 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkipCat: Rank-Maximized Low-Rank Compression of Large Language Models via Shared Projection and Block Skipping
Dec 15, 2025Large language models (LLM) have achieved remarkable performance across a wide range of tasks. However, their substantial parameter sizes pose significant challenges for deployment on edge devices with limited computational and memory resources. Low-rank compression is a promising approach to address this issue, as it reduces both computational and memory costs, making LLM more suitable for resource-constrained environments. Nonetheless, naïve low-rank compression methods require a significant reduction in the retained rank to achieve meaningful memory and computation savings. For a low-rank model, the ranks need to be reduced by more than half to yield efficiency gains. Such aggressive truncation, however, typically results in substantial performance degradation. To address this trade-off, we propose SkipCat, a novel low-rank compression framework that enables the use of higher ranks while achieving the same compression rates. First, we introduce an intra-layer shared low-rank projection method, where multiple matrices that share the same input use a common projection. This reduces redundancy and improves compression efficiency. Second, we propose a block skipping technique that omits computations and memory transfers for selected sub-blocks within the low-rank decomposition. These two techniques jointly enable our compressed model to retain more effective ranks under the same compression budget. Experimental results show that, without any additional fine-tuning, our method outperforms previous low-rank compression approaches by 7% accuracy improvement on zero-shot tasks under the same compression rate. These results highlight the effectiveness of our rank-maximized compression strategy in preserving model performance under tight resource constraints.
Palu: Compressing KV-Cache with Low-Rank Projection
Jul 30, 2024



KV-Cache compression methods generally sample a KV-Cache of effectual tokens or quantize it into lower bits. However, these methods cannot exploit the redundancy of the hidden dimension of KV tensors. This paper investigates a unique hidden dimension approach called Palu, a novel KV-Cache compression framework that utilizes low-rank projection. Palu decomposes the linear layers into low-rank matrices, caches the smaller intermediate states, and reconstructs the full keys and values on the fly. To improve accuracy, compression rate, and efficiency, Palu further encompasses (1) a medium-grained low-rank decomposition scheme, (2) an efficient rank search algorithm, (3) a low-rank-aware quantization algorithm, and (4) matrix fusion with optimized GPU kernels. Our extensive experiments with popular LLMs show that Palu can compress KV-Cache by more than 91.25% while maintaining a significantly better accuracy (up to 1.19 lower perplexity) than state-of-the-art KV-Cache quantization methods at a similar or even higher memory usage. When compressing KV-Cache for 50%, Palu delivers up to 1.61x end-to-end speedup for the attention module. Our code is publicly available at https://github.com/shadowpa0327/Palu.
Q-YOLOP: Quantization-aware You Only Look Once for Panoptic Driving Perception
Jul 10, 2023
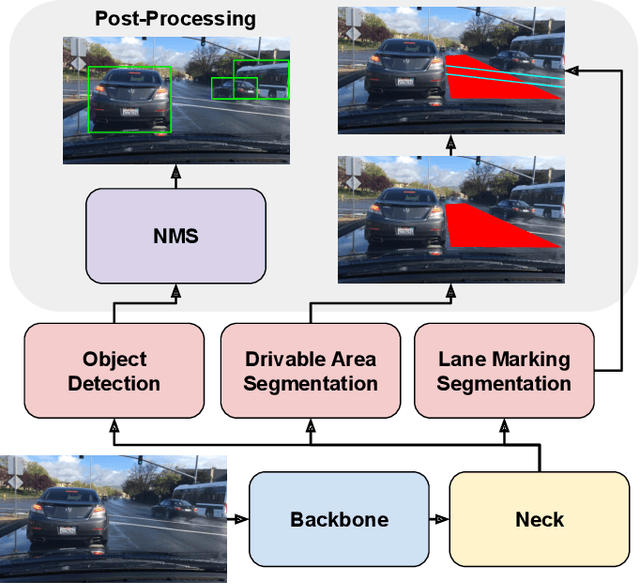

In this work, we present an efficient and quantization-aware panoptic driving perception model (Q- YOLOP) for object detection, drivable area segmentation, and lane line segmentation, in the context of autonomous driving. Our model employs the Efficient Layer Aggregation Network (ELAN) as its backbone and task-specific heads for each task. We employ a four-stage training process that includes pretraining on the BDD100K dataset, finetuning on both the BDD100K and iVS datasets, and quantization-aware training (QAT) on BDD100K. During the training process, we use powerful data augmentation techniques, such as random perspective and mosaic, and train the model on a combination of the BDD100K and iVS datasets. Both strategies enhance the model's generalization capabilities. The proposed model achieves state-of-the-art performance with an mAP@0.5 of 0.622 for object detection and an mIoU of 0.612 for segmentation, while maintaining low computational and memory requirements.