 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAPID: Enabling Fast Online Policy Learning in Dynamic Public Cloud Environments
Apr 10, 2023



Resource sharing between multiple workloads has become a prominent practice among cloud service providers, motivated by demand for improved resource utilization and reduced cost of ownership. Effective resource sharing, however, remains an open challenge due to the adverse effects that resource contention can have on high-priority, user-facing workloads with strict Quality of Service (QoS) requirements. Although recent approaches have demonstrated promising results, those works remain largely impractical in public cloud environments since workloads are not known in advance and may only run for a brief period, thus prohibiting offline learning and significantly hindering online learning. In this paper, we propose RAPID, a novel framework for fast, fully-online resource allocation policy learning in highly dynamic operating environments. RAPID leverages lightweight QoS predictions, enabled by domain-knowledge-inspired techniques for sample efficiency and bias reduction, to decouple control from conventional feedback sources and guide policy learning at a rate orders of magnitude faster than prior work. Evaluation on a real-world server platform with representative cloud workloads confirms that RAPID can learn stable resource allocation policies in minutes, as compared with hours in prior state-of-the-art, while improving QoS by 9.0x and increasing best-effort workload performance by 19-43%.
PROMPT: Learning Dynamic Resource Allocation Policies for Edge-Network Applications
Jan 19, 2022A growing number of service providers are exploring methods to improve server utilization, reduce power consumption, and reduce total cost of ownership by co-scheduling high-priority latency-critical workloads with best-effort workloads. This practice requires strict resource allocation between workloads to reduce resource contention and maintain Quality of Service (QoS) guarantees. Prior resource allocation works have been shown to improve server utilization under ideal circumstances, yet often compromise QoS guarantees or fail to find valid resource allocations in more dynamic operating environments. Further, prior works are fundamentally reliant upon QoS measurements that can, in practice, exhibit significant transient fluctuations, thus stable control behavior cannot be reliably achieved. In this paper, we propose a novel framework for dynamic resource allocation based on proactive QoS prediction. These predictions help guide a reinforcement-learning-based resource controller towards optimal resource allocations while avoiding transient QoS violations due to fluctuating workload demands. Evaluation shows that the proposed method incurs 4.3x fewer QoS violations, reduces severity of QoS violations by 3.7x, improves best-effort workload performance, and improves overall power efficiency compared with prior work.
Accelerating SLIDE Deep Learning on Modern CPUs: Vectorization, Quantizations, Memory Optimizations, and More
Mar 06, 2021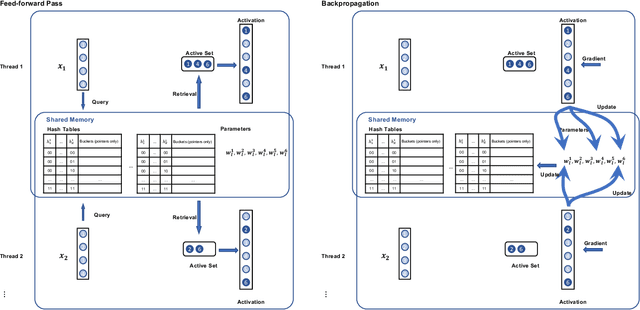


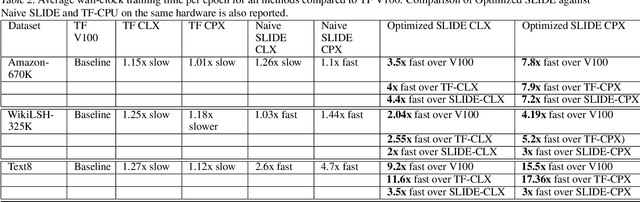
Deep learning implementations on CPUs (Central Processing Units) are gaining more traction. Enhanced AI capabilities on commodity x86 architectures are commercially appealing due to the reuse of existing hardware and virtualization ease. A notable work in this direction is the SLIDE system. SLIDE is a C++ implementation of a sparse hash table based back-propagation, which was shown to be significantly faster than GPUs in training hundreds of million parameter neural models. In this paper, we argue that SLIDE's current implementation is sub-optimal and does not exploit several opportunities available in modern CPUs. In particular, we show how SLIDE's computations allow for a unique possibility of vectorization via AVX (Advanced Vector Extensions)-512. Furthermore, we highlight opportunities for different kinds of memory optimization and quantizations. Combining all of them, we obtain up to 7x speedup in the computations on the same hardware. Our experiments are focused on large (hundreds of millions of parameters) recommendation and NLP models. Our work highlights several novel perspectives and opportunities for implementing randomized algorithms for deep learning on modern CPUs. We provide the code and benchmark scripts at https://github.com/RUSH-LAB/SLIDE