 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVO: Agentic Variation Operators for Autonomous Evolutionary Search
Mar 25, 2026Agentic Variation Operators (AVO) are a new family of evolutionary variation operators that replace the fixed mutation, crossover, and hand-designed heuristics of classical evolutionary search with autonomous coding agents. Rather than confining a language model to candidate generation within a prescribed pipeline, AVO instantiates variation as a self-directed agent loop that can consult the current lineage, a domain-specific knowledge base, and execution feedback to propose, repair, critique, and verify implementation edits. We evaluate AVO on attention, among the most aggressively optimized kernel targets in AI, on NVIDIA Blackwell (B200) GPUs. Over 7 days of continuous autonomous evolution on multi-head attention, AVO discovers kernels that outperform cuDNN by up to 3.5% and FlashAttention-4 by up to 10.5% across the evaluated configurations. The discovered optimizations transfer readily to grouped-query attention, requiring only 30 minutes of additional autonomous adaptation and yielding gains of up to 7.0% over cuDNN and 9.3% over FlashAttention-4. Together, these results show that agentic variation operators move beyond prior LLM-in-the-loop evolutionary pipelines by elevating the agent from candidate generator to variation operator, and can discover performance-critical micro-architectural optimizations that produce kernels surpassing state-of-the-art expert-engineered attention implementations on today's most advanced GPU hardware.
SOL-ExecBench: Speed-of-Light Benchmarking for Real-World GPU Kernels Against Hardware Limits
Mar 19, 2026As agentic AI systems become increasingly capable of generating and optimizing GPU kernels, progress is constrained by benchmarks that reward speedup over software baselines rather than proximity to hardware-efficient execution. We present SOL-ExecBench, a benchmark of 235 CUDA kernel optimization problems extracted from 124 production and emerging AI models spanning language, diffusion, vision, audio, video, and hybrid architectures, targeting NVIDIA Blackwell GPUs. The benchmark covers forward and backward workloads across BF16, FP8, and NVFP4, including kernels whose best performance is expected to rely on Blackwell-specific capabilities. Unlike prior benchmarks that evaluate kernels primarily relative to software implementations, SOL-ExecBench measures performance against analytically derived Speed-of-Light (SOL) bounds computed by SOLAR, our pipeline for deriving hardware-grounded SOL bounds, yielding a fixed target for hardware-efficient optimization. We report a SOL Score that quantifies how much of the gap between a release-defined scoring baseline and the hardware SOL bound a candidate kernel closes. To support robust evaluation of agentic optimizers, we additionally provide a sandboxed harness with GPU clock locking, L2 cache clearing, isolated subprocess execution, and static analysis based checks against common reward-hacking strategies. SOL-ExecBench reframes GPU kernel benchmarking from beating a mutable software baseline to closing the remaining gap to hardware Speed-of-Light.
VibeTensor: System Software for Deep Learning, Fully Generated by AI Agents
Jan 21, 2026VIBETENSOR is an open-source research system software stack for deep learning, generated by LLM-powered coding agents under high-level human guidance. In this paper, "fully generated" refers to code provenance: implementation changes were produced and applied as agent-proposed diffs; validation relied on agent-run builds, tests, and differential checks, without per-change manual diff review. It implements a PyTorch-style eager tensor library with a C++20 core (CPU+CUDA), a torch-like Python overlay via nanobind, and an experimental Node.js/TypeScript interface. Unlike thin bindings, VIBETENSOR includes its own tensor/storage system, schema-lite dispatcher, reverse-mode autograd, CUDA runtime (streams/events/graphs), a stream-ordered caching allocator with diagnostics, and a stable C ABI for dynamically loaded operator plugins. We view this release as a milestone for AI-assisted software engineering: it shows coding agents can generate a coherent deep learning runtime spanning language bindings down to CUDA memory management, validated primarily by builds and tests. We describe the architecture, summarize the workflow used to produce and validate the system, and evaluate the artifact. We report repository scale and test-suite composition, and summarize reproducible microbenchmarks from an accompanying AI-generated kernel suite, including fused attention versus PyTorch SDPA/FlashAttention. We also report end-to-end training sanity checks on 3 small workloads (sequence reversal, ViT, miniGPT) on NVIDIA H100 (Hopper, SM90) and Blackwell-class GPUs; multi-GPU results are Blackwell-only and use an optional CUTLASS-based ring-allreduce plugin gated on CUDA 13+ and sm103a toolchain support. Finally, we discuss failure modes in generated system software, including a "Frankenstein" composition effect where locally correct subsystems interact to yield globally suboptimal performance.
FlashInfer-Bench: Building the Virtuous Cycle for AI-driven LLM Systems
Jan 01, 2026Recent advances show that large language models (LLMs) can act as autonomous agents capable of generating GPU kernels, but integrating these AI-generated kernels into real-world inference systems remains challenging. FlashInfer-Bench addresses this gap by establishing a standardized, closed-loop framework that connects kernel generation, benchmarking, and deployment. At its core, FlashInfer Trace provides a unified schema describing kernel definitions, workloads, implementations, and evaluations, enabling consistent communication between agents and systems. Built on real serving traces, FlashInfer-Bench includes a curated dataset, a robust correctness- and performance-aware benchmarking framework, a public leaderboard to track LLM agents' GPU programming capabilities, and a dynamic substitution mechanism (apply()) that seamlessly injects the best-performing kernels into production LLM engines such as SGLang and vLLM. Using FlashInfer-Bench, we further evaluate the performance and limitations of LLM agents, compare the trade-offs among different GPU programming languages, and provide insights for future agent design. FlashInfer-Bench thus establishes a practical, reproducible pathway for continuously improving AI-generated kernels and deploying them into large-scale LLM inference.
xKV: Cross-Layer SVD for KV-Cache Compression
Mar 24, 2025Large Language Models (LLMs) with long context windows enable powerful applications but come at the cost of high memory consumption to store the Key and Value states (KV-Cache). Recent studies attempted to merge KV-cache from multiple layers into shared representations, yet these approaches either require expensive pretraining or rely on assumptions of high per-token cosine similarity across layers which generally does not hold in practice. We find that the dominant singular vectors are remarkably well-aligned across multiple layers of the KV-Cache. Exploiting this insight, we propose xKV, a simple post-training method that applies Singular Value Decomposition (SVD) on the KV-Cache of grouped layers. xKV consolidates the KV-Cache of multiple layers into a shared low-rank subspace, significantly reducing KV-Cache sizes. Through extensive evaluations on the RULER long-context benchmark with widely-used LLMs (e.g., Llama-3.1 and Qwen2.5), xKV achieves up to 6.8x higher compression rates than state-of-the-art inter-layer technique while improving accuracy by 2.7%. Moreover, xKV is compatible with the emerging Multi-Head Latent Attention (MLA) (e.g., DeepSeek-Coder-V2), yielding a notable 3x compression rates on coding tasks without performance degradation. These results highlight xKV's strong capability and versatility in addressing memory bottlenecks for long-context LLM inference. Our code is publicly available at: https://github.com/abdelfattah-lab/xKV.
TeleRAG: Efficient Retrieval-Augmented Generation Inference with Lookahead Retrieval
Feb 28, 2025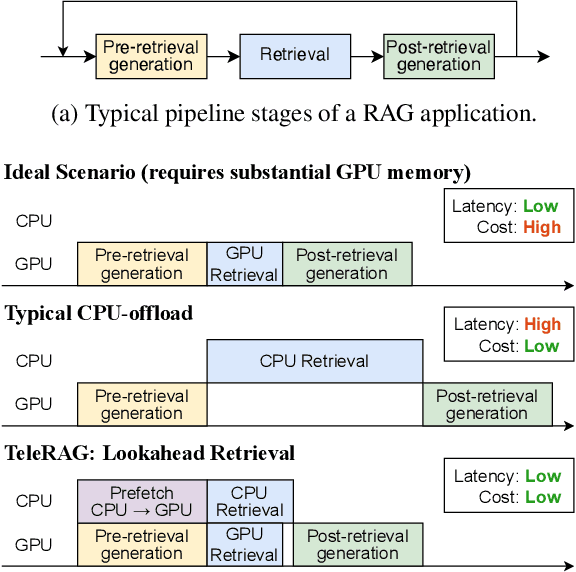



Retrieval-augmented generation (RAG) extends large language models (LLMs) with external data sources to enhance factual correctness and domain coverage. Modern RAG pipelines rely on large datastores, leading to system challenges in latency-sensitive deployments, especially when limited GPU memory is available. To address these challenges, we propose TeleRAG, an efficient inference system that reduces RAG latency with minimal GPU memory requirements. The core innovation of TeleRAG is lookahead retrieval, a prefetching mechanism that anticipates required data and transfers it from CPU to GPU in parallel with LLM generation. By leveraging the modularity of RAG pipelines, the inverted file index (IVF) search algorithm and similarities between queries, TeleRAG optimally overlaps data movement and computation. Experimental results show that TeleRAG reduces end-to-end RAG inference latency by up to 1.72x on average compared to state-of-the-art systems, enabling faster, more memory-efficient deployments of advanced RAG applications.
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving
Jan 02, 2025



Transformers, driven by attention mechanisms, form the foundation of large language models (LLMs). As these models scale up, efficient GPU attention kernels become essential for high-throughput and low-latency inference. Diverse LLM applications demand flexible and high-performance attention solutions. We present FlashInfer: a customizable and efficient attention engine for LLM serving. FlashInfer tackles KV-cache storage heterogeneity using block-sparse format and composable formats to optimize memory access and reduce redundancy. It also offers a customizable attention template, enabling adaptation to various settings through Just-In-Time (JIT) compilation. Additionally, FlashInfer's load-balanced scheduling algorithm adjusts to dynamism of user requests while maintaining compatibility with CUDAGraph which requires static configuration. FlashInfer have been integrated into leading LLM serving frameworks like SGLang, vLLM and MLC-Engine. Comprehensive kernel-level and end-to-end evaluations demonstrate FlashInfer's ability to significantly boost kernel performance across diverse inference scenarios: compared to state-of-the-art LLM serving solutions, FlashInfer achieve 29-69% inter-token-latency reduction compared to compiler backends for LLM serving benchmark, 28-30% latency reduction for long-context inference, and 13-17% speedup for LLM serving with parallel generation.
Palu: Compressing KV-Cache with Low-Rank Projection
Jul 30, 2024



KV-Cache compression methods generally sample a KV-Cache of effectual tokens or quantize it into lower bits. However, these methods cannot exploit the redundancy of the hidden dimension of KV tensors. This paper investigates a unique hidden dimension approach called Palu, a novel KV-Cache compression framework that utilizes low-rank projection. Palu decomposes the linear layers into low-rank matrices, caches the smaller intermediate states, and reconstructs the full keys and values on the fly. To improve accuracy, compression rate, and efficiency, Palu further encompasses (1) a medium-grained low-rank decomposition scheme, (2) an efficient rank search algorithm, (3) a low-rank-aware quantization algorithm, and (4) matrix fusion with optimized GPU kernels. Our extensive experiments with popular LLMs show that Palu can compress KV-Cache by more than 91.25% while maintaining a significantly better accuracy (up to 1.19 lower perplexity) than state-of-the-art KV-Cache quantization methods at a similar or even higher memory usage. When compressing KV-Cache for 50%, Palu delivers up to 1.61x end-to-end speedup for the attention module. Our code is publicly available at https://github.com/shadowpa0327/Palu.
Atom: Low-bit Quantization for Efficient and Accurate LLM Serving
Nov 07, 2023



The growing demand for Large Language Models (LLMs) in applications such as content generation, intelligent chatbots, and sentiment analysis poses considerable challenges for LLM service providers. To efficiently use GPU resources and boost throughput, batching multiple requests has emerged as a popular paradigm; to further speed up batching, LLM quantization techniques reduce memory consumption and increase computing capacity. However, prevalent quantization schemes (e.g., 8-bit weight-activation quantization) cannot fully leverage the capabilities of modern GPUs, such as 4-bit integer operators, resulting in sub-optimal performance. To maximize LLMs' serving throughput, we introduce Atom, a low-bit quantization method that achieves high throughput improvements with negligible accuracy loss. Atom significantly boosts serving throughput by using low-bit operators and considerably reduces memory consumption via low-bit quantization. It attains high accuracy by applying a novel mixed-precision and fine-grained quantization process. We evaluate Atom on 4-bit weight-activation quantization setups in the serving context. Atom improves end-to-end throughput by up to $7.73\times$ compared to the FP16 and by $2.53\times$ compared to INT8 quantization, while maintaining the same latency target.
Punica: Multi-Tenant LoRA Serving
Oct 28, 2023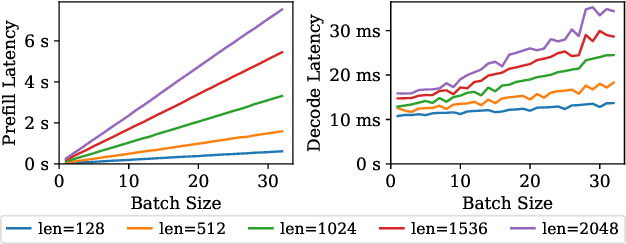
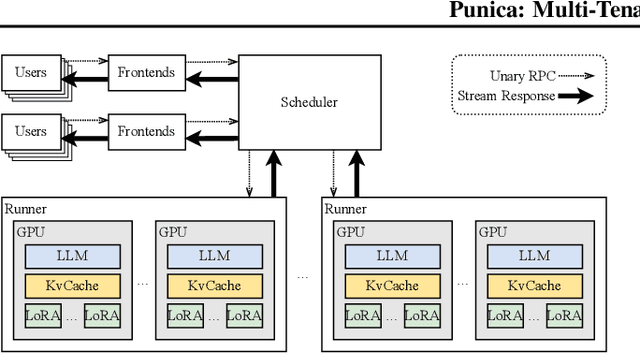
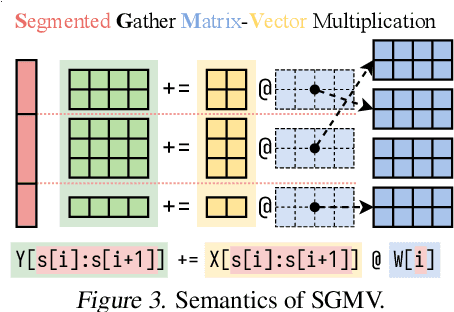
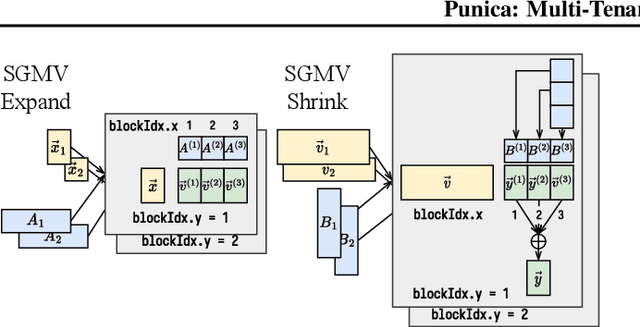
Low-rank adaptation (LoRA) has become an important and popular method to adapt pre-trained models to specific domains. We present Punica, a system to serve multiple LoRA models in a shared GPU cluster. Punica contains a new CUDA kernel design that allows batching of GPU operations for different LoRA models. This allows a GPU to hold only a single copy of the underlying pre-trained model when serving multiple, different LoRA models, significantly enhancing GPU efficiency in terms of both memory and computation. Our scheduler consolidates multi-tenant LoRA serving workloads in a shared GPU cluster. With a fixed-sized GPU cluster, our evaluations show that Punica achieves 12x higher throughput in serving multiple LoRA models compared to state-of-the-art LLM serving systems while only adding 2ms latency per token. Punica is open source at https://github.com/punica-ai/punica .