 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Stage Huffman Encoder for ML Compression
Jan 15, 2026Training and serving Large Language Models (LLMs) require partitioning data across multiple accelerators, where collective operations are frequently bottlenecked by network bandwidth. Lossless compression using Huffman codes is an effective way to alleviate the issue, however, its three-stage design requiring on-the-fly frequency analysis, codebook generation and transmission of codebook along with data introduces computational, latency and data overheads which are prohibitive for latency-sensitive scenarios such as die-to-die communication. This paper proposes a single-stage Huffman encoder that eliminates these overheads by using fixed codebooks derived from the average probability distribution of previous data batches. Through our analysis of the Gemma 2B model, we demonstrate that tensors exhibit high statistical similarity across layers and shards. Using this approach we achieve compression within 0.5% of per-shard Huffman coding and within 1% of the ideal Shannon compressibility, enabling efficient on-the-fly compression.
AI and the Future of Digital Public Squares
Dec 13, 2024



Two substantial technological advances have reshaped the public square in recent decades: first with the advent of the internet and second with the recent introduction of large language models (LLMs). LLMs offer opportunities for a paradigm shift towards more decentralized, participatory online spaces that can be used to facilitate deliberative dialogues at scale, but also create risks of exacerbating societal schisms. Here, we explore four applications of LLMs to improve digital public squares: collective dialogue systems, bridging systems, community moderation, and proof-of-humanity systems. Building on the input from over 70 civil society experts and technologists, we argue that LLMs both afford promising opportunities to shift the paradigm for conversations at scale and pose distinct risks for digital public squares. We lay out an agenda for future research and investments in AI that will strengthen digital public squares and safeguard against potential misuses of AI.
Mem-Rec: Memory Efficient Recommendation System using Alternative Representation
May 15, 2023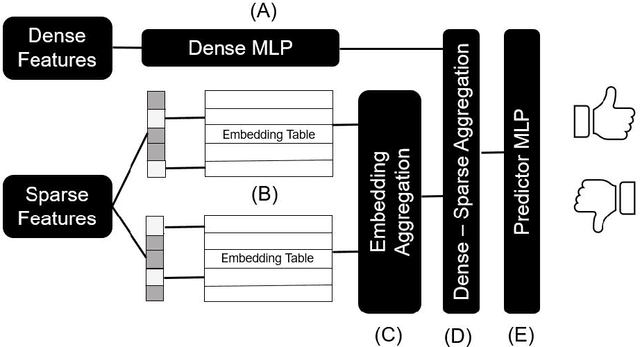
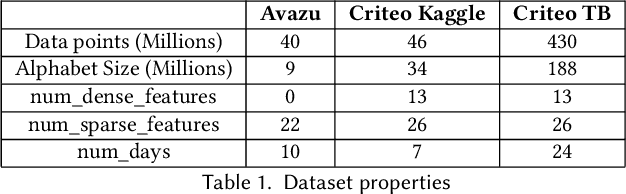
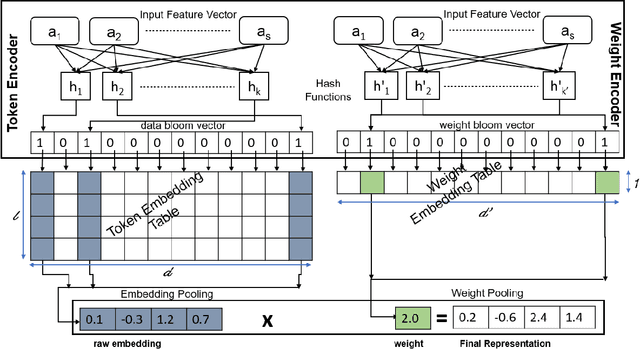
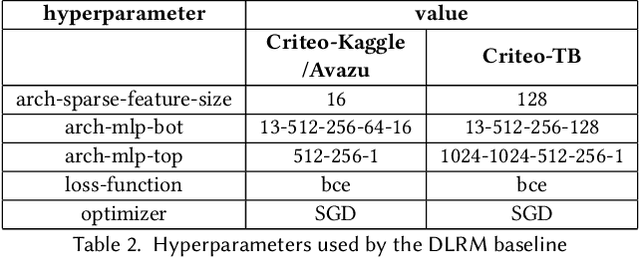
Deep learning-based recommendation systems (e.g., DLRMs) are widely used AI models to provide high-quality personalized recommendations. Training data used for modern recommendation systems commonly includes categorical features taking on tens-of-millions of possible distinct values. These categorical tokens are typically assigned learned vector representations, that are stored in large embedding tables, on the order of 100s of GB. Storing and accessing these tables represent a substantial burden in commercial deployments. Our work proposes MEM-REC, a novel alternative representation approach for embedding tables. MEM-REC leverages bloom filters and hashing methods to encode categorical features using two cache-friendly embedding tables. The first table (token embedding) contains raw embeddings (i.e. learned vector representation), and the second table (weight embedding), which is much smaller, contains weights to scale these raw embeddings to provide better discriminative capability to each data point. We provide a detailed architecture, design and analysis of MEM-REC addressing trade-offs in accuracy and computation requirements, in comparison with state-of-the-art techniques. We show that MEM-REC can not only maintain the recommendation quality and significantly reduce the memory footprint for commercial scale recommendation models but can also improve the embedding latency. In particular, based on our results, MEM-REC compresses the MLPerf CriteoTB benchmark DLRM model size by 2900x and performs up to 3.4x faster embeddings while achieving the same AUC as that of the full uncompressed model.
RAPID: Enabling Fast Online Policy Learning in Dynamic Public Cloud Environments
Apr 10, 2023



Resource sharing between multiple workloads has become a prominent practice among cloud service providers, motivated by demand for improved resource utilization and reduced cost of ownership. Effective resource sharing, however, remains an open challenge due to the adverse effects that resource contention can have on high-priority, user-facing workloads with strict Quality of Service (QoS) requirements. Although recent approaches have demonstrated promising results, those works remain largely impractical in public cloud environments since workloads are not known in advance and may only run for a brief period, thus prohibiting offline learning and significantly hindering online learning. In this paper, we propose RAPID, a novel framework for fast, fully-online resource allocation policy learning in highly dynamic operating environments. RAPID leverages lightweight QoS predictions, enabled by domain-knowledge-inspired techniques for sample efficiency and bias reduction, to decouple control from conventional feedback sources and guide policy learning at a rate orders of magnitude faster than prior work. Evaluation on a real-world server platform with representative cloud workloads confirms that RAPID can learn stable resource allocation policies in minutes, as compared with hours in prior state-of-the-art, while improving QoS by 9.0x and increasing best-effort workload performance by 19-43%.
Streaming Encoding Algorithms for Scalable Hyperdimensional Computing
Sep 28, 2022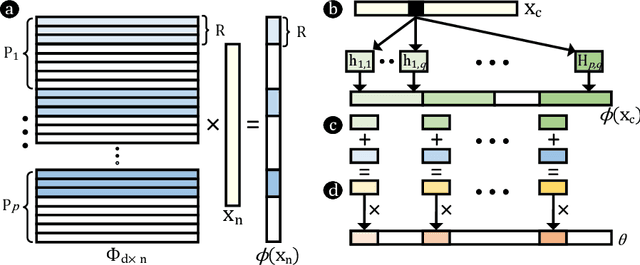


Hyperdimensional computing (HDC) is a paradigm for data representation and learning originating in computational neuroscience. HDC represents data as high-dimensional, low-precision vectors which can be used for a variety of information processing tasks like learning or recall. The mapping to high-dimensional space is a fundamental problem in HDC, and existing methods encounter scalability issues when the input data itself is high-dimensional. In this work, we explore a family of streaming encoding techniques based on hashing. We show formally that these methods enjoy comparable guarantees on performance for learning applications while being substantially more efficient than existing alternatives. We validate these results experimentally on a popular high-dimensional classification problem and show that our approach easily scales to very large data sets.
Evolving Zero Cost Proxies For Neural Architecture Scoring
Sep 15, 2022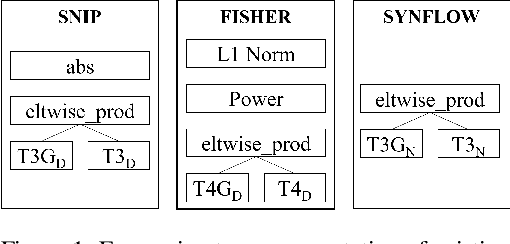
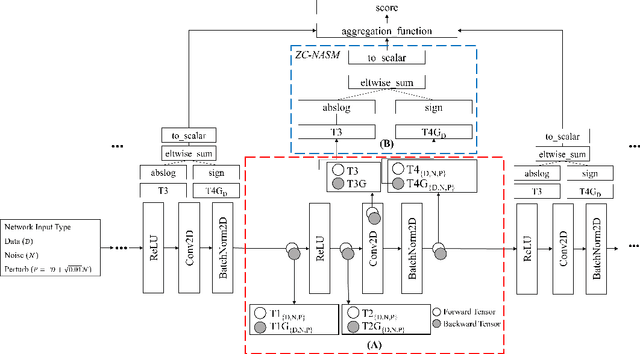
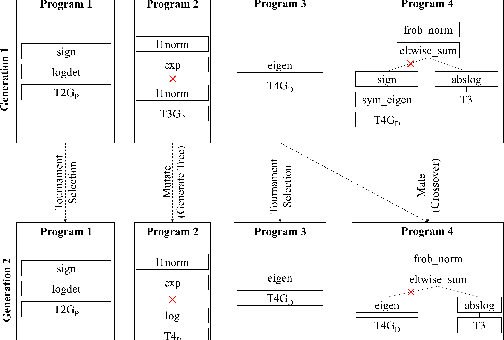
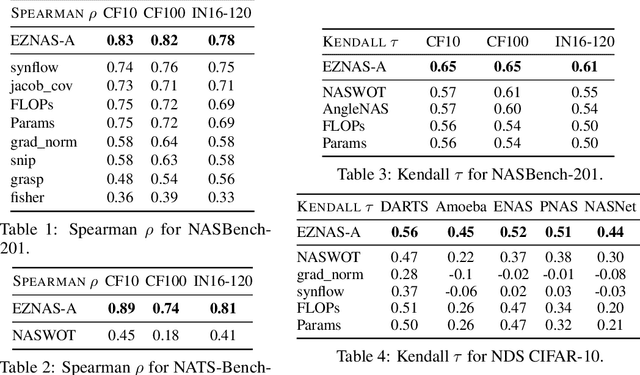
Neural Architecture Search (NAS) has significantly improved productivity in the design and deployment of neural networks (NN). As NAS typically evaluates multiple models by training them partially or completely, the improved productivity comes at the cost of significant carbon footprint. To alleviate this expensive training routine, zero-shot/cost proxies analyze an NN at initialization to generate a score, which correlates highly with its true accuracy. Zero-cost proxies are currently designed by experts conducting multiple cycles of empirical testing on possible algorithms, data-sets, and neural architecture design spaces. This lowers productivity and is an unsustainable approach towards zero-cost proxy design as deep learning use-cases diversify in nature. Additionally, existing zero-cost proxies fail to generalize across neural architecture design spaces. In this paper, we propose a genetic programming framework to automate the discovery of zero-cost proxies for neural architecture scoring. Our methodology efficiently discovers an interpretable and generalizable zero-cost proxy that gives state of the art score-accuracy correlation on all data-sets and search spaces of NASBench-201 and Network Design Spaces (NDS). We believe that this research indicates a promising direction towards automatically discovering zero-cost proxies that can work across network architecture design spaces, data-sets, and tasks.
Improving Robustness and Efficiency in Active Learning with Contrastive Loss
Sep 13, 2021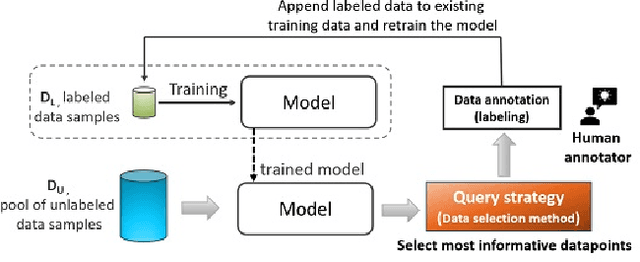
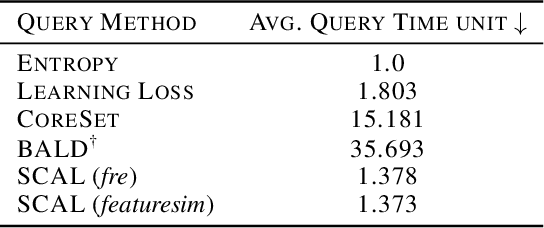
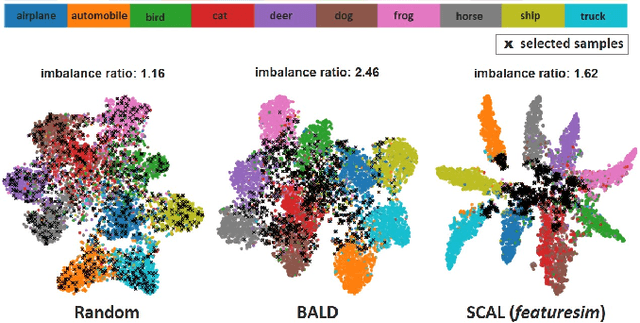
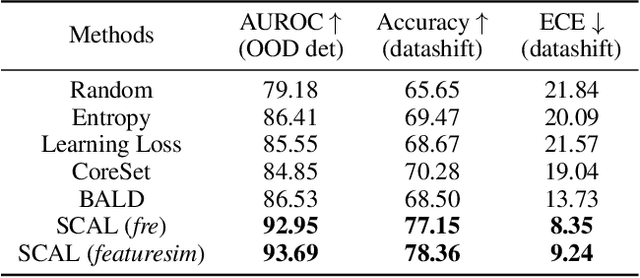
This paper introduces supervised contrastive active learning (SCAL) by leveraging the contrastive loss for active learning in a supervised setting. We propose efficient query strategies in active learning to select unbiased and informative data samples of diverse feature representations. We demonstrate our proposed method reduces sampling bias, achieves state-of-the-art accuracy and model calibration in an active learning setup with the query computation 11x faster than CoreSet and 26x faster than Bayesian active learning by disagreement. Our method yields well-calibrated models even with imbalanced datasets. We also evaluate robustness to dataset shift and out-of-distribution in active learning setup and demonstrate our proposed SCAL method outperforms high performing compute-intensive methods by a bigger margin (average 8.9% higher AUROC for out-of-distribution detection and average 7.2% lower ECE under dataset shift).
Mitigating Sampling Bias and Improving Robustness in Active Learning
Sep 13, 2021
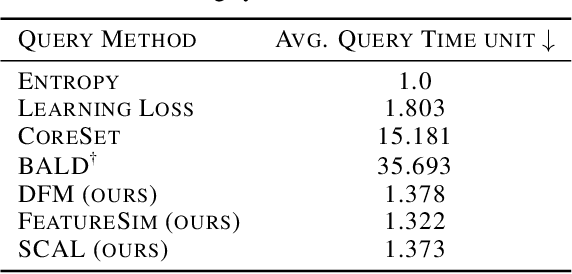


This paper presents simple and efficient methods to mitigate sampling bias in active learning while achieving state-of-the-art accuracy and model robustness. We introduce supervised contrastive active learning by leveraging the contrastive loss for active learning under a supervised setting. We propose an unbiased query strategy that selects informative data samples of diverse feature representations with our methods: supervised contrastive active learning (SCAL) and deep feature modeling (DFM). We empirically demonstrate our proposed methods reduce sampling bias, achieve state-of-the-art accuracy and model calibration in an active learning setup with the query computation 26x faster than Bayesian active learning by disagreement and 11x faster than CoreSet. The proposed SCAL method outperforms by a big margin in robustness to dataset shift and out-of-distribution.
RHNAS: Realizable Hardware and Neural Architecture Search
Jun 17, 2021
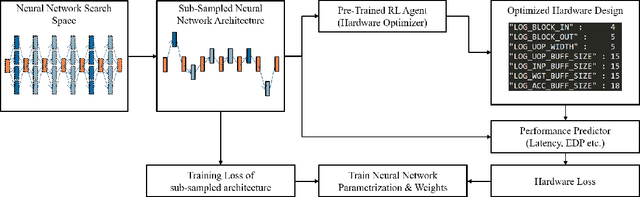
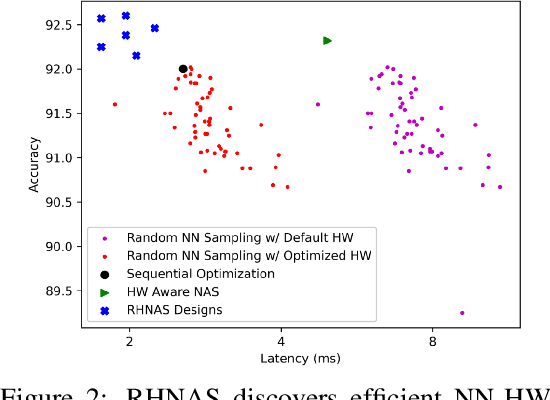

The rapidly evolving field of Artificial Intelligence necessitates automated approaches to co-design neural network architecture and neural accelerators to maximize system efficiency and address productivity challenges. To enable joint optimization of this vast space, there has been growing interest in differentiable NN-HW co-design. Fully differentiable co-design has reduced the resource requirements for discovering optimized NN-HW configurations, but fail to adapt to general hardware accelerator search spaces. This is due to the existence of non-synthesizable (invalid) designs in the search space of many hardware accelerators. To enable efficient and realizable co-design of configurable hardware accelerators with arbitrary neural network search spaces, we introduce RHNAS. RHNAS is a method that combines reinforcement learning for hardware optimization with differentiable neural architecture search. RHNAS discovers realizable NN-HW designs with 1.84x lower latency and 1.86x lower energy-delay product (EDP) on ImageNet and 2.81x lower latency and 3.30x lower EDP on CIFAR-10 over the default hardware accelerator design.
ML-driven Malware that Targets AV Safety
Apr 24, 2020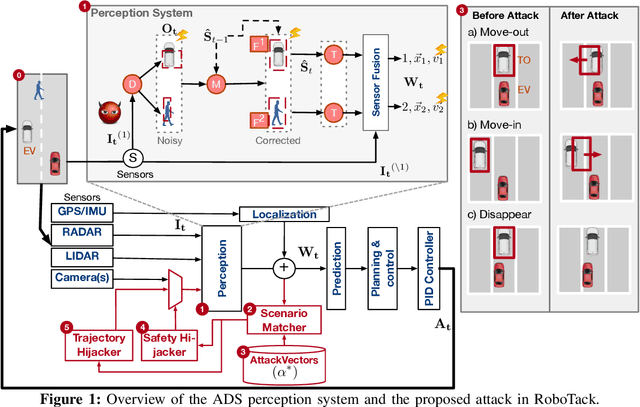
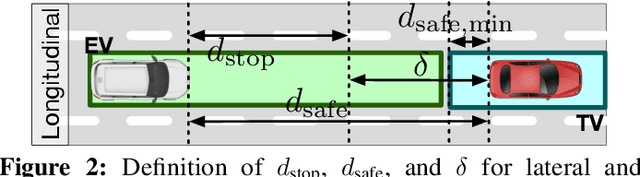


Ensuring the safety of autonomous vehicles (AVs) is critical for their mass deployment and public adoption. However, security attacks that violate safety constraints and cause accidents are a significant deterrent to achieving public trust in AVs, and that hinders a vendor's ability to deploy AVs. Creating a security hazard that results in a severe safety compromise (for example, an accident) is compelling from an attacker's perspective. In this paper, we introduce an attack model, a method to deploy the attack in the form of smart malware, and an experimental evaluation of its impact on production-grade autonomous driving software. We find that determining the time interval during which to launch the attack is{ critically} important for causing safety hazards (such as collisions) with a high degree of success. For example, the smart malware caused 33X more forced emergency braking than random attacks did, and accidents in 52.6% of the driving simulations.
* Accepted for DSN 2020