 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePowerChain: Automating Distribution Grid Analysis with Agentic AI Workflows
Aug 23, 2025Due to the rapid pace of electrification and decarbonization, distribution grid (DG) operation and planning are becoming more complex, necessitating advanced computational analyses to ensure grid reliability and resilience. State-of-the-art DG analyses rely on disparate workflows of complex models, functions, and data pipelines, which require expert knowledge and are challenging to automate. Many small-scale utilities and cooperatives lack a large R&D workforce and therefore cannot use advanced analysis at scale. To address this gap, we develop a novel agentic AI system, PowerChain, to solve unseen DG analysis tasks via automated agentic orchestration and large language models (LLMs) function-calling. Given a natural language query, PowerChain dynamically generates and executes an ordered sequence of domain-aware functions guided by the semantics of an expert-built power systems function pool and a select reference set of known, expert-generated workflow-query pairs. Our results show that PowerChain can produce expert-level workflows with both GPT-5 and open-source Qwen models on complex, unseen DG analysis tasks operating on real utility data.
CarbonCall: Sustainability-Aware Function Calling for Large Language Models on Edge Devices
Apr 29, 2025Large Language Models (LLMs) enable real-time function calling in edge AI systems but introduce significant computational overhead, leading to high power consumption and carbon emissions. Existing methods optimize for performance while neglecting sustainability, making them inefficient for energy-constrained environments. We introduce CarbonCall, a sustainability-aware function-calling framework that integrates dynamic tool selection, carbon-aware execution, and quantized LLM adaptation. CarbonCall adjusts power thresholds based on real-time carbon intensity forecasts and switches between model variants to sustain high tokens-per-second throughput under power constraints. Experiments on an NVIDIA Jetson AGX Orin show that CarbonCall reduces carbon emissions by up to 52%, power consumption by 30%, and execution time by 30%, while maintaining high efficiency.
Geo-OLM: Enabling Sustainable Earth Observation Studies with Cost-Efficient Open Language Models & State-Driven Workflows
Apr 06, 2025Geospatial Copilots hold immense potential for automating Earth observation (EO) and climate monitoring workflows, yet their reliance on large-scale models such as GPT-4o introduces a paradox: tools intended for sustainability studies often incur unsustainable costs. Using agentic AI frameworks in geospatial applications can amass thousands of dollars in API charges or requires expensive, power-intensive GPUs for deployment, creating barriers for researchers, policymakers, and NGOs. Unfortunately, when geospatial Copilots are deployed with open language models (OLMs), performance often degrades due to their dependence on GPT-optimized logic. In this paper, we present Geo-OLM, a tool-augmented geospatial agent that leverages the novel paradigm of state-driven LLM reasoning to decouple task progression from tool calling. By alleviating the workflow reasoning burden, our approach enables low-resource OLMs to complete geospatial tasks more effectively. When downsizing to small models below 7B parameters, Geo-OLM outperforms the strongest prior geospatial baselines by 32.8% in successful query completion rates. Our method performs comparably to proprietary models achieving results within 10% of GPT-4o, while reducing inference costs by two orders of magnitude from \$500-\$1000 to under \$10. We present an in-depth analysis with geospatial downstream benchmarks, providing key insights to help practitioners effectively deploy OLMs for EO applications.
Ecomap: Sustainability-Driven Optimization of Multi-Tenant DNN Execution on Edge Servers
Mar 06, 2025



Edge computing systems struggle to efficiently manage multiple concurrent deep neural network (DNN) workloads while meeting strict latency requirements, minimizing power consumption, and maintaining environmental sustainability. This paper introduces Ecomap, a sustainability-driven framework that dynamically adjusts the maximum power threshold of edge devices based on real-time carbon intensity. Ecomap incorporates the innovative use of mixed-quality models, allowing it to dynamically replace computationally heavy DNNs with lighter alternatives when latency constraints are violated, ensuring service responsiveness with minimal accuracy loss. Additionally, it employs a transformer-based estimator to guide efficient workload mappings. Experimental results using NVIDIA Jetson AGX Xavier demonstrate that Ecomap reduces carbon emissions by an average of 30% and achieves a 25% lower carbon delay product (CDP) compared to state-of-the-art methods, while maintaining comparable or better latency and power efficiency.
Multi-Agent Geospatial Copilots for Remote Sensing Workflows
Jan 27, 2025



We present GeoLLM-Squad, a geospatial Copilot that introduces the novel multi-agent paradigm to remote sensing (RS) workflows. Unlike existing single-agent approaches that rely on monolithic large language models (LLM), GeoLLM-Squad separates agentic orchestration from geospatial task-solving, by delegating RS tasks to specialized sub-agents. Built on the open-source AutoGen and GeoLLM-Engine frameworks, our work enables the modular integration of diverse applications, spanning urban monitoring, forestry protection, climate analysis, and agriculture studies. Our results demonstrate that while single-agent systems struggle to scale with increasing RS task complexity, GeoLLM-Squad maintains robust performance, achieving a 17% improvement in agentic correctness over state-of-the-art baselines. Our findings highlight the potential of multi-agent AI in advancing RS workflows.
RankMap: Priority-Aware Multi-DNN Manager for Heterogeneous Embedded Devices
Nov 26, 2024



Modern edge data centers simultaneously handle multiple Deep Neural Networks (DNNs), leading to significant challenges in workload management. Thus, current management systems must leverage the architectural heterogeneity of new embedded systems to efficiently handle multi-DNN workloads. This paper introduces RankMap, a priority-aware manager specifically designed for multi-DNN tasks on heterogeneous embedded devices. RankMap addresses the extensive solution space of multi-DNN mapping through stochastic space exploration combined with a performance estimator. Experimental results show that RankMap achieves x3.6 higher average throughput compared to existing methods, while preventing DNN starvation under heavy workloads and improving the prioritization of specified DNNs by x57.5.
Less is More: Optimizing Function Calling for LLM Execution on Edge Devices
Nov 23, 2024The advanced function-calling capabilities of foundation models open up new possibilities for deploying agents to perform complex API tasks. However, managing large amounts of data and interacting with numerous APIs makes function calling hardware-intensive and costly, especially on edge devices. Current Large Language Models (LLMs) struggle with function calling at the edge because they cannot handle complex inputs or manage multiple tools effectively. This results in low task-completion accuracy, increased delays, and higher power consumption. In this work, we introduce Less-is-More, a novel fine-tuning-free function-calling scheme for dynamic tool selection. Our approach is based on the key insight that selectively reducing the number of tools available to LLMs significantly improves their function-calling performance, execution time, and power efficiency on edge devices. Experimental results with state-of-the-art LLMs on edge hardware show agentic success rate improvements, with execution time reduced by up to 70% and power consumption by up to 40%.
LLM-dCache: Improving Tool-Augmented LLMs with GPT-Driven Localized Data Caching
Jun 10, 2024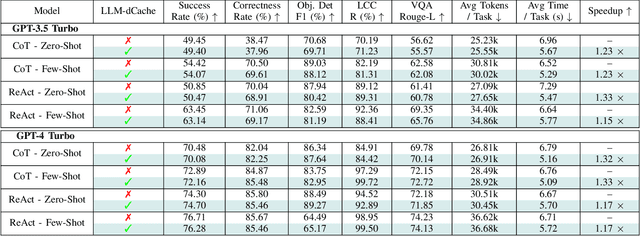


As Large Language Models (LLMs) broaden their capabilities to manage thousands of API calls, they are confronted with complex data operations across vast datasets with significant overhead to the underlying system. In this work, we introduce LLM-dCache to optimize data accesses by treating cache operations as callable API functions exposed to the tool-augmented agent. We grant LLMs the autonomy to manage cache decisions via prompting, seamlessly integrating with existing function-calling mechanisms. Tested on an industry-scale massively parallel platform that spans hundreds of GPT endpoints and terabytes of imagery, our method improves Copilot times by an average of 1.24x across various LLMs and prompting techniques.
Evaluating Zero-Shot GPT-4V Performance on 3D Visual Question Answering Benchmarks
May 29, 2024



As interest in "reformulating" the 3D Visual Question Answering (VQA) problem in the context of foundation models grows, it is imperative to assess how these new paradigms influence existing closed-vocabulary datasets. In this case study, we evaluate the zero-shot performance of foundational models (GPT-4 Vision and GPT-4) on well-established 3D VQA benchmarks, namely 3D-VQA and ScanQA. We provide an investigation to contextualize the performance of GPT-based agents relative to traditional modeling approaches. We find that GPT-based agents without any fine-tuning perform on par with the closed vocabulary approaches. Our findings corroborate recent results that "blind" models establish a surprisingly strong baseline in closed-vocabulary settings. We demonstrate that agents benefit significantly from scene-specific vocabulary via in-context textual grounding. By presenting a preliminary comparison with previous baselines, we hope to inform the community's ongoing efforts to refine multi-modal 3D benchmarks.
Unlearning Climate Misinformation in Large Language Models
May 29, 2024Misinformation regarding climate change is a key roadblock in addressing one of the most serious threats to humanity. This paper investigates factual accuracy in large language models (LLMs) regarding climate information. Using true/false labeled Q&A data for fine-tuning and evaluating LLMs on climate-related claims, we compare open-source models, assessing their ability to generate truthful responses to climate change questions. We investigate the detectability of models intentionally poisoned with false climate information, finding that such poisoning may not affect the accuracy of a model's responses in other domains. Furthermore, we compare the effectiveness of unlearning algorithms, fine-tuning, and Retrieval-Augmented Generation (RAG) for factually grounding LLMs on climate change topics. Our evaluation reveals that unlearning algorithms can be effective for nuanced conceptual claims, despite previous findings suggesting their inefficacy in privacy contexts. These insights aim to guide the development of more factually reliable LLMs and highlight the need for additional work to secure LLMs against misinformation attacks.