 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Guided ANN Index Optimization for Human-Object Interaction Retrieval
Jun 03, 2026Retrieval systems underpin modern AI applications -- spanning visual search, recommendation engines, and multi-modal question answering. Modern multi-stage retrieval systems require the joint optimization of highly coupled parameters, yet traditional hyperparameter optimization (HPO) methods -- including Tree-structured Parzen Estimators (TPE) and Gaussian Process Bayesian Optimization -- rely on an independence assumption that fundamentally prevents them from navigating these coupled configuration spaces. We address this limitation with a phase-aware large language model (LLM) agent that conditions each proposal on its full optimization history, navigating the coupled parameter space across phase-partitioned exploration, exploitation, and fine-tuning stages. Evaluated on the HICO-DET human-object interaction retrieval benchmark using Intel VDMS (Visual Data Management System), our agent outperforms Optuna TPE by +33.3% and VDTuner by +34.2% under SIEVE (Safeguarded Index Evaluation of Vector-search Efficiency, a quality-constrained throughput metric), delivering a 15.3x throughput gain over UniIR. Validation across three benchmarks confirms that the agent's advantage grows with the degree of parameter coupling: +33.3% on HICO-DET (high coupling), methods converge within 1% on GLDv2 (moderate coupling) and within 3.6% on SIFT1M (near-independent control). Cross-system validation on Milvus confirms the optimizer ranks first on all three datasets without modification, demonstrating transferability across vector database management system (VDBMS) platforms.
SparAMX: Accelerating Compressed LLMs Token Generation on AMX-powered CPUs
Feb 18, 2025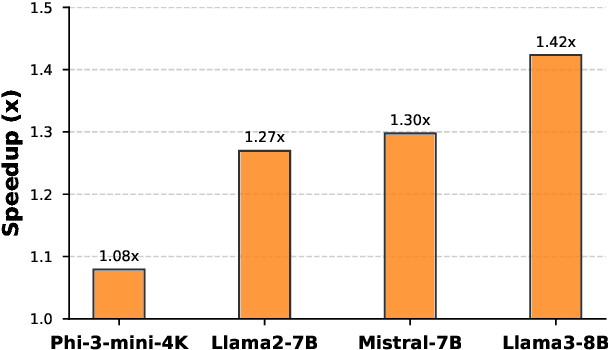

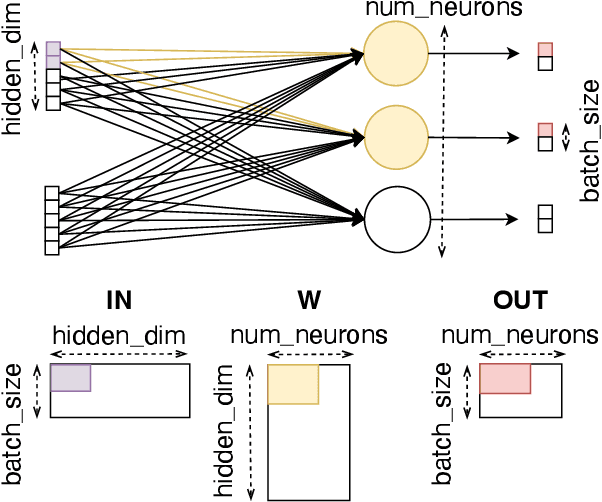
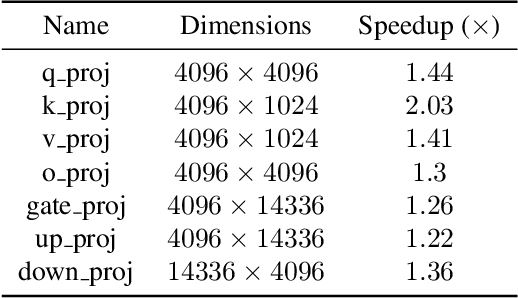
Large language models have high compute, latency, and memory requirements. While specialized accelerators such as GPUs and TPUs typically run these workloads, CPUs are more widely available and consume less energy. Accelerating LLMs with CPUs enables broader AI access at a lower cost and power consumption. This acceleration potential for CPUs is especially relevant during the memory-bound decoding stage of LLM inference, which processes one token at a time and is becoming increasingly utilized with reasoning models. We utilize Advanced Matrix Extensions (AMX) support on the latest Intel CPUs together with unstructured sparsity to achieve a $1.42 \times$ reduction in end-to-end latency compared to the current PyTorch implementation by applying our technique in linear layers. We provide a set of open-source customized sparse kernels that can speed up any PyTorch model by automatically replacing all linear layers with our custom sparse implementation. Furthermore, we demonstrate for the first time the use of unstructured sparsity in the attention computation achieving a $1.14 \times$ speedup over the current systems without compromising accuracy. Code: https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning/tree/main/SparAMX
Mem-Rec: Memory Efficient Recommendation System using Alternative Representation
May 15, 2023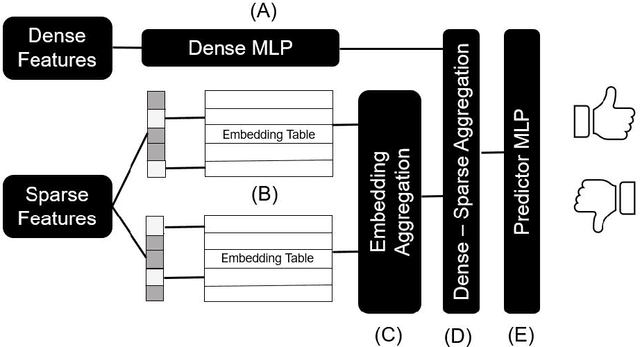
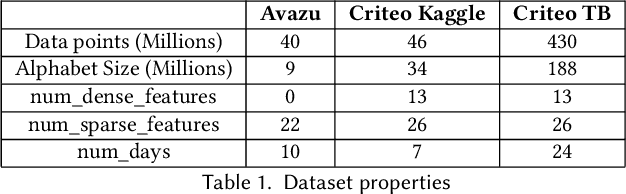
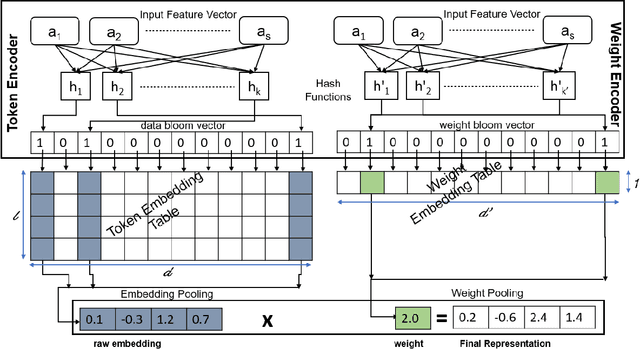
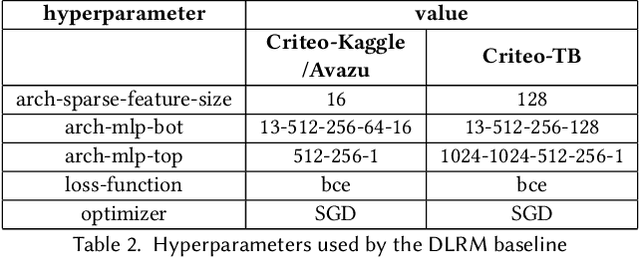
Deep learning-based recommendation systems (e.g., DLRMs) are widely used AI models to provide high-quality personalized recommendations. Training data used for modern recommendation systems commonly includes categorical features taking on tens-of-millions of possible distinct values. These categorical tokens are typically assigned learned vector representations, that are stored in large embedding tables, on the order of 100s of GB. Storing and accessing these tables represent a substantial burden in commercial deployments. Our work proposes MEM-REC, a novel alternative representation approach for embedding tables. MEM-REC leverages bloom filters and hashing methods to encode categorical features using two cache-friendly embedding tables. The first table (token embedding) contains raw embeddings (i.e. learned vector representation), and the second table (weight embedding), which is much smaller, contains weights to scale these raw embeddings to provide better discriminative capability to each data point. We provide a detailed architecture, design and analysis of MEM-REC addressing trade-offs in accuracy and computation requirements, in comparison with state-of-the-art techniques. We show that MEM-REC can not only maintain the recommendation quality and significantly reduce the memory footprint for commercial scale recommendation models but can also improve the embedding latency. In particular, based on our results, MEM-REC compresses the MLPerf CriteoTB benchmark DLRM model size by 2900x and performs up to 3.4x faster embeddings while achieving the same AUC as that of the full uncompressed model.
Accelerating SLIDE Deep Learning on Modern CPUs: Vectorization, Quantizations, Memory Optimizations, and More
Mar 06, 2021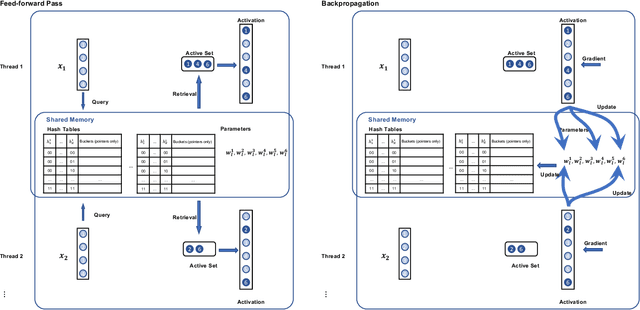


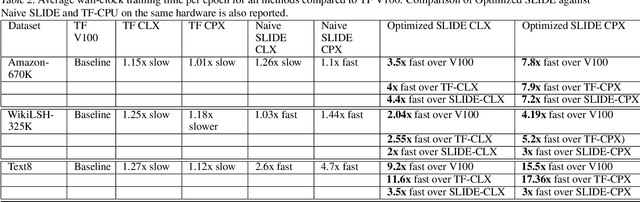
Deep learning implementations on CPUs (Central Processing Units) are gaining more traction. Enhanced AI capabilities on commodity x86 architectures are commercially appealing due to the reuse of existing hardware and virtualization ease. A notable work in this direction is the SLIDE system. SLIDE is a C++ implementation of a sparse hash table based back-propagation, which was shown to be significantly faster than GPUs in training hundreds of million parameter neural models. In this paper, we argue that SLIDE's current implementation is sub-optimal and does not exploit several opportunities available in modern CPUs. In particular, we show how SLIDE's computations allow for a unique possibility of vectorization via AVX (Advanced Vector Extensions)-512. Furthermore, we highlight opportunities for different kinds of memory optimization and quantizations. Combining all of them, we obtain up to 7x speedup in the computations on the same hardware. Our experiments are focused on large (hundreds of millions of parameters) recommendation and NLP models. Our work highlights several novel perspectives and opportunities for implementing randomized algorithms for deep learning on modern CPUs. We provide the code and benchmark scripts at https://github.com/RUSH-LAB/SLIDE