 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV"Mean"ba: Visual State Space Models only need 1 hidden dimension
Dec 21, 2024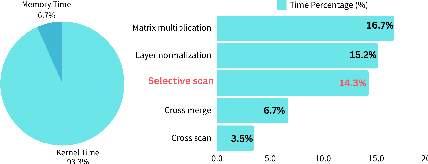
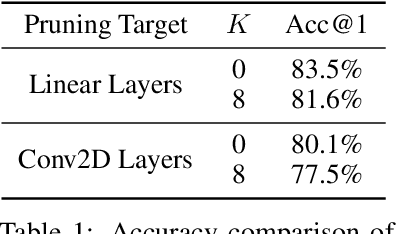
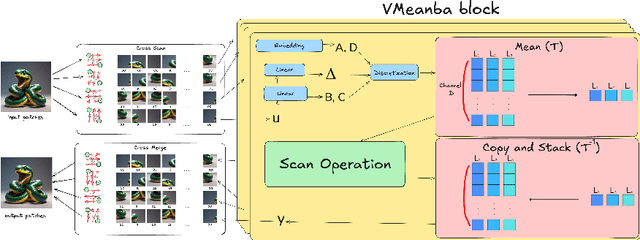
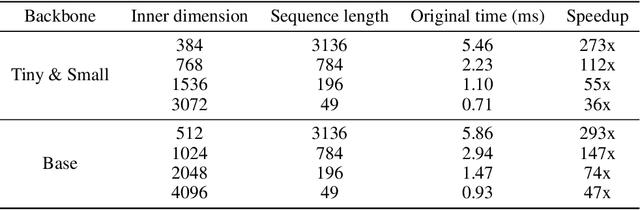
Vision transformers dominate image processing tasks due to their superior performance. However, the quadratic complexity of self-attention limits the scalability of these systems and their deployment on resource-constrained devices. State Space Models (SSMs) have emerged as a solution by introducing a linear recurrence mechanism, which reduces the complexity of sequence modeling from quadratic to linear. Recently, SSMs have been extended to high-resolution vision tasks. Nonetheless, the linear recurrence mechanism struggles to fully utilize matrix multiplication units on modern hardware, resulting in a computational bottleneck. We address this issue by introducing \textit{VMeanba}, a training-free compression method that eliminates the channel dimension in SSMs using mean operations. Our key observation is that the output activations of SSM blocks exhibit low variances across channels. Our \textit{VMeanba} leverages this property to optimize computation by averaging activation maps across the channel to reduce the computational overhead without compromising accuracy. Evaluations on image classification and semantic segmentation tasks demonstrate that \textit{VMeanba} achieves up to a 1.12x speedup with less than a 3\% accuracy loss. When combined with 40\% unstructured pruning, the accuracy drop remains under 3\%.
ELSA: Exploiting Layer-wise N:M Sparsity for Vision Transformer Acceleration
Sep 15, 2024
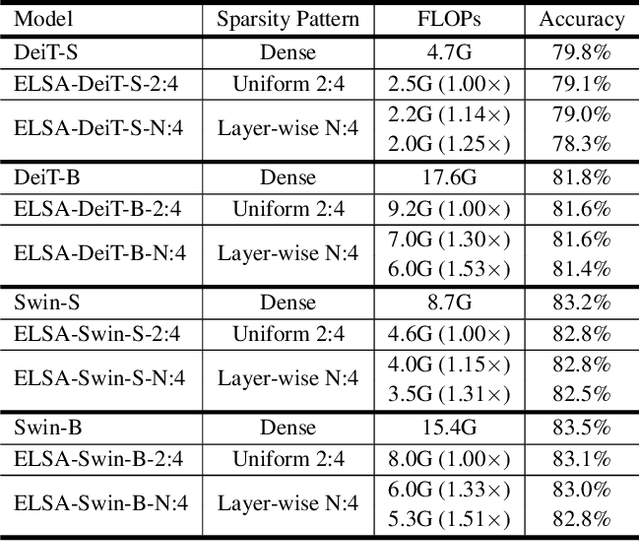
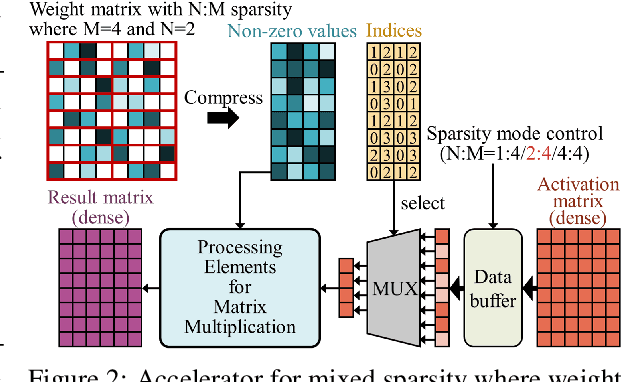
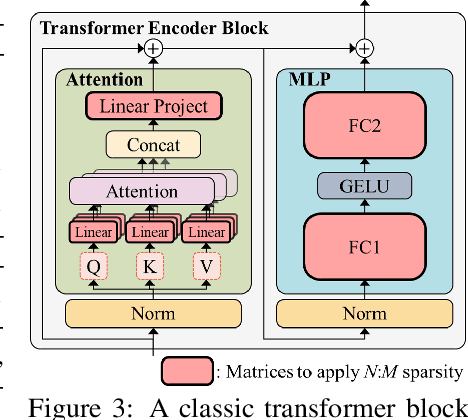
$N{:}M$ sparsity is an emerging model compression method supported by more and more accelerators to speed up sparse matrix multiplication in deep neural networks. Most existing $N{:}M$ sparsity methods compress neural networks with a uniform setting for all layers in a network or heuristically determine the layer-wise configuration by considering the number of parameters in each layer. However, very few methods have been designed for obtaining a layer-wise customized $N{:}M$ sparse configuration for vision transformers (ViTs), which usually consist of transformer blocks involving the same number of parameters. In this work, to address the challenge of selecting suitable sparse configuration for ViTs on $N{:}M$ sparsity-supporting accelerators, we propose ELSA, Exploiting Layer-wise $N{:}M$ Sparsity for ViTs. Considering not only all $N{:}M$ sparsity levels supported by a given accelerator but also the expected throughput improvement, our methodology can reap the benefits of accelerators supporting mixed sparsity by trading off negligible accuracy loss with both memory usage and inference time reduction for ViT models. For instance, our approach achieves a noteworthy 2.9$\times$ reduction in FLOPs for both Swin-B and DeiT-B with only a marginal degradation of accuracy on ImageNet. Our code will be released upon paper acceptance.
Palu: Compressing KV-Cache with Low-Rank Projection
Jul 30, 2024



KV-Cache compression methods generally sample a KV-Cache of effectual tokens or quantize it into lower bits. However, these methods cannot exploit the redundancy of the hidden dimension of KV tensors. This paper investigates a unique hidden dimension approach called Palu, a novel KV-Cache compression framework that utilizes low-rank projection. Palu decomposes the linear layers into low-rank matrices, caches the smaller intermediate states, and reconstructs the full keys and values on the fly. To improve accuracy, compression rate, and efficiency, Palu further encompasses (1) a medium-grained low-rank decomposition scheme, (2) an efficient rank search algorithm, (3) a low-rank-aware quantization algorithm, and (4) matrix fusion with optimized GPU kernels. Our extensive experiments with popular LLMs show that Palu can compress KV-Cache by more than 91.25% while maintaining a significantly better accuracy (up to 1.19 lower perplexity) than state-of-the-art KV-Cache quantization methods at a similar or even higher memory usage. When compressing KV-Cache for 50%, Palu delivers up to 1.61x end-to-end speedup for the attention module. Our code is publicly available at https://github.com/shadowpa0327/Palu.
FLORA: Fine-grained Low-Rank Architecture Search for Vision Transformer
Nov 07, 2023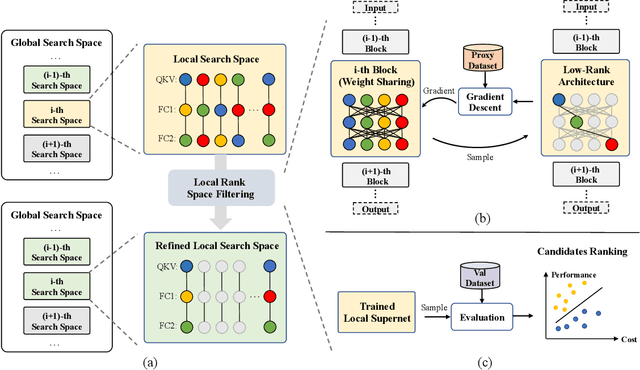
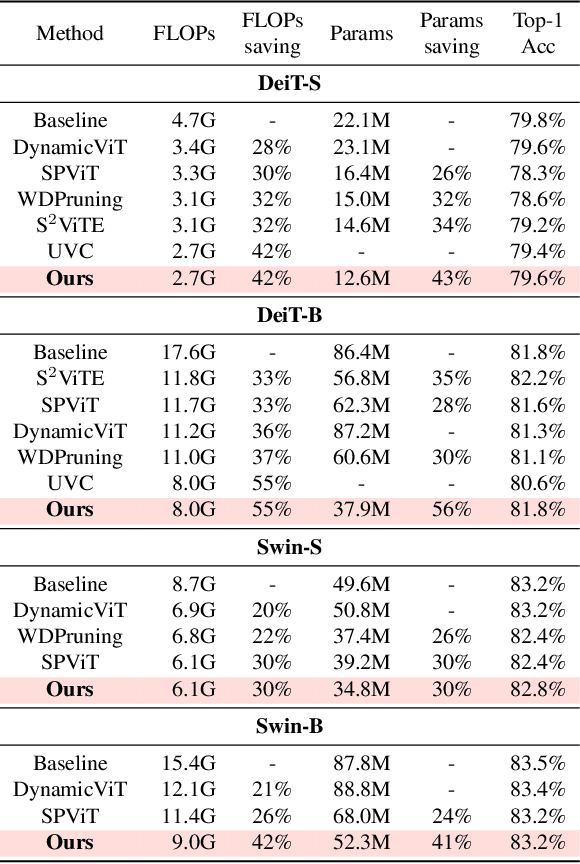
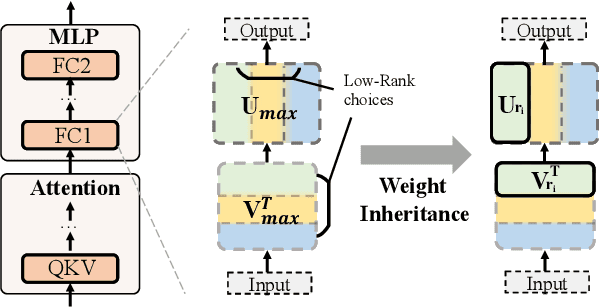
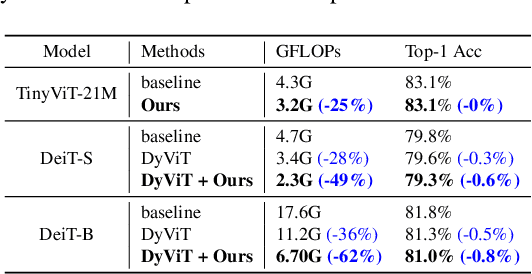
Vision Transformers (ViT) have recently demonstrated success across a myriad of computer vision tasks. However, their elevated computational demands pose significant challenges for real-world deployment. While low-rank approximation stands out as a renowned method to reduce computational loads, efficiently automating the target rank selection in ViT remains a challenge. Drawing from the notable similarity and alignment between the processes of rank selection and One-Shot NAS, we introduce FLORA, an end-to-end automatic framework based on NAS. To overcome the design challenge of supernet posed by vast search space, FLORA employs a low-rank aware candidate filtering strategy. This method adeptly identifies and eliminates underperforming candidates, effectively alleviating potential undertraining and interference among subnetworks. To further enhance the quality of low-rank supernets, we design a low-rank specific training paradigm. First, we propose weight inheritance to construct supernet and enable gradient sharing among low-rank modules. Secondly, we adopt low-rank aware sampling to strategically allocate training resources, taking into account inherited information from pre-trained models. Empirical results underscore FLORA's efficacy. With our method, a more fine-grained rank configuration can be generated automatically and yield up to 33% extra FLOPs reduction compared to a simple uniform configuration. More specific, FLORA-DeiT-B/FLORA-Swin-B can save up to 55%/42% FLOPs almost without performance degradtion. Importantly, FLORA boasts both versatility and orthogonality, offering an extra 21%-26% FLOPs reduction when integrated with leading compression techniques or compact hybrid structures. Our code is publicly available at https://github.com/shadowpa0327/FLORA.