 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA: Enhancing Visual Conditioning via Track-Following Preference Optimization in Vision-Language-Action Models
Feb 04, 2026Vision-Language-Action (VLA) models have demonstrated strong performance across a wide range of robotic manipulation tasks. Despite the success, extending large pretrained Vision-Language Models (VLMs) to the action space can induce vision-action misalignment, where action predictions exhibit weak dependence on the current visual state, leading to unreliable action outputs. In this work, we study VLA models through the lens of visual conditioning and empirically show that successful rollouts consistently exhibit stronger visual dependence than failed ones. Motivated by this observation, we propose a training framework that explicitly strengthens visual conditioning in VLA models. Our approach first aligns action prediction with visual input via preference optimization on a track-following surrogate task, and then transfers the enhanced alignment to instruction-following task through latent-space distillation during supervised finetuning. Without introducing architectural modifications or additional data collection, our method improves both visual conditioning and task performance for discrete OpenVLA, and further yields consistent gains when extended to the continuous OpenVLA-OFT setting. Project website: https://vista-vla.github.io/ .
OS-Marathon: Benchmarking Computer-Use Agents on Long-Horizon Repetitive Tasks
Jan 28, 2026Long-horizon, repetitive workflows are common in professional settings, such as processing expense reports from receipts and entering student grades from exam papers. These tasks are often tedious for humans since they can extend to extreme lengths proportional to the size of the data to process. However, they are ideal for Computer-Use Agents (CUAs) due to their structured, recurring sub-workflows with logic that can be systematically learned. Identifying the absence of an evaluation benchmark as a primary bottleneck, we establish OS-Marathon, comprising 242 long-horizon, repetitive tasks across 2 domains to evaluate state-of-the-art (SOTA) agents. We then introduce a cost-effective method to construct a condensed demonstration using only few-shot examples to teach agents the underlying workflow logic, enabling them to execute similar workflows effectively on larger, unseen data collections. Extensive experiments demonstrate both the inherent challenges of these tasks and the effectiveness of our proposed method. Project website: https://os-marathon.github.io/.
A Schema-Guided Reason-while-Retrieve framework for Reasoning on Scene Graphs with Large-Language-Models (LLMs)
Feb 05, 2025



Scene graphs have emerged as a structured and serializable environment representation for grounded spatial reasoning with Large Language Models (LLMs). In this work, we propose SG-RwR, a Schema-Guided Retrieve-while-Reason framework for reasoning and planning with scene graphs. Our approach employs two cooperative, code-writing LLM agents: a (1) Reasoner for task planning and information queries generation, and a (2) Retriever for extracting corresponding graph information following the queries. Two agents collaborate iteratively, enabling sequential reasoning and adaptive attention to graph information. Unlike prior works, both agents are prompted only with the scene graph schema rather than the full graph data, which reduces the hallucination by limiting input tokens, and drives the Reasoner to generate reasoning trace abstractly.Following the trace, the Retriever programmatically query the scene graph data based on the schema understanding, allowing dynamic and global attention on the graph that enhances alignment between reasoning and retrieval. Through experiments in multiple simulation environments, we show that our framework surpasses existing LLM-based approaches in numerical Q\&A and planning tasks, and can benefit from task-level few-shot examples, even in the absence of agent-level demonstrations. Project code will be released.
Multi-Agent Geospatial Copilots for Remote Sensing Workflows
Jan 27, 2025



We present GeoLLM-Squad, a geospatial Copilot that introduces the novel multi-agent paradigm to remote sensing (RS) workflows. Unlike existing single-agent approaches that rely on monolithic large language models (LLM), GeoLLM-Squad separates agentic orchestration from geospatial task-solving, by delegating RS tasks to specialized sub-agents. Built on the open-source AutoGen and GeoLLM-Engine frameworks, our work enables the modular integration of diverse applications, spanning urban monitoring, forestry protection, climate analysis, and agriculture studies. Our results demonstrate that while single-agent systems struggle to scale with increasing RS task complexity, GeoLLM-Squad maintains robust performance, achieving a 17% improvement in agentic correctness over state-of-the-art baselines. Our findings highlight the potential of multi-agent AI in advancing RS workflows.
GASP: Gaussian Avatars with Synthetic Priors
Dec 10, 2024



Gaussian Splatting has changed the game for real-time photo-realistic rendering. One of the most popular applications of Gaussian Splatting is to create animatable avatars, known as Gaussian Avatars. Recent works have pushed the boundaries of quality and rendering efficiency but suffer from two main limitations. Either they require expensive multi-camera rigs to produce avatars with free-view rendering, or they can be trained with a single camera but only rendered at high quality from this fixed viewpoint. An ideal model would be trained using a short monocular video or image from available hardware, such as a webcam, and rendered from any view. To this end, we propose GASP: Gaussian Avatars with Synthetic Priors. To overcome the limitations of existing datasets, we exploit the pixel-perfect nature of synthetic data to train a Gaussian Avatar prior. By fitting this prior model to a single photo or video and fine-tuning it, we get a high-quality Gaussian Avatar, which supports 360$^\circ$ rendering. Our prior is only required for fitting, not inference, enabling real-time application. Through our method, we obtain high-quality, animatable Avatars from limited data which can be animated and rendered at 70fps on commercial hardware. See our project page (https://microsoft.github.io/GASP/) for results.
Online Learning via Memory: Retrieval-Augmented Detector Adaptation
Sep 16, 2024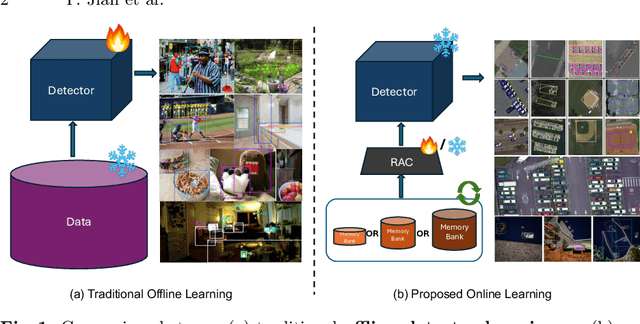
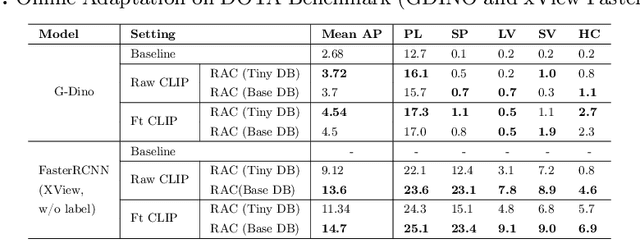
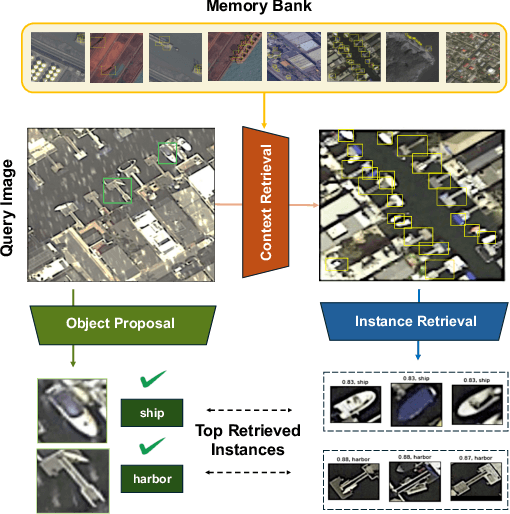
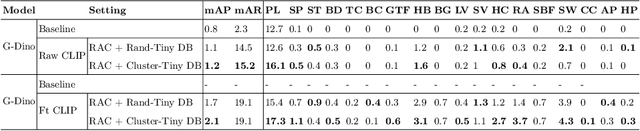
This paper presents a novel way of online adapting any off-the-shelf object detection model to a novel domain without retraining the detector model. Inspired by how humans quickly learn knowledge of a new subject (e.g., memorization), we allow the detector to look up similar object concepts from memory during test time. This is achieved through a retrieval augmented classification (RAC) module together with a memory bank that can be flexibly updated with new domain knowledge. We experimented with various off-the-shelf open-set detector and close-set detectors. With only a tiny memory bank (e.g., 10 images per category) and being training-free, our online learning method could significantly outperform baselines in adapting a detector to novel domains.
LLM-dCache: Improving Tool-Augmented LLMs with GPT-Driven Localized Data Caching
Jun 10, 2024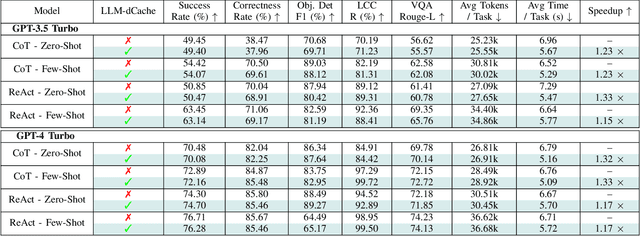


As Large Language Models (LLMs) broaden their capabilities to manage thousands of API calls, they are confronted with complex data operations across vast datasets with significant overhead to the underlying system. In this work, we introduce LLM-dCache to optimize data accesses by treating cache operations as callable API functions exposed to the tool-augmented agent. We grant LLMs the autonomy to manage cache decisions via prompting, seamlessly integrating with existing function-calling mechanisms. Tested on an industry-scale massively parallel platform that spans hundreds of GPT endpoints and terabytes of imagery, our method improves Copilot times by an average of 1.24x across various LLMs and prompting techniques.
Stable Diffusion For Aerial Object Detection
Nov 21, 2023



Aerial object detection is a challenging task, in which one major obstacle lies in the limitations of large-scale data collection and the long-tail distribution of certain classes. Synthetic data offers a promising solution, especially with recent advances in diffusion-based methods like stable diffusion (SD). However, the direct application of diffusion methods to aerial domains poses unique challenges: stable diffusion's optimization for rich ground-level semantics doesn't align with the sparse nature of aerial objects, and the extraction of post-synthesis object coordinates remains problematic. To address these challenges, we introduce a synthetic data augmentation framework tailored for aerial images. It encompasses sparse-to-dense region of interest (ROI) extraction to bridge the semantic gap, fine-tuning the diffusion model with low-rank adaptation (LORA) to circumvent exhaustive retraining, and finally, a Copy-Paste method to compose synthesized objects with backgrounds, providing a nuanced approach to aerial object detection through synthetic data.