 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplitReason: Learning To Offload Reasoning
Apr 23, 2025Reasoning in large language models (LLMs) tends to produce substantially longer token generation sequences than simpler language modeling tasks. This extended generation length reflects the multi-step, compositional nature of reasoning and is often correlated with higher solution accuracy. From an efficiency perspective, longer token generation exacerbates the inherently sequential and memory-bound decoding phase of LLMs. However, not all parts of this expensive reasoning process are equally difficult to generate. We leverage this observation by offloading only the most challenging parts of the reasoning process to a larger, more capable model, while performing most of the generation with a smaller, more efficient model; furthermore, we teach the smaller model to identify these difficult segments and independently trigger offloading when needed. To enable this behavior, we annotate difficult segments across 18k reasoning traces from the OpenR1-Math-220k chain-of-thought (CoT) dataset. We then apply supervised fine-tuning (SFT) and reinforcement learning fine-tuning (RLFT) to a 1.5B-parameter reasoning model, training it to learn to offload the most challenging parts of its own reasoning process to a larger model. This approach improves AIME24 reasoning accuracy by 24% and 28.3% while offloading 1.35% and 5% of the generated tokens respectively. We open-source our SplitReason model, data, code and logs.
SparAMX: Accelerating Compressed LLMs Token Generation on AMX-powered CPUs
Feb 18, 2025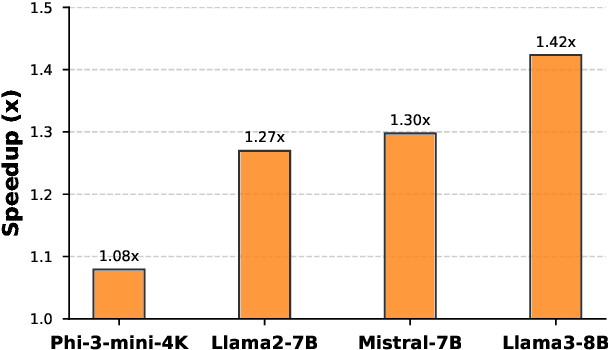

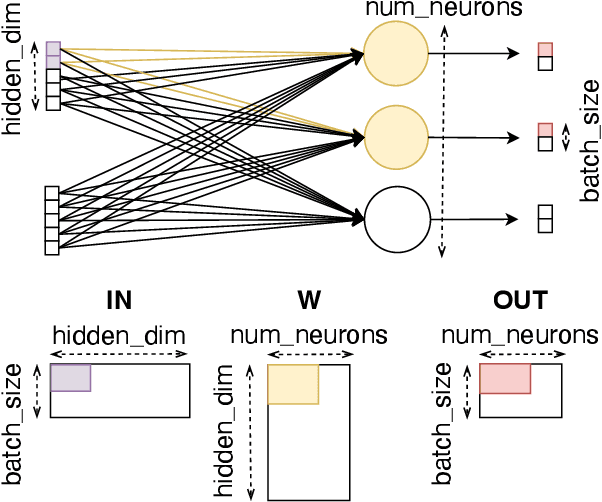
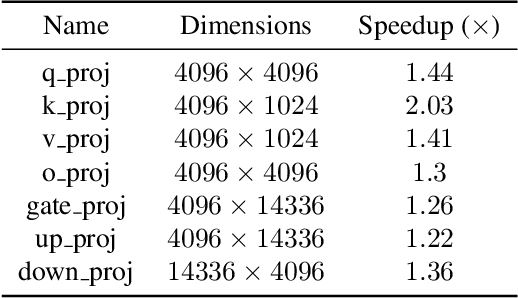
Large language models have high compute, latency, and memory requirements. While specialized accelerators such as GPUs and TPUs typically run these workloads, CPUs are more widely available and consume less energy. Accelerating LLMs with CPUs enables broader AI access at a lower cost and power consumption. This acceleration potential for CPUs is especially relevant during the memory-bound decoding stage of LLM inference, which processes one token at a time and is becoming increasingly utilized with reasoning models. We utilize Advanced Matrix Extensions (AMX) support on the latest Intel CPUs together with unstructured sparsity to achieve a $1.42 \times$ reduction in end-to-end latency compared to the current PyTorch implementation by applying our technique in linear layers. We provide a set of open-source customized sparse kernels that can speed up any PyTorch model by automatically replacing all linear layers with our custom sparse implementation. Furthermore, we demonstrate for the first time the use of unstructured sparsity in the attention computation achieving a $1.14 \times$ speedup over the current systems without compromising accuracy. Code: https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning/tree/main/SparAMX
BitMoD: Bit-serial Mixture-of-Datatype LLM Acceleration
Nov 18, 2024



Large language models (LLMs) have demonstrated remarkable performance across various machine learning tasks. Yet the substantial memory footprint of LLMs significantly hinders their deployment. In this paper, we improve the accessibility of LLMs through BitMoD, an algorithm-hardware co-design solution that enables efficient LLM acceleration at low weight precision. On the algorithm side, BitMoD introduces fine-grained data type adaptation that uses a different numerical data type to quantize a group of (e.g., 128) weights. Through the careful design of these new data types, BitMoD is able to quantize LLM weights to very low precision (e.g., 4 bits and 3 bits) while maintaining high accuracy. On the hardware side, BitMoD employs a bit-serial processing element to easily support multiple numerical precisions and data types; our hardware design includes two key innovations: First, it employs a unified representation to process different weight data types, thus reducing the hardware cost. Second, it adopts a bit-serial dequantization unit to rescale the per-group partial sum with minimal hardware overhead. Our evaluation on six representative LLMs demonstrates that BitMoD significantly outperforms state-of-the-art LLM quantization and acceleration methods. For discriminative tasks, BitMoD can quantize LLM weights to 4-bit with $<\!0.5\%$ accuracy loss on average. For generative tasks, BitMoD is able to quantize LLM weights to 3-bit while achieving better perplexity than prior LLM quantization scheme. Combining the superior model performance with an efficient accelerator design, BitMoD achieves an average of $1.69\times$ and $1.48\times$ speedups compared to prior LLM accelerators ANT and OliVe, respectively.