 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGazeNLQ @ Ego4D Natural Language Queries Challenge 2025
Jun 06, 2025This report presents our solution to the Ego4D Natural Language Queries (NLQ) Challenge at CVPR 2025. Egocentric video captures the scene from the wearer's perspective, where gaze serves as a key non-verbal communication cue that reflects visual attention and offer insights into human intention and cognition. Motivated by this, we propose a novel approach, GazeNLQ, which leverages gaze to retrieve video segments that match given natural language queries. Specifically, we introduce a contrastive learning-based pretraining strategy for gaze estimation directly from video. The estimated gaze is used to augment video representations within proposed model, thereby enhancing localization accuracy. Experimental results show that GazeNLQ achieves R1@IoU0.3 and R1@IoU0.5 scores of 27.82 and 18.68, respectively. Our code is available at https://github.com/stevenlin510/GazeNLQ.
Mind the Prompt: Prompting Strategies in Audio Generations for Improving Sound Classification
Apr 04, 2025



This paper investigates the design of effective prompt strategies for generating realistic datasets using Text-To-Audio (TTA) models. We also analyze different techniques for efficiently combining these datasets to enhance their utility in sound classification tasks. By evaluating two sound classification datasets with two TTA models, we apply a range of prompt strategies. Our findings reveal that task-specific prompt strategies significantly outperform basic prompt approaches in data generation. Furthermore, merging datasets generated using different TTA models proves to enhance classification performance more effectively than merely increasing the training dataset size. Overall, our results underscore the advantages of these methods as effective data augmentation techniques using synthetic data.
xKV: Cross-Layer SVD for KV-Cache Compression
Mar 24, 2025Large Language Models (LLMs) with long context windows enable powerful applications but come at the cost of high memory consumption to store the Key and Value states (KV-Cache). Recent studies attempted to merge KV-cache from multiple layers into shared representations, yet these approaches either require expensive pretraining or rely on assumptions of high per-token cosine similarity across layers which generally does not hold in practice. We find that the dominant singular vectors are remarkably well-aligned across multiple layers of the KV-Cache. Exploiting this insight, we propose xKV, a simple post-training method that applies Singular Value Decomposition (SVD) on the KV-Cache of grouped layers. xKV consolidates the KV-Cache of multiple layers into a shared low-rank subspace, significantly reducing KV-Cache sizes. Through extensive evaluations on the RULER long-context benchmark with widely-used LLMs (e.g., Llama-3.1 and Qwen2.5), xKV achieves up to 6.8x higher compression rates than state-of-the-art inter-layer technique while improving accuracy by 2.7%. Moreover, xKV is compatible with the emerging Multi-Head Latent Attention (MLA) (e.g., DeepSeek-Coder-V2), yielding a notable 3x compression rates on coding tasks without performance degradation. These results highlight xKV's strong capability and versatility in addressing memory bottlenecks for long-context LLM inference. Our code is publicly available at: https://github.com/abdelfattah-lab/xKV.
ELSA: Exploiting Layer-wise N:M Sparsity for Vision Transformer Acceleration
Sep 15, 2024
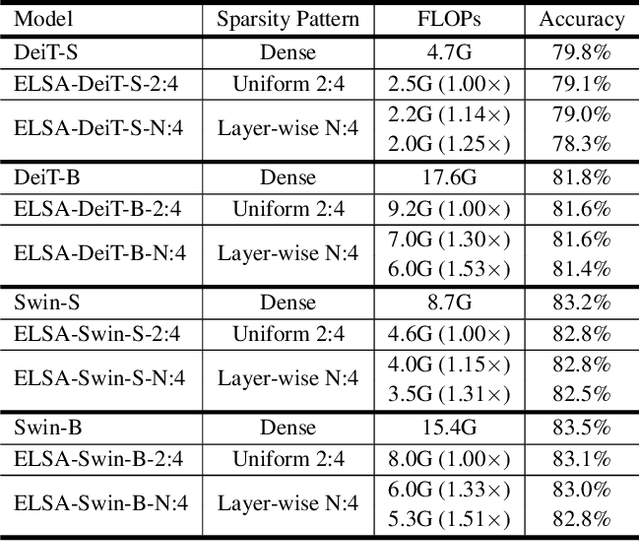
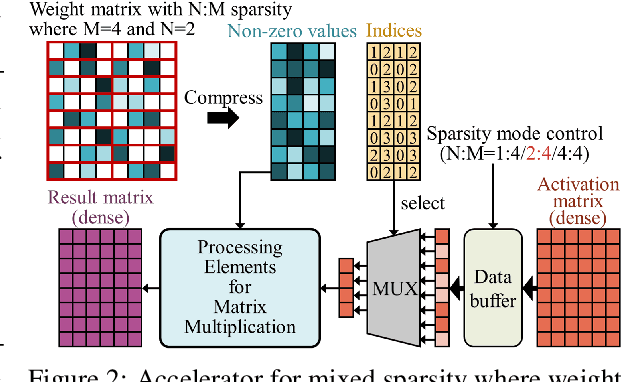
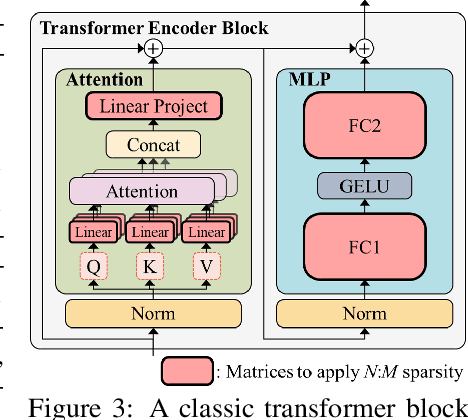
$N{:}M$ sparsity is an emerging model compression method supported by more and more accelerators to speed up sparse matrix multiplication in deep neural networks. Most existing $N{:}M$ sparsity methods compress neural networks with a uniform setting for all layers in a network or heuristically determine the layer-wise configuration by considering the number of parameters in each layer. However, very few methods have been designed for obtaining a layer-wise customized $N{:}M$ sparse configuration for vision transformers (ViTs), which usually consist of transformer blocks involving the same number of parameters. In this work, to address the challenge of selecting suitable sparse configuration for ViTs on $N{:}M$ sparsity-supporting accelerators, we propose ELSA, Exploiting Layer-wise $N{:}M$ Sparsity for ViTs. Considering not only all $N{:}M$ sparsity levels supported by a given accelerator but also the expected throughput improvement, our methodology can reap the benefits of accelerators supporting mixed sparsity by trading off negligible accuracy loss with both memory usage and inference time reduction for ViT models. For instance, our approach achieves a noteworthy 2.9$\times$ reduction in FLOPs for both Swin-B and DeiT-B with only a marginal degradation of accuracy on ImageNet. Our code will be released upon paper acceptance.
Palu: Compressing KV-Cache with Low-Rank Projection
Jul 30, 2024



KV-Cache compression methods generally sample a KV-Cache of effectual tokens or quantize it into lower bits. However, these methods cannot exploit the redundancy of the hidden dimension of KV tensors. This paper investigates a unique hidden dimension approach called Palu, a novel KV-Cache compression framework that utilizes low-rank projection. Palu decomposes the linear layers into low-rank matrices, caches the smaller intermediate states, and reconstructs the full keys and values on the fly. To improve accuracy, compression rate, and efficiency, Palu further encompasses (1) a medium-grained low-rank decomposition scheme, (2) an efficient rank search algorithm, (3) a low-rank-aware quantization algorithm, and (4) matrix fusion with optimized GPU kernels. Our extensive experiments with popular LLMs show that Palu can compress KV-Cache by more than 91.25% while maintaining a significantly better accuracy (up to 1.19 lower perplexity) than state-of-the-art KV-Cache quantization methods at a similar or even higher memory usage. When compressing KV-Cache for 50%, Palu delivers up to 1.61x end-to-end speedup for the attention module. Our code is publicly available at https://github.com/shadowpa0327/Palu.
Q-YOLOP: Quantization-aware You Only Look Once for Panoptic Driving Perception
Jul 10, 2023
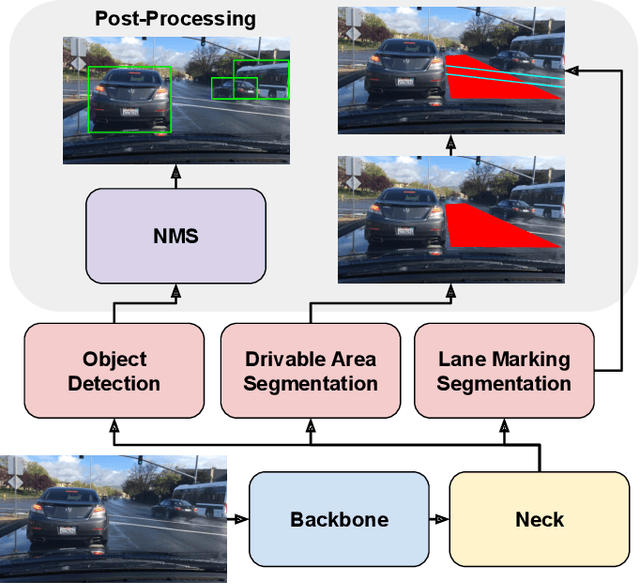

In this work, we present an efficient and quantization-aware panoptic driving perception model (Q- YOLOP) for object detection, drivable area segmentation, and lane line segmentation, in the context of autonomous driving. Our model employs the Efficient Layer Aggregation Network (ELAN) as its backbone and task-specific heads for each task. We employ a four-stage training process that includes pretraining on the BDD100K dataset, finetuning on both the BDD100K and iVS datasets, and quantization-aware training (QAT) on BDD100K. During the training process, we use powerful data augmentation techniques, such as random perspective and mosaic, and train the model on a combination of the BDD100K and iVS datasets. Both strategies enhance the model's generalization capabilities. The proposed model achieves state-of-the-art performance with an mAP@0.5 of 0.622 for object detection and an mIoU of 0.612 for segmentation, while maintaining low computational and memory requirements.
Versatile Audio-Visual Learning for Handling Single and Multi Modalities in Emotion Regression and Classification Tasks
May 12, 2023



Most current audio-visual emotion recognition models lack the flexibility needed for deployment in practical applications. We envision a multimodal system that works even when only one modality is available and can be implemented interchangeably for either predicting emotional attributes or recognizing categorical emotions. Achieving such flexibility in a multimodal emotion recognition system is difficult due to the inherent challenges in accurately interpreting and integrating varied data sources. It is also a challenge to robustly handle missing or partial information while allowing direct switch between regression and classification tasks. This study proposes a \emph{versatile audio-visual learning} (VAVL) framework for handling unimodal and multimodal systems for emotion regression and emotion classification tasks. We implement an audio-visual framework that can be trained even when audio and visual paired data is not available for part of the training set (i.e., audio only or only video is present). We achieve this effective representation learning with audio-visual shared layers, residual connections over shared layers, and a unimodal reconstruction task. Our experimental results reveal that our architecture significantly outperforms strong baselines on both the CREMA-D and MSP-IMPROV corpora. Notably, VAVL attains a new state-of-the-art performance in the emotional attribute prediction task on the MSP-IMPROV corpus. Code available at: https://github.com/ilucasgoncalves/VAVL