 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learning via Memory: Retrieval-Augmented Detector Adaptation
Sep 16, 2024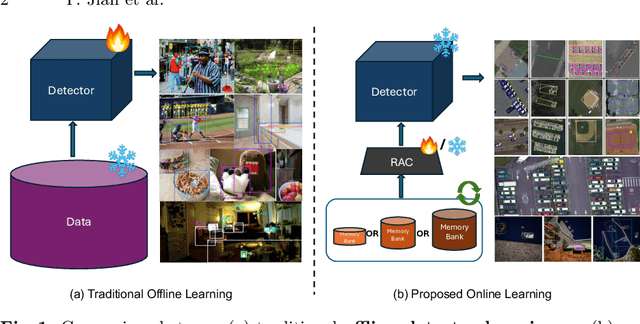
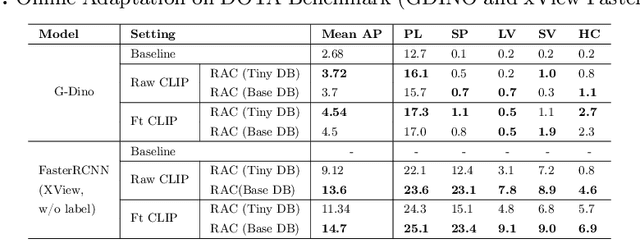
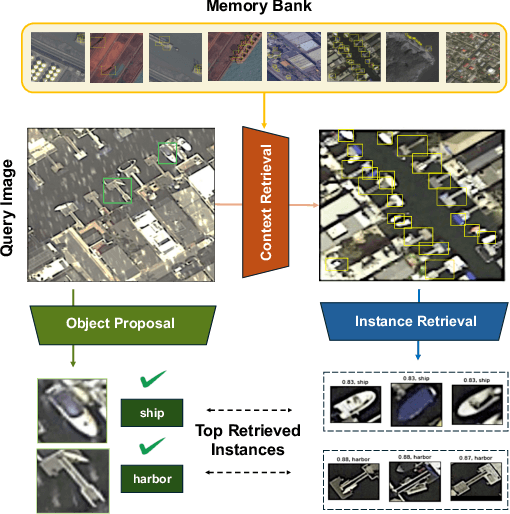
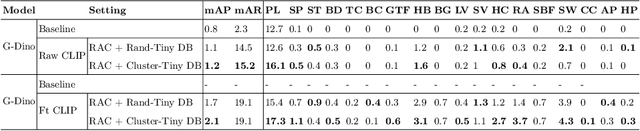
This paper presents a novel way of online adapting any off-the-shelf object detection model to a novel domain without retraining the detector model. Inspired by how humans quickly learn knowledge of a new subject (e.g., memorization), we allow the detector to look up similar object concepts from memory during test time. This is achieved through a retrieval augmented classification (RAC) module together with a memory bank that can be flexibly updated with new domain knowledge. We experimented with various off-the-shelf open-set detector and close-set detectors. With only a tiny memory bank (e.g., 10 images per category) and being training-free, our online learning method could significantly outperform baselines in adapting a detector to novel domains.
GEMEL: Model Merging for Memory-Efficient, Real-Time Video Analytics at the Edge
Jan 19, 2022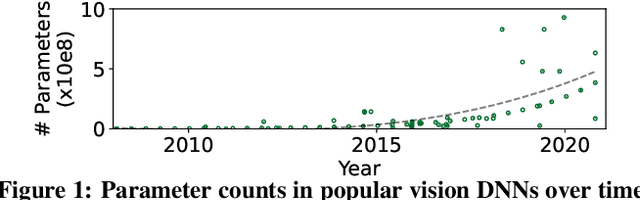
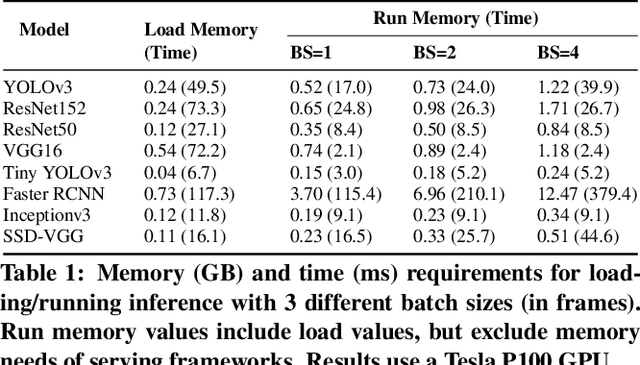
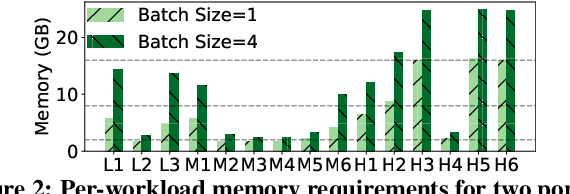

Video analytics pipelines have steadily shifted to edge deployments to reduce bandwidth overheads and privacy violations, but in doing so, face an ever-growing resource tension. Most notably, edge-box GPUs lack the memory needed to concurrently house the growing number of (increasingly complex) models for real-time inference. Unfortunately, existing solutions that rely on time/space sharing of GPU resources are insufficient as the required swapping delays result in unacceptable frame drops and accuracy violations. We present model merging, a new memory management technique that exploits architectural similarities between edge vision models by judiciously sharing their layers (including weights) to reduce workload memory costs and swapping delays. Our system, GEMEL, efficiently integrates merging into existing pipelines by (1) leveraging several guiding observations about per-model memory usage and inter-layer dependencies to quickly identify fruitful and accuracy-preserving merging configurations, and (2) altering edge inference schedules to maximize merging benefits. Experiments across diverse workloads reveal that GEMEL reduces memory usage by up to 60.7%, and improves overall accuracy by 8-39% relative to time/space sharing alone.
Ekya: Continuous Learning of Video Analytics Models on Edge Compute Servers
Dec 19, 2020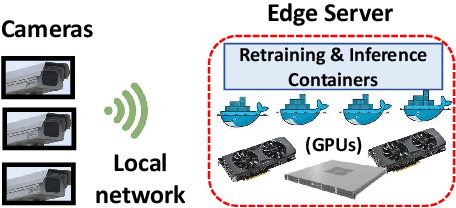
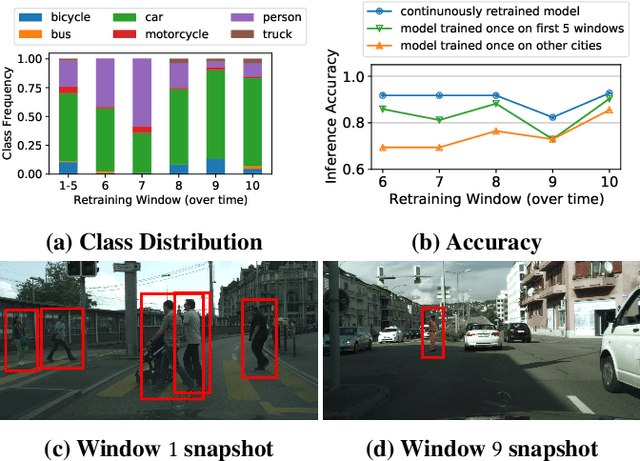

Video analytics applications use edge compute servers for the analytics of the videos (for bandwidth and privacy). Compressed models that are deployed on the edge servers for inference suffer from data drift, where the live video data diverges from the training data. Continuous learning handles data drift by periodically retraining the models on new data. Our work addresses the challenge of jointly supporting inference and retraining tasks on edge servers, which requires navigating the fundamental tradeoff between the retrained model's accuracy and the inference accuracy. Our solution Ekya balances this tradeoff across multiple models and uses a micro-profiler to identify the models that will benefit the most by retraining. Ekya's accuracy gain compared to a baseline scheduler is 29% higher, and the baseline requires 4x more GPU resources to achieve the same accuracy as Ekya.
HyperSTAR: Task-Aware Hyperparameters for Deep Networks
May 21, 2020
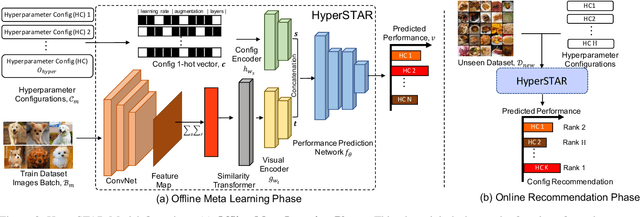

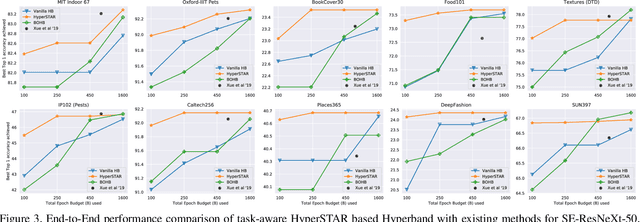
While deep neural networks excel in solving visual recognition tasks, they require significant effort to find hyperparameters that make them work optimally. Hyperparameter Optimization (HPO) approaches have automated the process of finding good hyperparameters but they do not adapt to a given task (task-agnostic), making them computationally inefficient. To reduce HPO time, we present HyperSTAR (System for Task Aware Hyperparameter Recommendation), a task-aware method to warm-start HPO for deep neural networks. HyperSTAR ranks and recommends hyperparameters by predicting their performance conditioned on a joint dataset-hyperparameter space. It learns a dataset (task) representation along with the performance predictor directly from raw images in an end-to-end fashion. The recommendations, when integrated with an existing HPO method, make it task-aware and significantly reduce the time to achieve optimal performance. We conduct extensive experiments on 10 publicly available large-scale image classification datasets over two different network architectures, validating that HyperSTAR evaluates 50% less configurations to achieve the best performance compared to existing methods. We further demonstrate that HyperSTAR makes Hyperband (HB) task-aware, achieving the optimal accuracy in just 25% of the budget required by both vanilla HB and Bayesian Optimized HB~(BOHB).
Unsupervised Domain Adaptation for Object Detection via Cross-Domain Semi-Supervised Learning
Nov 24, 2019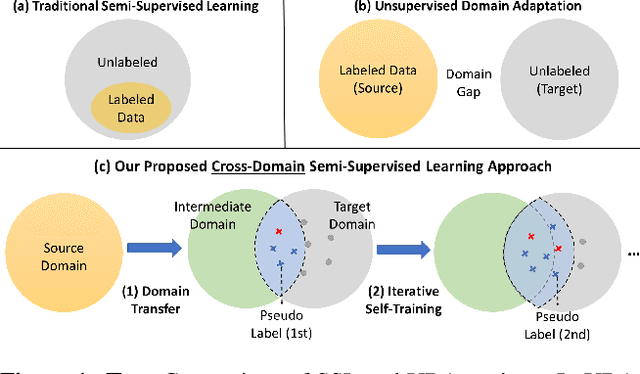
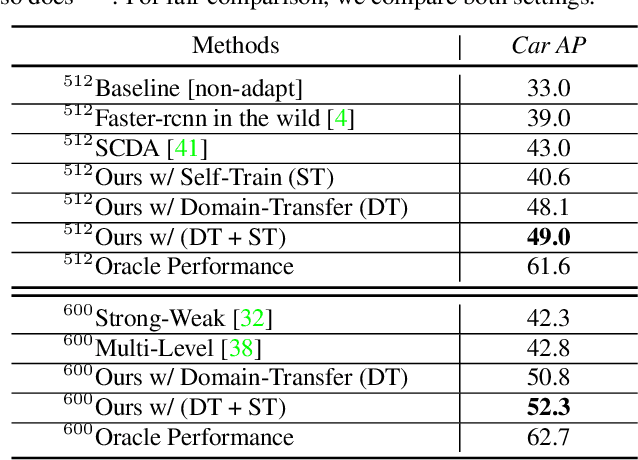
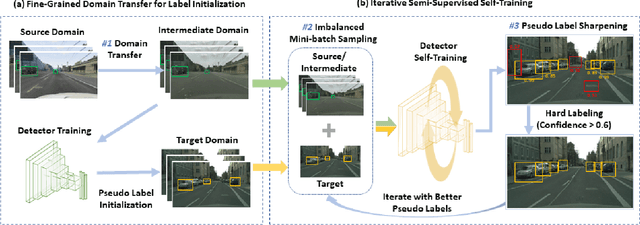
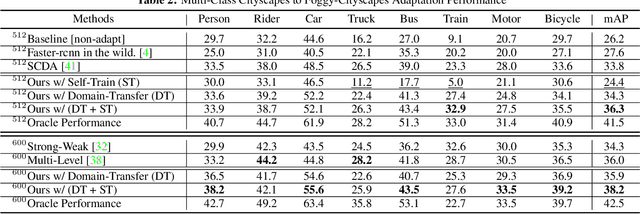
Current state-of-the-art object detectors can have significant performance drop when deployed in the wild due to domain gaps with training data. Unsupervised Domain Adaptation (UDA) is a promising approach to adapt models for new domains/environments without any expensive label cost. However, without ground truth labels, most prior works on UDA for object detection tasks can only perform coarse image-level and/or feature-level adaptation by using adversarial learning methods. In this work, we show that such adversarial-based methods can only reduce the domain style gap, but cannot address the domain content distribution gap that is shown to be important for object detectors. To overcome this limitation, we propose the Cross-Domain Semi-Supervised Learning (CDSSL) framework by leveraging high-quality pseudo labels to learn better representations from the target domain directly. To enable SSL for cross-domain object detection, we propose fine-grained domain transfer, progressive-confidence-based label sharpening and imbalanced sampling strategy to address two challenges: (i) non-identical distribution between source and target domain data, (ii) error amplification/accumulation due to noisy pseudo labeling on the target domain. Experiment results show that our proposed approach consistently achieves new state-of-the-art performance (2.2% - 9.5% better than prior best work on mAP) under various domain gap scenarios. The code will be released.
Person Depth ReID: Robust Person Re-identification with Commodity Depth Sensors
May 28, 2017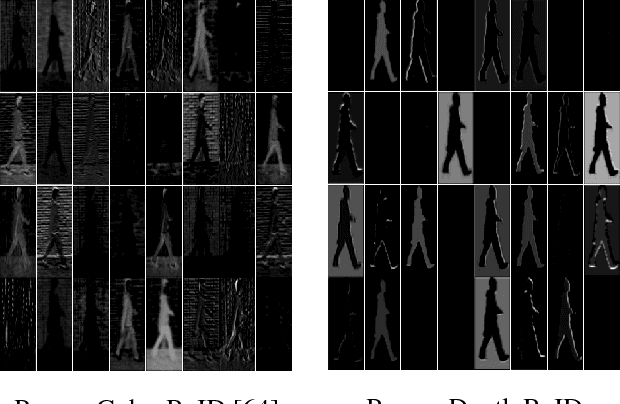
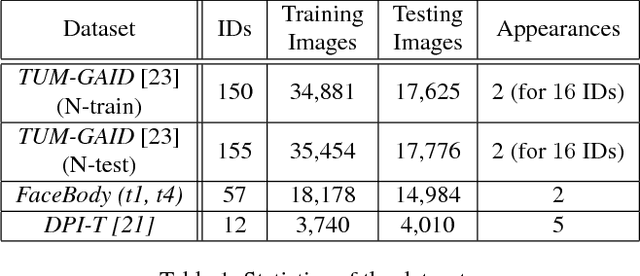

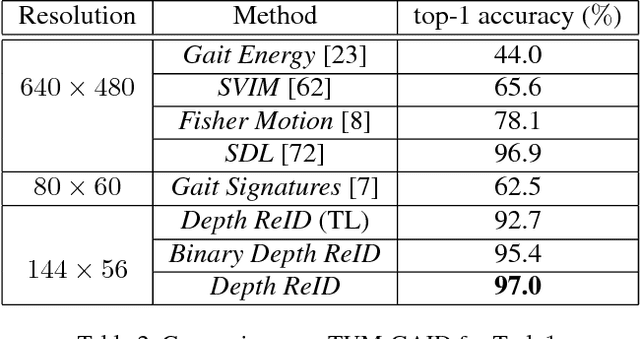
This work targets person re-identification (ReID) from depth sensors such as Kinect. Since depth is invariant to illumination and less sensitive than color to day-by-day appearance changes, a natural question is whether depth is an effective modality for Person ReID, especially in scenarios where individuals wear different colored clothes or over a period of several months. We explore the use of recurrent Deep Neural Networks for learning high-level shape information from low-resolution depth images. In order to tackle the small sample size problem, we introduce regularization and a hard temporal attention unit. The whole model can be trained end to end with a hybrid supervised loss. We carry out a thorough experimental evaluation of the proposed method on three person re-identification datasets, which include side views, views from the top and sequences with varying degree of partial occlusion, pose and viewpoint variations. To that end, we introduce a new dataset with RGB-D and skeleton data. In a scenario where subjects are recorded after three months with new clothes, we demonstrate large performance gains attained using Depth ReID compared to a state-of-the-art Color ReID. Finally, we show further improvements using the temporal attention unit in multi-shot setting.
An Empirical Evaluation of Current Convolutional Architectures' Ability to Manage Nuisance Location and Scale Variability
Apr 28, 2016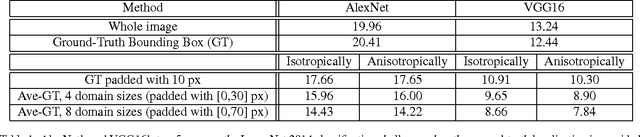
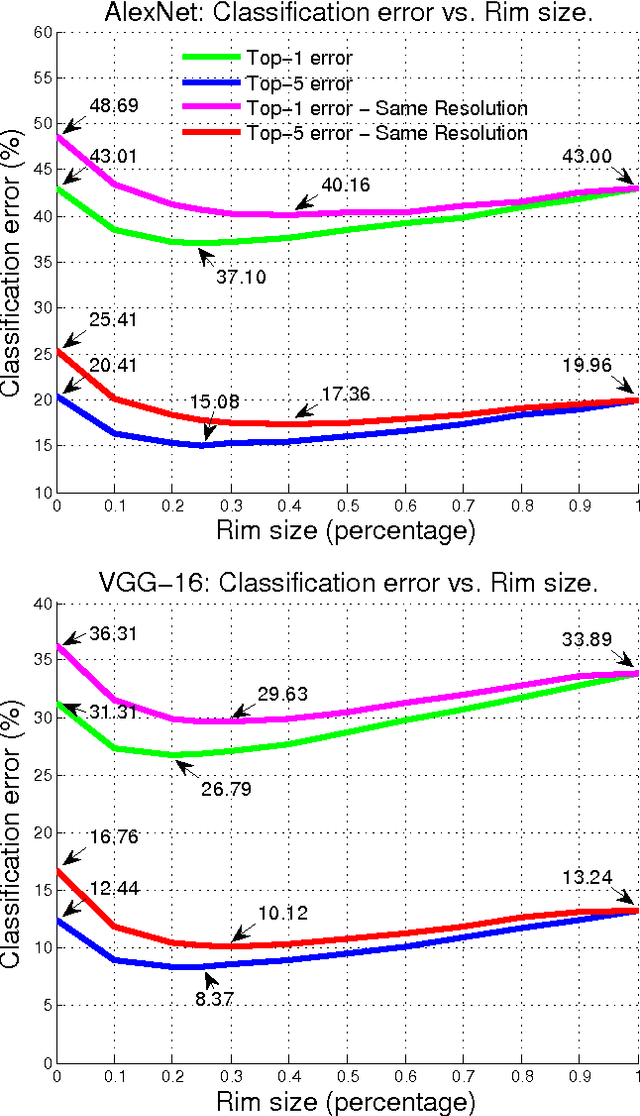
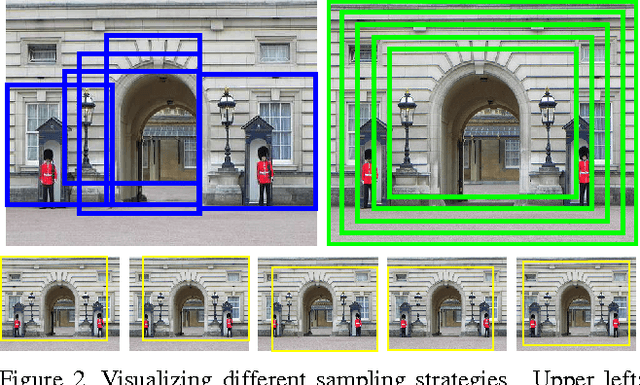
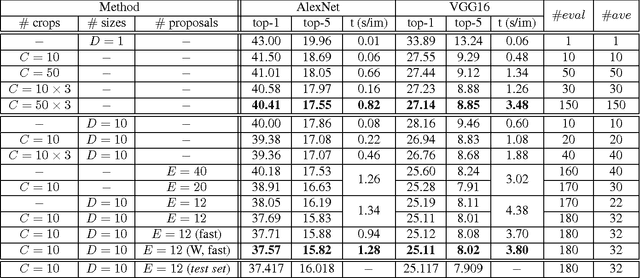
We conduct an empirical study to test the ability of Convolutional Neural Networks (CNNs) to reduce the effects of nuisance transformations of the input data, such as location, scale and aspect ratio. We isolate factors by adopting a common convolutional architecture either deployed globally on the image to compute class posterior distributions, or restricted locally to compute class conditional distributions given location, scale and aspect ratios of bounding boxes determined by proposal heuristics. In theory, averaging the latter should yield inferior performance compared to proper marginalization. Yet empirical evidence suggests the converse, leading us to conclude that - at the current level of complexity of convolutional architectures and scale of the data sets used to train them - CNNs are not very effective at marginalizing nuisance variability. We also quantify the effects of context on the overall classification task and its impact on the performance of CNNs, and propose improved sampling techniques for heuristic proposal schemes that improve end-to-end performance to state-of-the-art levels. We test our hypothesis on a classification task using the ImageNet Challenge benchmark and on a wide-baseline matching task using the Oxford and Fischer's datasets.
Visual Scene Representations: Contrast, Scaling and Occlusion
Apr 17, 2015

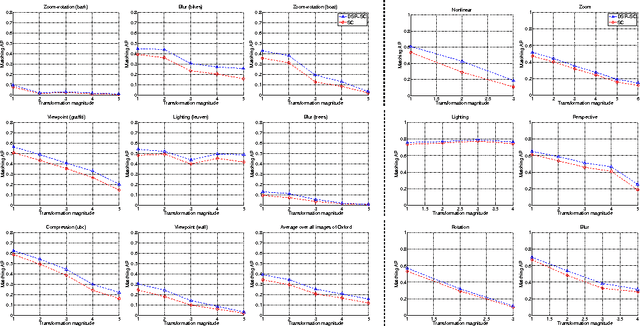

We study the structure of representations, defined as approximations of minimal sufficient statistics that are maximal invariants to nuisance factors, for visual data subject to scaling and occlusion of line-of-sight. We derive analytical expressions for such representations and show that, under certain restrictive assumptions, they are related to features commonly in use in the computer vision community. This link highlights the condition tacitly assumed by these descriptors, and also suggests ways to improve and generalize them. This new interpretation draws connections to the classical theories of sampling, hypothesis testing and group invariance.
Boosting Convolutional Features for Robust Object Proposals
Mar 21, 2015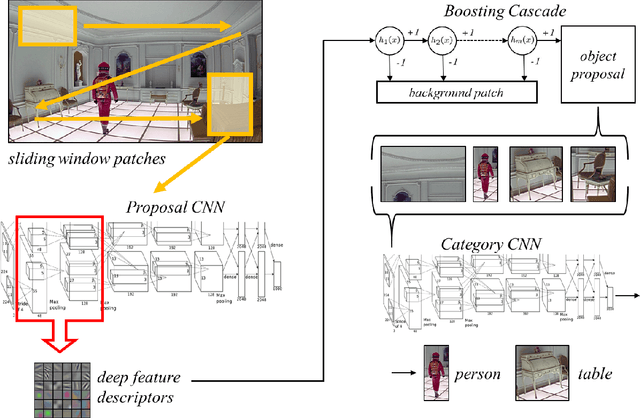
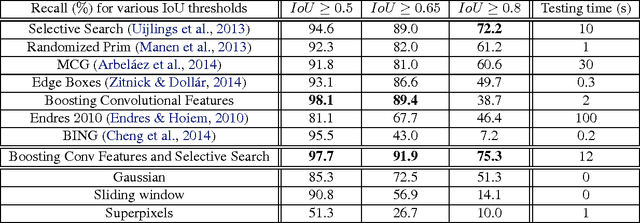


Deep Convolutional Neural Networks (CNNs) have demonstrated excellent performance in image classification, but still show room for improvement in object-detection tasks with many categories, in particular for cluttered scenes and occlusion. Modern detection algorithms like Regions with CNNs (Girshick et al., 2014) rely on Selective Search (Uijlings et al., 2013) to propose regions which with high probability represent objects, where in turn CNNs are deployed for classification. Selective Search represents a family of sophisticated algorithms that are engineered with multiple segmentation, appearance and saliency cues, typically coming with a significant run-time overhead. Furthermore, (Hosang et al., 2014) have shown that most methods suffer from low reproducibility due to unstable superpixels, even for slight image perturbations. Although CNNs are subsequently used for classification in top-performing object-detection pipelines, current proposal methods are agnostic to how these models parse objects and their rich learned representations. As a result they may propose regions which may not resemble high-level objects or totally miss some of them. To overcome these drawbacks we propose a boosting approach which directly takes advantage of hierarchical CNN features for detecting regions of interest fast. We demonstrate its performance on ImageNet 2013 detection benchmark and compare it with state-of-the-art methods.