 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeo-OLM: Enabling Sustainable Earth Observation Studies with Cost-Efficient Open Language Models & State-Driven Workflows
Apr 06, 2025Geospatial Copilots hold immense potential for automating Earth observation (EO) and climate monitoring workflows, yet their reliance on large-scale models such as GPT-4o introduces a paradox: tools intended for sustainability studies often incur unsustainable costs. Using agentic AI frameworks in geospatial applications can amass thousands of dollars in API charges or requires expensive, power-intensive GPUs for deployment, creating barriers for researchers, policymakers, and NGOs. Unfortunately, when geospatial Copilots are deployed with open language models (OLMs), performance often degrades due to their dependence on GPT-optimized logic. In this paper, we present Geo-OLM, a tool-augmented geospatial agent that leverages the novel paradigm of state-driven LLM reasoning to decouple task progression from tool calling. By alleviating the workflow reasoning burden, our approach enables low-resource OLMs to complete geospatial tasks more effectively. When downsizing to small models below 7B parameters, Geo-OLM outperforms the strongest prior geospatial baselines by 32.8% in successful query completion rates. Our method performs comparably to proprietary models achieving results within 10% of GPT-4o, while reducing inference costs by two orders of magnitude from \$500-\$1000 to under \$10. We present an in-depth analysis with geospatial downstream benchmarks, providing key insights to help practitioners effectively deploy OLMs for EO applications.
Quamba2: A Robust and Scalable Post-training Quantization Framework for Selective State Space Models
Mar 28, 2025State Space Models (SSMs) are emerging as a compelling alternative to Transformers because of their consistent memory usage and high performance. Despite this, scaling up SSMs on cloud services or limited-resource devices is challenging due to their storage requirements and computational power. To overcome this, quantizing SSMs with low bit-width data formats can reduce model size and benefit from hardware acceleration. As SSMs are prone to quantization-induced errors, recent efforts have focused on optimizing a particular model or bit-width for efficiency without sacrificing performance. However, distinct bit-width configurations are essential for different scenarios, like W4A8 for boosting large-batch decoding speed, and W4A16 for enhancing generation speed in short prompt applications for a single user. To this end, we present Quamba2, compatible with W8A8, W4A8, and W4A16 for both Mamba1 and Mamba2 backbones, addressing the growing demand for SSM deployment on various platforms. Based on the channel order preserving and activation persistence of SSMs, we propose an offline approach to quantize inputs of a linear recurrence in 8-bit by sorting and clustering for input $x$, combined with a per-state-group quantization for input-dependent parameters $B$ and $C$. To ensure compute-invariance in the SSM output, we rearrange weights offline according to the clustering sequence. The experiments show that Quamba2-8B outperforms several state-of-the-art SSM quantization methods and delivers 1.3$\times$ and 3$\times$ speed-ups in the pre-filling and generation stages, respectively, while offering 4$\times$ memory reduction with only a $1.6\%$ average accuracy drop. The evaluation on MMLU shows the generalizability and robustness of our framework. The code and quantized models will be released at: https://github.com/enyac-group/Quamba.
Similarity Trajectories: Linking Sampling Process to Artifacts in Diffusion-Generated Images
Dec 22, 2024Artifact detection algorithms are crucial to correcting the output generated by diffusion models. However, because of the variety of artifact forms, existing methods require substantial annotated data for training. This requirement limits their scalability and efficiency, which restricts their wide application. This paper shows that the similarity of denoised images between consecutive time steps during the sampling process is related to the severity of artifacts in images generated by diffusion models. Building on this observation, we introduce the concept of Similarity Trajectory to characterize the sampling process and its correlation with the image artifacts presented. Using an annotated data set of 680 images, which is only 0.1% of the amount of data used in the prior work, we trained a classifier on these trajectories to predict the presence of artifacts in images. By performing 10-fold validation testing on the balanced annotated data set, the classifier can achieve an accuracy of 72.35%, highlighting the connection between the Similarity Trajectory and the occurrence of artifacts. This approach enables differentiation between artifact-exhibiting and natural-looking images using limited training data.
DQRM: Deep Quantized Recommendation Models
Oct 26, 2024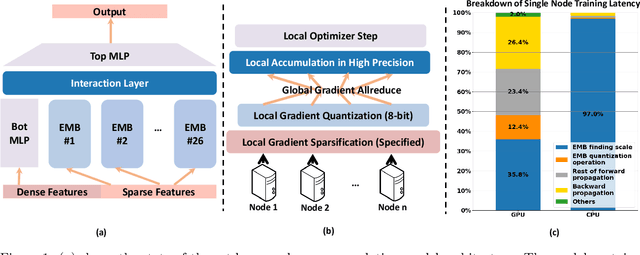
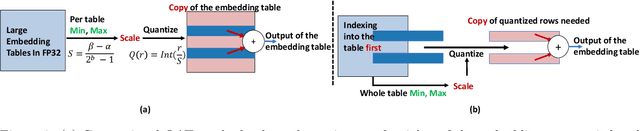

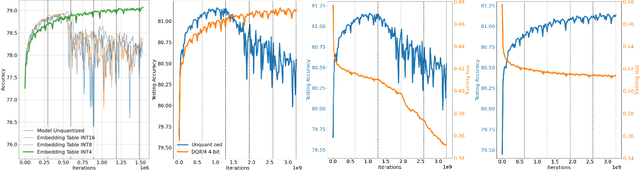
Large-scale recommendation models are currently the dominant workload for many large Internet companies. These recommenders are characterized by massive embedding tables that are sparsely accessed by the index for user and item features. The size of these 1TB+ tables imposes a severe memory bottleneck for the training and inference of recommendation models. In this work, we propose a novel recommendation framework that is small, powerful, and efficient to run and train, based on the state-of-the-art Deep Learning Recommendation Model (DLRM). The proposed framework makes inference more efficient on the cloud servers, explores the possibility of deploying powerful recommenders on smaller edge devices, and optimizes the workload of the communication overhead in distributed training under the data parallelism settings. Specifically, we show that quantization-aware training (QAT) can impose a strong regularization effect to mitigate the severe overfitting issues suffered by DLRMs. Consequently, we achieved INT4 quantization of DLRM models without any accuracy drop. We further propose two techniques that improve and accelerate the conventional QAT workload specifically for the embedding tables in the recommendation models. Furthermore, to achieve efficient training, we quantize the gradients of the embedding tables into INT8 on top of the well-supported specified sparsification. We show that combining gradient sparsification and quantization together significantly reduces the amount of communication. Briefly, DQRM models with INT4 can achieve 79.07% accuracy on Kaggle with 0.27 GB model size, and 81.21% accuracy on the Terabyte dataset with 1.57 GB, which even outperform FP32 DLRMs that have much larger model sizes (2.16 GB on Kaggle and 12.58 on Terabyte).
Quamba: A Post-Training Quantization Recipe for Selective State Space Models
Oct 17, 2024State Space Models (SSMs) have emerged as an appealing alternative to Transformers for large language models, achieving state-of-the-art accuracy with constant memory complexity which allows for holding longer context lengths than attention-based networks. The superior computational efficiency of SSMs in long sequence modeling positions them favorably over Transformers in many scenarios. However, improving the efficiency of SSMs on request-intensive cloud-serving and resource-limited edge applications is still a formidable task. SSM quantization is a possible solution to this problem, making SSMs more suitable for wide deployment, while still maintaining their accuracy. Quantization is a common technique to reduce the model size and to utilize the low bit-width acceleration features on modern computing units, yet existing quantization techniques are poorly suited for SSMs. Most notably, SSMs have highly sensitive feature maps within the selective scan mechanism (i.e., linear recurrence) and massive outliers in the output activations which are not present in the output of token-mixing in the self-attention modules. To address this issue, we propose a static 8-bit per-tensor SSM quantization method which suppresses the maximum values of the input activations to the selective SSM for finer quantization precision and quantizes the output activations in an outlier-free space with Hadamard transform. Our 8-bit weight-activation quantized Mamba 2.8B SSM benefits from hardware acceleration and achieves a 1.72x lower generation latency on an Nvidia Orin Nano 8G, with only a 0.9% drop in average accuracy on zero-shot tasks. The experiments demonstrate the effectiveness and practical applicability of our approach for deploying SSM-based models of all sizes on both cloud and edge platforms.
OpenSep: Leveraging Large Language Models with Textual Inversion for Open World Audio Separation
Sep 28, 2024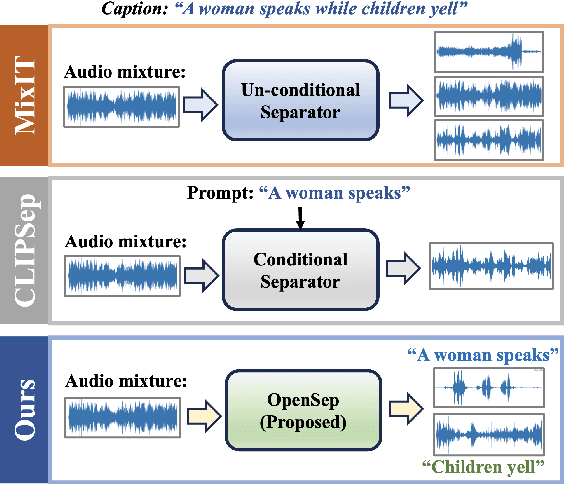

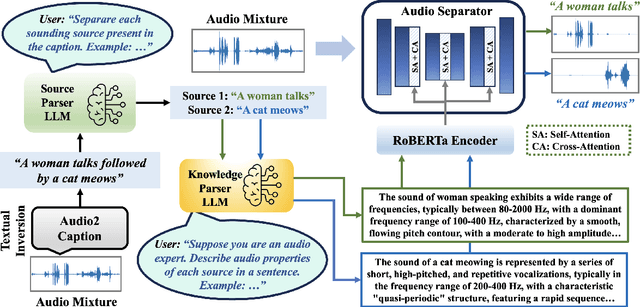
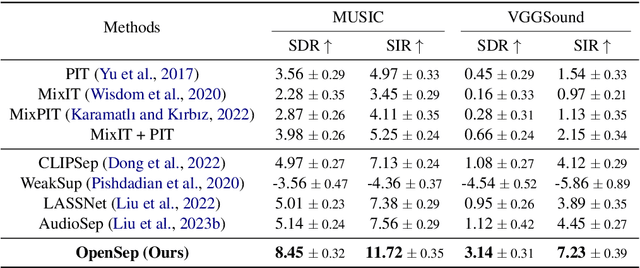
Audio separation in real-world scenarios, where mixtures contain a variable number of sources, presents significant challenges due to limitations of existing models, such as over-separation, under-separation, and dependence on predefined training sources. We propose OpenSep, a novel framework that leverages large language models (LLMs) for automated audio separation, eliminating the need for manual intervention and overcoming source limitations. OpenSep uses textual inversion to generate captions from audio mixtures with off-the-shelf audio captioning models, effectively parsing the sound sources present. It then employs few-shot LLM prompting to extract detailed audio properties of each parsed source, facilitating separation in unseen mixtures. Additionally, we introduce a multi-level extension of the mix-and-separate training framework to enhance modality alignment by separating single source sounds and mixtures simultaneously. Extensive experiments demonstrate OpenSep's superiority in precisely separating new, unseen, and variable sources in challenging mixtures, outperforming SOTA baseline methods. Code is released at https://github.com/tanvir-utexas/OpenSep.git
ELSA: Exploiting Layer-wise N:M Sparsity for Vision Transformer Acceleration
Sep 15, 2024
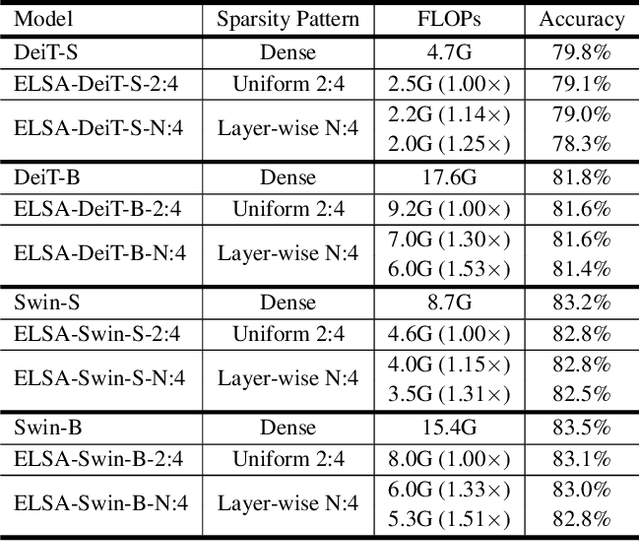
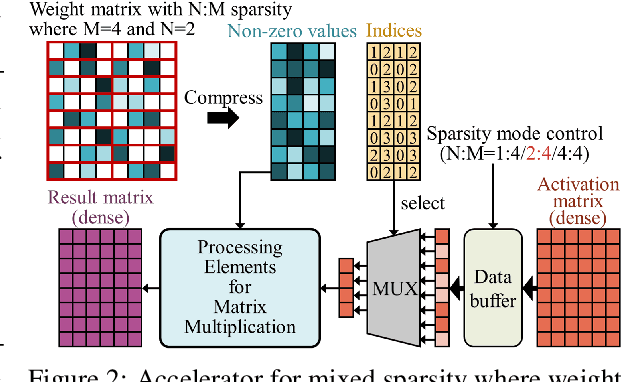
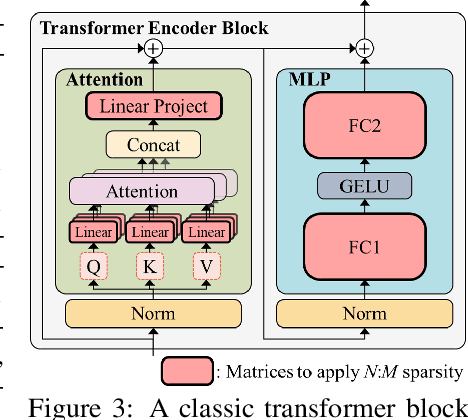
$N{:}M$ sparsity is an emerging model compression method supported by more and more accelerators to speed up sparse matrix multiplication in deep neural networks. Most existing $N{:}M$ sparsity methods compress neural networks with a uniform setting for all layers in a network or heuristically determine the layer-wise configuration by considering the number of parameters in each layer. However, very few methods have been designed for obtaining a layer-wise customized $N{:}M$ sparse configuration for vision transformers (ViTs), which usually consist of transformer blocks involving the same number of parameters. In this work, to address the challenge of selecting suitable sparse configuration for ViTs on $N{:}M$ sparsity-supporting accelerators, we propose ELSA, Exploiting Layer-wise $N{:}M$ Sparsity for ViTs. Considering not only all $N{:}M$ sparsity levels supported by a given accelerator but also the expected throughput improvement, our methodology can reap the benefits of accelerators supporting mixed sparsity by trading off negligible accuracy loss with both memory usage and inference time reduction for ViT models. For instance, our approach achieves a noteworthy 2.9$\times$ reduction in FLOPs for both Swin-B and DeiT-B with only a marginal degradation of accuracy on ImageNet. Our code will be released upon paper acceptance.
SCAN-Edge: Finding MobileNet-speed Hybrid Networks for Diverse Edge Devices via Hardware-Aware Evolutionary Search
Aug 27, 2024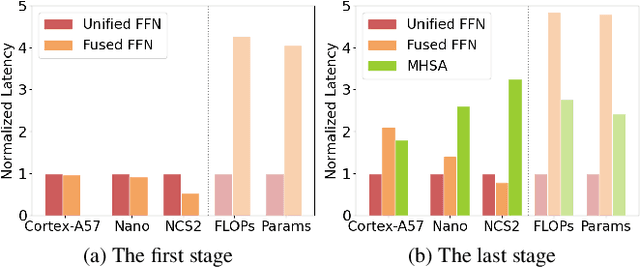
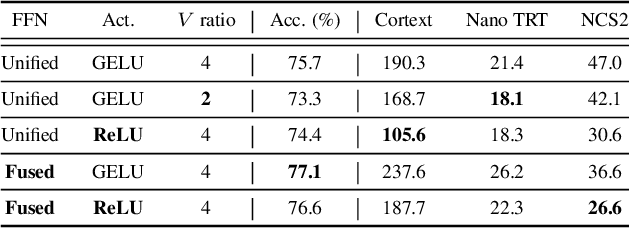
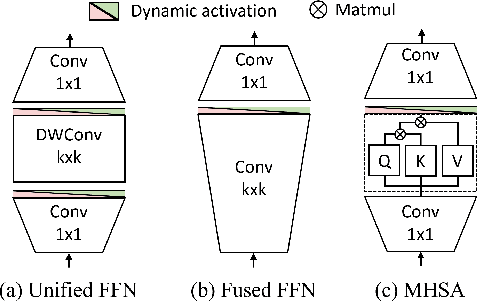
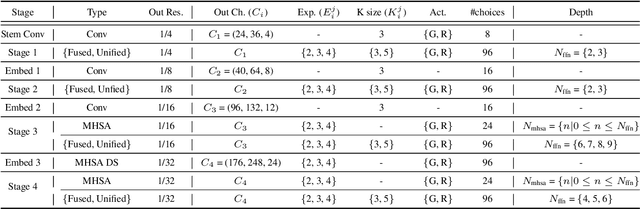
Designing low-latency and high-efficiency hybrid networks for a variety of low-cost commodity edge devices is both costly and tedious, leading to the adoption of hardware-aware neural architecture search (NAS) for finding optimal architectures. However, unifying NAS for a wide range of edge devices presents challenges due to the variety of hardware designs, supported operations, and compilation optimizations. Existing methods often fix the search space of architecture choices (e.g., activation, convolution, or self-attention) and estimate latency using hardware-agnostic proxies (e.g., FLOPs), which fail to achieve proclaimed latency across various edge devices. To address this issue, we propose SCAN-Edge, a unified NAS framework that jointly searches for self-attention, convolution, and activation to accommodate the wide variety of edge devices, including CPU-, GPU-, and hardware accelerator-based systems. To handle the large search space, SCAN-Edge relies on with a hardware-aware evolutionary algorithm that improves the quality of the search space to accelerate the sampling process. Experiments on large-scale datasets demonstrate that our hybrid networks match the actual MobileNetV2 latency for 224x224 input resolution on various commodity edge devices.
MA-AVT: Modality Alignment for Parameter-Efficient Audio-Visual Transformers
Jun 07, 2024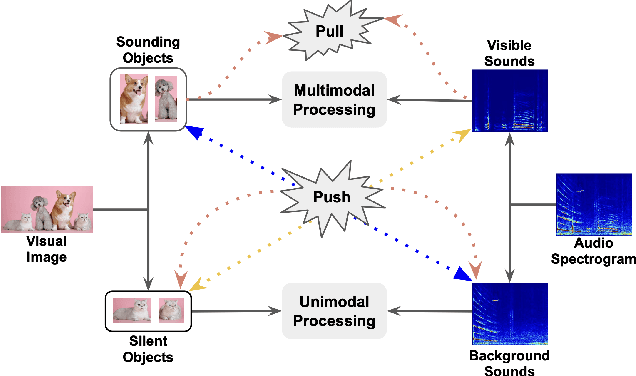
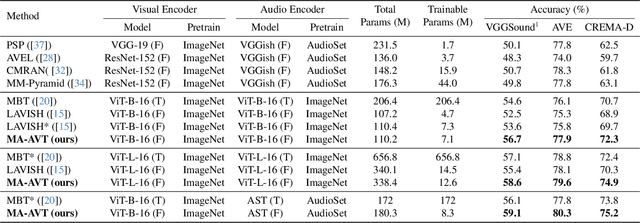
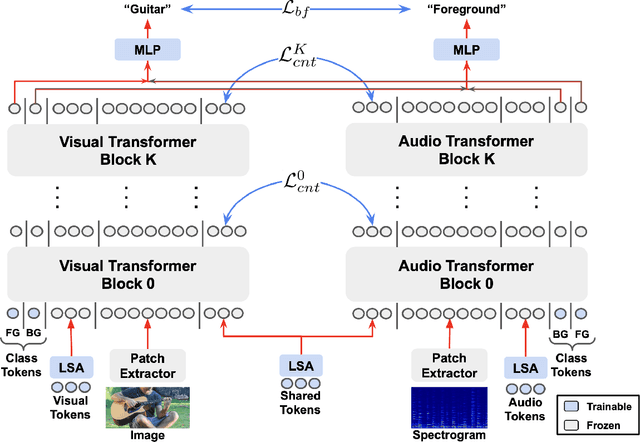
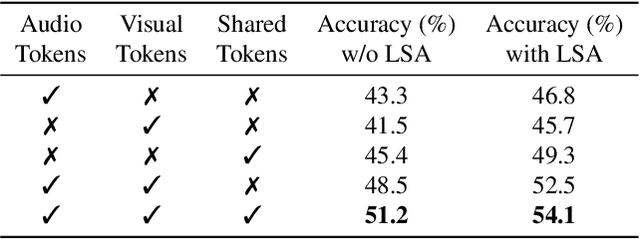
Recent advances in pre-trained vision transformers have shown promise in parameter-efficient audio-visual learning without audio pre-training. However, few studies have investigated effective methods for aligning multimodal features in parameter-efficient audio-visual transformers. In this paper, we propose MA-AVT, a new parameter-efficient audio-visual transformer employing deep modality alignment for corresponding multimodal semantic features. Specifically, we introduce joint unimodal and multimodal token learning for aligning the two modalities with a frozen modality-shared transformer. This allows the model to learn separate representations for each modality, while also attending to the cross-modal relationships between them. In addition, unlike prior work that only aligns coarse features from the output of unimodal encoders, we introduce blockwise contrastive learning to align coarse-to-fine-grain hierarchical features throughout the encoding phase. Furthermore, to suppress the background features in each modality from foreground matched audio-visual features, we introduce a robust discriminative foreground mining scheme. Through extensive experiments on benchmark AVE, VGGSound, and CREMA-D datasets, we achieve considerable performance improvements over SOTA methods.
Ada-VE: Training-Free Consistent Video Editing Using Adaptive Motion Prior
Jun 07, 2024
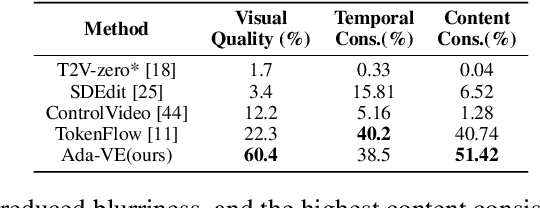
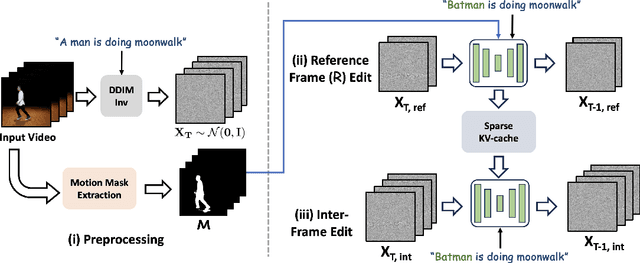

Video-to-video synthesis models face significant challenges, such as ensuring consistent character generation across frames, maintaining smooth temporal transitions, and preserving quality during fast motion. The introduction of joint fully cross-frame self-attention mechanisms has improved character consistency, but this comes at the cost of increased computational complexity. This full cross-frame self-attention mechanism also incorporates redundant details and limits the number of frames that can be jointly edited due to its computational cost. Moreover, the lack of frames in cross-frame attention adversely affects temporal consistency and visual quality. To address these limitations, we propose a new adaptive motion-guided cross-frame attention mechanism that drastically reduces complexity while preserving semantic details and temporal consistency. Specifically, we selectively incorporate the moving regions of successive frames in cross-frame attention and sparsely include stationary regions based on optical flow sampling. This technique allows for an increased number of jointly edited frames without additional computational overhead. For longer duration of video editing, existing methods primarily focus on frame interpolation or flow-warping from jointly edited keyframes, which often results in blurry frames or reduced temporal consistency. To improve this, we introduce KV-caching of jointly edited frames and reuse the same KV across all intermediate frames, significantly enhancing both intermediate frame quality and temporal consistency. Overall, our motion-sampling method enables the use of around three times more keyframes than existing joint editing methods while maintaining superior prediction quality. Ada-VE achieves up to 4x speed-up when using fully-extended self-attention across 40 frames for joint editing, without compromising visual quality or temporal consistency.