 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRT: Accelerating Reinforcement Learning via Speculative Rollout with Tree-Structured Cache
Jan 14, 2026We present Speculative Rollout with Tree-Structured Cache (SRT), a simple, model-free approach to accelerate on-policy reinforcement learning (RL) for language models without sacrificing distributional correctness. SRT exploits the empirical similarity of rollouts for the same prompt across training steps by storing previously generated continuations in a per-prompt tree-structured cache. During generation, the current policy uses this tree as the draft model for performing speculative decoding. To keep the cache fresh and improve draft model quality, SRT updates trees online from ongoing rollouts and proactively performs run-ahead generation during idle GPU bubbles. Integrated into standard RL pipelines (\textit{e.g.}, PPO, GRPO and DAPO) and multi-turn settings, SRT consistently reduces generation and step latency and lowers per-token inference cost, achieving up to 2.08x wall-clock time speedup during rollout.
SplitReason: Learning To Offload Reasoning
Apr 23, 2025Reasoning in large language models (LLMs) tends to produce substantially longer token generation sequences than simpler language modeling tasks. This extended generation length reflects the multi-step, compositional nature of reasoning and is often correlated with higher solution accuracy. From an efficiency perspective, longer token generation exacerbates the inherently sequential and memory-bound decoding phase of LLMs. However, not all parts of this expensive reasoning process are equally difficult to generate. We leverage this observation by offloading only the most challenging parts of the reasoning process to a larger, more capable model, while performing most of the generation with a smaller, more efficient model; furthermore, we teach the smaller model to identify these difficult segments and independently trigger offloading when needed. To enable this behavior, we annotate difficult segments across 18k reasoning traces from the OpenR1-Math-220k chain-of-thought (CoT) dataset. We then apply supervised fine-tuning (SFT) and reinforcement learning fine-tuning (RLFT) to a 1.5B-parameter reasoning model, training it to learn to offload the most challenging parts of its own reasoning process to a larger model. This approach improves AIME24 reasoning accuracy by 24% and 28.3% while offloading 1.35% and 5% of the generated tokens respectively. We open-source our SplitReason model, data, code and logs.
Quamba2: A Robust and Scalable Post-training Quantization Framework for Selective State Space Models
Mar 28, 2025State Space Models (SSMs) are emerging as a compelling alternative to Transformers because of their consistent memory usage and high performance. Despite this, scaling up SSMs on cloud services or limited-resource devices is challenging due to their storage requirements and computational power. To overcome this, quantizing SSMs with low bit-width data formats can reduce model size and benefit from hardware acceleration. As SSMs are prone to quantization-induced errors, recent efforts have focused on optimizing a particular model or bit-width for efficiency without sacrificing performance. However, distinct bit-width configurations are essential for different scenarios, like W4A8 for boosting large-batch decoding speed, and W4A16 for enhancing generation speed in short prompt applications for a single user. To this end, we present Quamba2, compatible with W8A8, W4A8, and W4A16 for both Mamba1 and Mamba2 backbones, addressing the growing demand for SSM deployment on various platforms. Based on the channel order preserving and activation persistence of SSMs, we propose an offline approach to quantize inputs of a linear recurrence in 8-bit by sorting and clustering for input $x$, combined with a per-state-group quantization for input-dependent parameters $B$ and $C$. To ensure compute-invariance in the SSM output, we rearrange weights offline according to the clustering sequence. The experiments show that Quamba2-8B outperforms several state-of-the-art SSM quantization methods and delivers 1.3$\times$ and 3$\times$ speed-ups in the pre-filling and generation stages, respectively, while offering 4$\times$ memory reduction with only a $1.6\%$ average accuracy drop. The evaluation on MMLU shows the generalizability and robustness of our framework. The code and quantized models will be released at: https://github.com/enyac-group/Quamba.
xKV: Cross-Layer SVD for KV-Cache Compression
Mar 24, 2025Large Language Models (LLMs) with long context windows enable powerful applications but come at the cost of high memory consumption to store the Key and Value states (KV-Cache). Recent studies attempted to merge KV-cache from multiple layers into shared representations, yet these approaches either require expensive pretraining or rely on assumptions of high per-token cosine similarity across layers which generally does not hold in practice. We find that the dominant singular vectors are remarkably well-aligned across multiple layers of the KV-Cache. Exploiting this insight, we propose xKV, a simple post-training method that applies Singular Value Decomposition (SVD) on the KV-Cache of grouped layers. xKV consolidates the KV-Cache of multiple layers into a shared low-rank subspace, significantly reducing KV-Cache sizes. Through extensive evaluations on the RULER long-context benchmark with widely-used LLMs (e.g., Llama-3.1 and Qwen2.5), xKV achieves up to 6.8x higher compression rates than state-of-the-art inter-layer technique while improving accuracy by 2.7%. Moreover, xKV is compatible with the emerging Multi-Head Latent Attention (MLA) (e.g., DeepSeek-Coder-V2), yielding a notable 3x compression rates on coding tasks without performance degradation. These results highlight xKV's strong capability and versatility in addressing memory bottlenecks for long-context LLM inference. Our code is publicly available at: https://github.com/abdelfattah-lab/xKV.
TokenButler: Token Importance is Predictable
Mar 10, 2025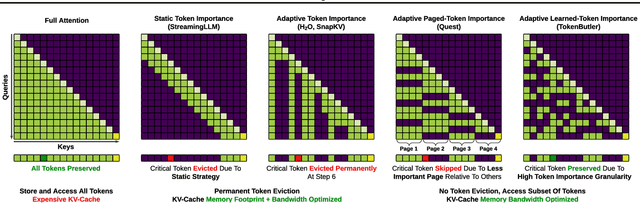
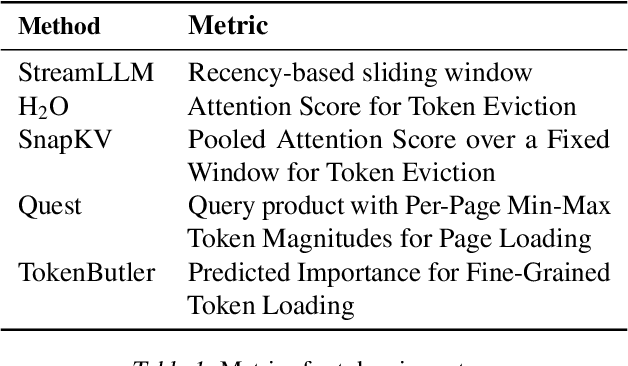
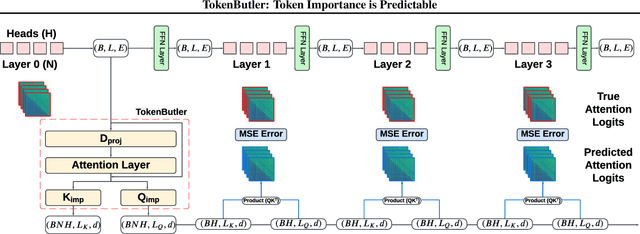
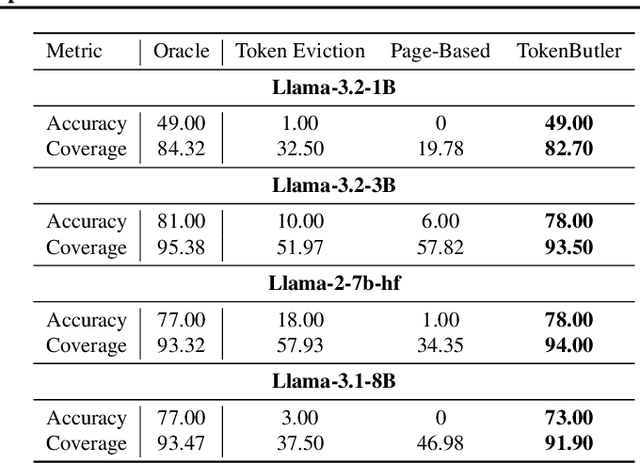
Large Language Models (LLMs) rely on the Key-Value (KV) Cache to store token history, enabling efficient decoding of tokens. As the KV-Cache grows, it becomes a major memory and computation bottleneck, however, there is an opportunity to alleviate this bottleneck, especially because prior research has shown that only a small subset of tokens contribute meaningfully to each decoding step. A key challenge in finding these critical tokens is that they are dynamic, and heavily input query-dependent. Existing methods either risk quality by evicting tokens permanently, or retain the full KV-Cache but rely on retrieving chunks (pages) of tokens at generation, failing at dense, context-rich tasks. Additionally, many existing KV-Cache sparsity methods rely on inaccurate proxies for token importance. To address these limitations, we introduce TokenButler, a high-granularity, query-aware predictor that learns to identify these critical tokens. By training a light-weight predictor with less than 1.2% parameter overhead, TokenButler prioritizes tokens based on their contextual, predicted importance. This improves perplexity & downstream accuracy by over 8% relative to SoTA methods for estimating token importance. We evaluate TokenButler on a novel synthetic small-context co-referential retrieval task, demonstrating near-oracle accuracy. Code, models and benchmarks: https://github.com/abdelfattah-lab/TokenButler
SparAMX: Accelerating Compressed LLMs Token Generation on AMX-powered CPUs
Feb 18, 2025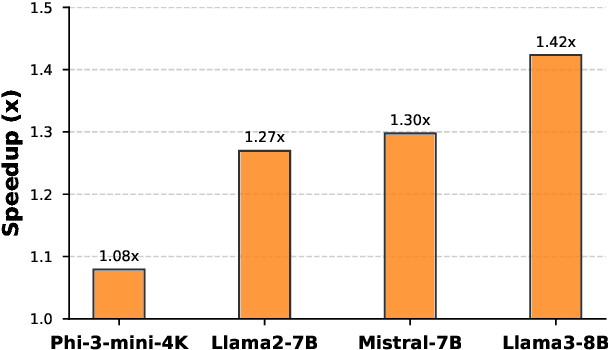

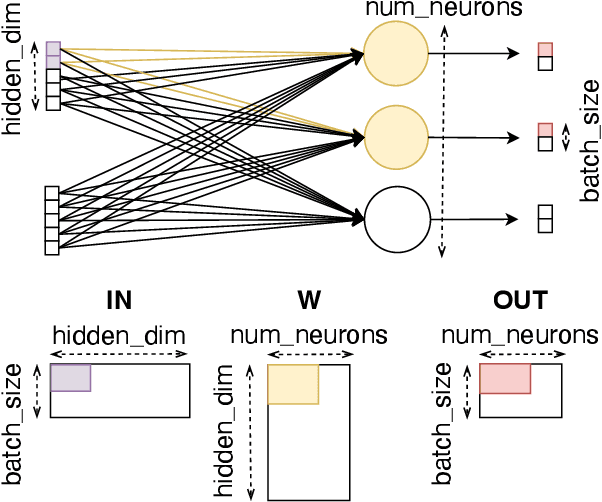
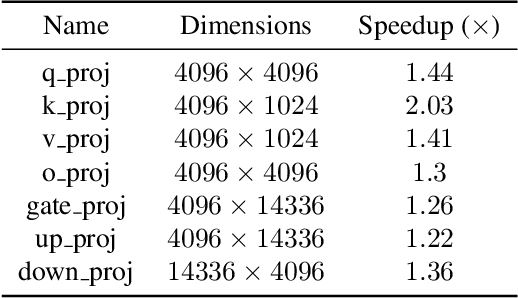
Large language models have high compute, latency, and memory requirements. While specialized accelerators such as GPUs and TPUs typically run these workloads, CPUs are more widely available and consume less energy. Accelerating LLMs with CPUs enables broader AI access at a lower cost and power consumption. This acceleration potential for CPUs is especially relevant during the memory-bound decoding stage of LLM inference, which processes one token at a time and is becoming increasingly utilized with reasoning models. We utilize Advanced Matrix Extensions (AMX) support on the latest Intel CPUs together with unstructured sparsity to achieve a $1.42 \times$ reduction in end-to-end latency compared to the current PyTorch implementation by applying our technique in linear layers. We provide a set of open-source customized sparse kernels that can speed up any PyTorch model by automatically replacing all linear layers with our custom sparse implementation. Furthermore, we demonstrate for the first time the use of unstructured sparsity in the attention computation achieving a $1.14 \times$ speedup over the current systems without compromising accuracy. Code: https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning/tree/main/SparAMX
V"Mean"ba: Visual State Space Models only need 1 hidden dimension
Dec 21, 2024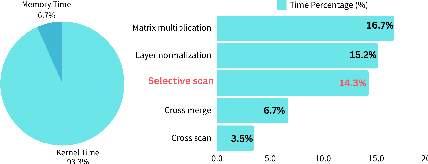
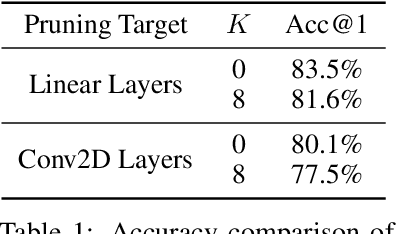
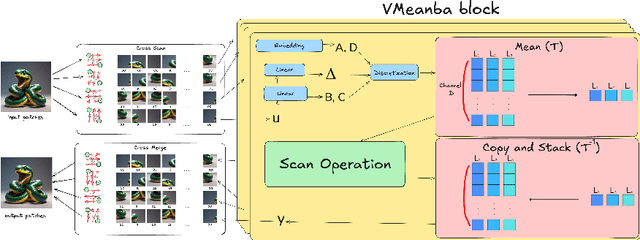
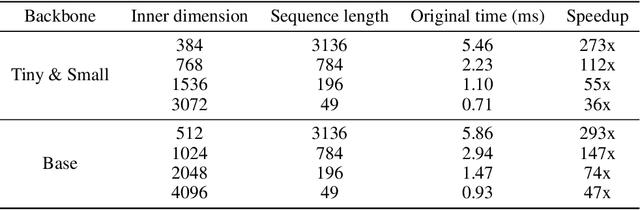
Vision transformers dominate image processing tasks due to their superior performance. However, the quadratic complexity of self-attention limits the scalability of these systems and their deployment on resource-constrained devices. State Space Models (SSMs) have emerged as a solution by introducing a linear recurrence mechanism, which reduces the complexity of sequence modeling from quadratic to linear. Recently, SSMs have been extended to high-resolution vision tasks. Nonetheless, the linear recurrence mechanism struggles to fully utilize matrix multiplication units on modern hardware, resulting in a computational bottleneck. We address this issue by introducing \textit{VMeanba}, a training-free compression method that eliminates the channel dimension in SSMs using mean operations. Our key observation is that the output activations of SSM blocks exhibit low variances across channels. Our \textit{VMeanba} leverages this property to optimize computation by averaging activation maps across the channel to reduce the computational overhead without compromising accuracy. Evaluations on image classification and semantic segmentation tasks demonstrate that \textit{VMeanba} achieves up to a 1.12x speedup with less than a 3\% accuracy loss. When combined with 40\% unstructured pruning, the accuracy drop remains under 3\%.
Quamba: A Post-Training Quantization Recipe for Selective State Space Models
Oct 17, 2024State Space Models (SSMs) have emerged as an appealing alternative to Transformers for large language models, achieving state-of-the-art accuracy with constant memory complexity which allows for holding longer context lengths than attention-based networks. The superior computational efficiency of SSMs in long sequence modeling positions them favorably over Transformers in many scenarios. However, improving the efficiency of SSMs on request-intensive cloud-serving and resource-limited edge applications is still a formidable task. SSM quantization is a possible solution to this problem, making SSMs more suitable for wide deployment, while still maintaining their accuracy. Quantization is a common technique to reduce the model size and to utilize the low bit-width acceleration features on modern computing units, yet existing quantization techniques are poorly suited for SSMs. Most notably, SSMs have highly sensitive feature maps within the selective scan mechanism (i.e., linear recurrence) and massive outliers in the output activations which are not present in the output of token-mixing in the self-attention modules. To address this issue, we propose a static 8-bit per-tensor SSM quantization method which suppresses the maximum values of the input activations to the selective SSM for finer quantization precision and quantizes the output activations in an outlier-free space with Hadamard transform. Our 8-bit weight-activation quantized Mamba 2.8B SSM benefits from hardware acceleration and achieves a 1.72x lower generation latency on an Nvidia Orin Nano 8G, with only a 0.9% drop in average accuracy on zero-shot tasks. The experiments demonstrate the effectiveness and practical applicability of our approach for deploying SSM-based models of all sizes on both cloud and edge platforms.
ELSA: Exploiting Layer-wise N:M Sparsity for Vision Transformer Acceleration
Sep 15, 2024
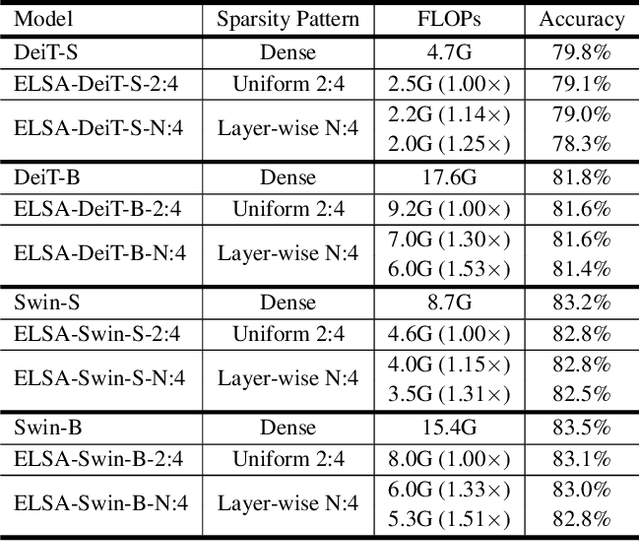
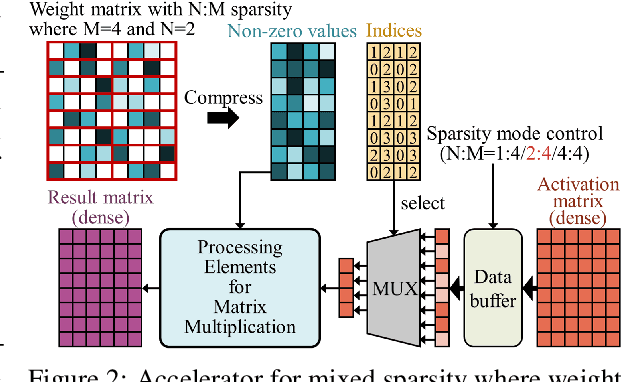
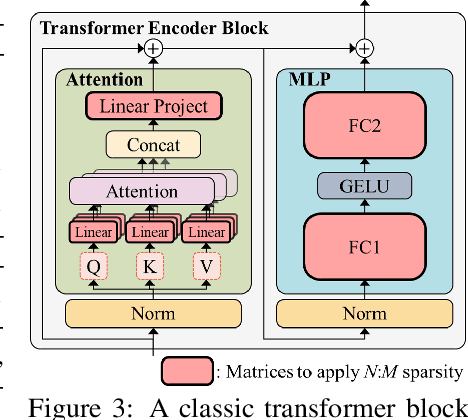
$N{:}M$ sparsity is an emerging model compression method supported by more and more accelerators to speed up sparse matrix multiplication in deep neural networks. Most existing $N{:}M$ sparsity methods compress neural networks with a uniform setting for all layers in a network or heuristically determine the layer-wise configuration by considering the number of parameters in each layer. However, very few methods have been designed for obtaining a layer-wise customized $N{:}M$ sparse configuration for vision transformers (ViTs), which usually consist of transformer blocks involving the same number of parameters. In this work, to address the challenge of selecting suitable sparse configuration for ViTs on $N{:}M$ sparsity-supporting accelerators, we propose ELSA, Exploiting Layer-wise $N{:}M$ Sparsity for ViTs. Considering not only all $N{:}M$ sparsity levels supported by a given accelerator but also the expected throughput improvement, our methodology can reap the benefits of accelerators supporting mixed sparsity by trading off negligible accuracy loss with both memory usage and inference time reduction for ViT models. For instance, our approach achieves a noteworthy 2.9$\times$ reduction in FLOPs for both Swin-B and DeiT-B with only a marginal degradation of accuracy on ImageNet. Our code will be released upon paper acceptance.
Palu: Compressing KV-Cache with Low-Rank Projection
Jul 30, 2024



KV-Cache compression methods generally sample a KV-Cache of effectual tokens or quantize it into lower bits. However, these methods cannot exploit the redundancy of the hidden dimension of KV tensors. This paper investigates a unique hidden dimension approach called Palu, a novel KV-Cache compression framework that utilizes low-rank projection. Palu decomposes the linear layers into low-rank matrices, caches the smaller intermediate states, and reconstructs the full keys and values on the fly. To improve accuracy, compression rate, and efficiency, Palu further encompasses (1) a medium-grained low-rank decomposition scheme, (2) an efficient rank search algorithm, (3) a low-rank-aware quantization algorithm, and (4) matrix fusion with optimized GPU kernels. Our extensive experiments with popular LLMs show that Palu can compress KV-Cache by more than 91.25% while maintaining a significantly better accuracy (up to 1.19 lower perplexity) than state-of-the-art KV-Cache quantization methods at a similar or even higher memory usage. When compressing KV-Cache for 50%, Palu delivers up to 1.61x end-to-end speedup for the attention module. Our code is publicly available at https://github.com/shadowpa0327/Palu.