 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELSA: Exploiting Layer-wise N:M Sparsity for Vision Transformer Acceleration
Paper and Code
Sep 15, 2024
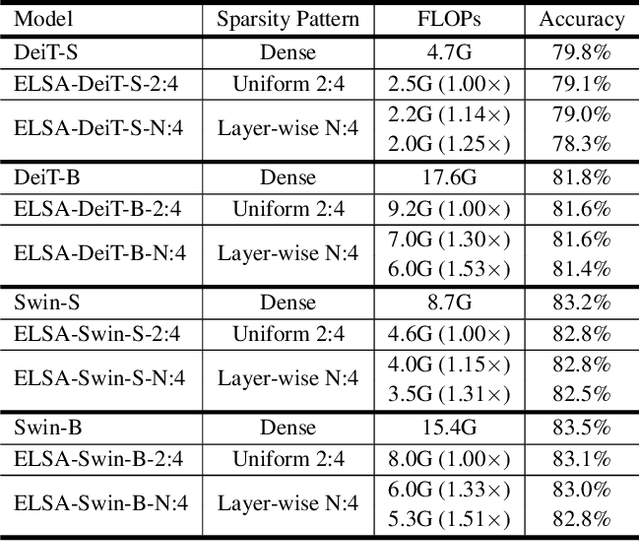
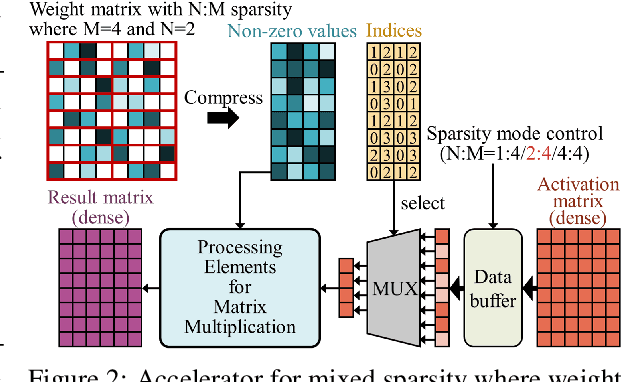
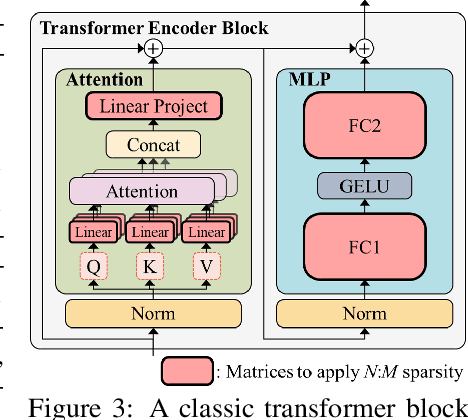
$N{:}M$ sparsity is an emerging model compression method supported by more and more accelerators to speed up sparse matrix multiplication in deep neural networks. Most existing $N{:}M$ sparsity methods compress neural networks with a uniform setting for all layers in a network or heuristically determine the layer-wise configuration by considering the number of parameters in each layer. However, very few methods have been designed for obtaining a layer-wise customized $N{:}M$ sparse configuration for vision transformers (ViTs), which usually consist of transformer blocks involving the same number of parameters. In this work, to address the challenge of selecting suitable sparse configuration for ViTs on $N{:}M$ sparsity-supporting accelerators, we propose ELSA, Exploiting Layer-wise $N{:}M$ Sparsity for ViTs. Considering not only all $N{:}M$ sparsity levels supported by a given accelerator but also the expected throughput improvement, our methodology can reap the benefits of accelerators supporting mixed sparsity by trading off negligible accuracy loss with both memory usage and inference time reduction for ViT models. For instance, our approach achieves a noteworthy 2.9$\times$ reduction in FLOPs for both Swin-B and DeiT-B with only a marginal degradation of accuracy on ImageNet. Our code will be released upon paper acceptance.