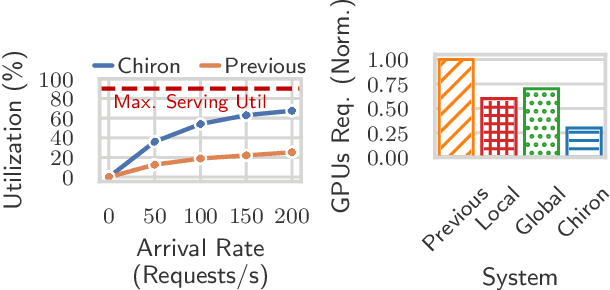
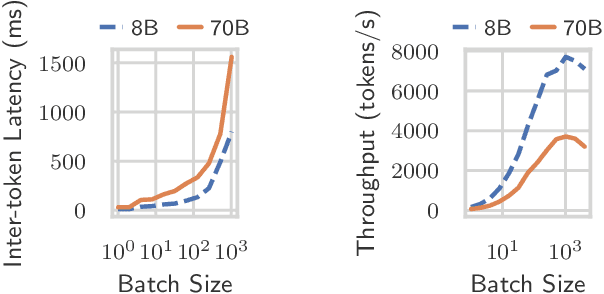

Large language model (LLM) serving is becoming an increasingly important workload for cloud providers. Based on performance SLO requirements, LLM inference requests can be divided into (a) interactive requests that have tight SLOs in the order of seconds, and (b) batch requests that have relaxed SLO in the order of minutes to hours. These SLOs can degrade based on the arrival rates, multiplexing, and configuration parameters, thus necessitating the use of resource autoscaling on serving instances and their batch sizes. However, previous autoscalers for LLM serving do not consider request SLOs leading to unnecessary scaling and resource under-utilization. To address these limitations, we introduce Chiron, an autoscaler that uses the idea of hierarchical backpressure estimated using queue size, utilization, and SLOs. Our experiments show that Chiron achieves up to 90% higher SLO attainment and improves GPU efficiency by up to 70% compared to existing solutions.
Efficient Interactive LLM Serving with Proxy Model-based Sequence Length Prediction
Apr 12, 2024Large language models (LLMs) have been driving a new wave of interactive AI applications across numerous domains. However, efficiently serving LLM inference requests is challenging due to their unpredictable execution times originating from the autoregressive nature of generative models. Existing LLM serving systems exploit first-come-first-serve (FCFS) scheduling, suffering from head-of-line blocking issues. To address the non-deterministic nature of LLMs and enable efficient interactive LLM serving, we present a speculative shortest-job-first (SSJF) scheduler that uses a light proxy model to predict LLM output sequence lengths. Our open-source SSJF implementation does not require changes to memory management or batching strategies. Evaluations on real-world datasets and production workload traces show that SSJF reduces average job completion times by 30.5-39.6% and increases throughput by 2.2-3.6x compared to FCFS schedulers, across no batching, dynamic batching, and continuous batching settings.