 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Network Management Using Code Generated by Large Language Models
Aug 11, 2023Analyzing network topologies and communication graphs plays a crucial role in contemporary network management. However, the absence of a cohesive approach leads to a challenging learning curve, heightened errors, and inefficiencies. In this paper, we introduce a novel approach to facilitate a natural-language-based network management experience, utilizing large language models (LLMs) to generate task-specific code from natural language queries. This method tackles the challenges of explainability, scalability, and privacy by allowing network operators to inspect the generated code, eliminating the need to share network data with LLMs, and concentrating on application-specific requests combined with general program synthesis techniques. We design and evaluate a prototype system using benchmark applications, showcasing high accuracy, cost-effectiveness, and the potential for further enhancements using complementary program synthesis techniques.
Federated Learning under Distributed Concept Drift
Jun 01, 2022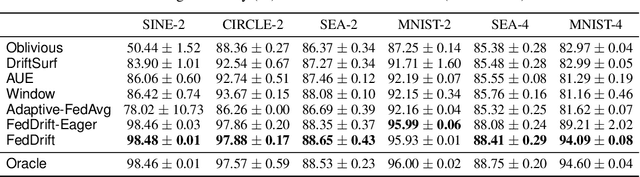


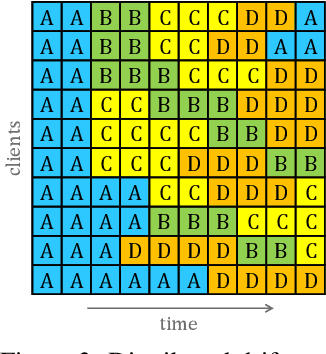
Federated Learning (FL) under distributed concept drift is a largely unexplored area. Although concept drift is itself a well-studied phenomenon, it poses particular challenges for FL, because drifts arise staggered in time and space (across clients). Our work is the first to explicitly study data heterogeneity in both dimensions. We first demonstrate that prior solutions to drift adaptation, with their single global model, are ill-suited to staggered drifts, necessitating multi-model solutions. We identify the problem of drift adaptation as a time-varying clustering problem, and we propose two new clustering algorithms for reacting to drifts based on local drift detection and hierarchical clustering. Empirical evaluation shows that our solutions achieve significantly higher accuracy than existing baselines, and are comparable to an idealized algorithm with oracle knowledge of the ground-truth clustering of clients to concepts at each time step.
FedSpace: An Efficient Federated Learning Framework at Satellites and Ground Stations
Feb 02, 2022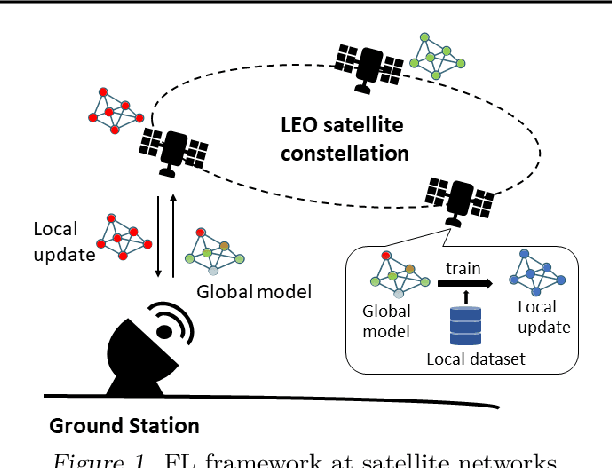

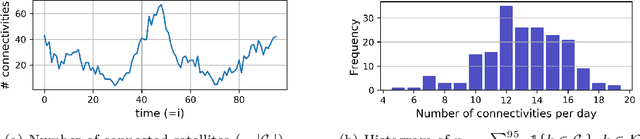

Large-scale deployments of low Earth orbit (LEO) satellites collect massive amount of Earth imageries and sensor data, which can empower machine learning (ML) to address global challenges such as real-time disaster navigation and mitigation. However, it is often infeasible to download all the high-resolution images and train these ML models on the ground because of limited downlink bandwidth, sparse connectivity, and regularization constraints on the imagery resolution. To address these challenges, we leverage Federated Learning (FL), where ground stations and satellites collaboratively train a global ML model without sharing the captured images on the satellites. We show fundamental challenges in applying existing FL algorithms among satellites and ground stations, and we formulate an optimization problem which captures a unique trade-off between staleness and idleness. We propose a novel FL framework, named FedSpace, which dynamically schedules model aggregation based on the deterministic and time-varying connectivity according to satellite orbits. Extensive numerical evaluations based on real-world satellite images and satellite networks show that FedSpace reduces the training time by 1.7 days (38.6%) over the state-of-the-art FL algorithms.
Interpret-able feedback for AutoML systems
Feb 22, 2021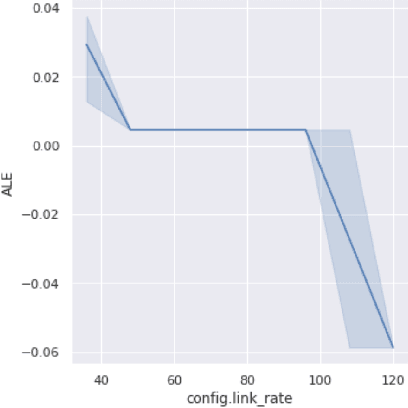


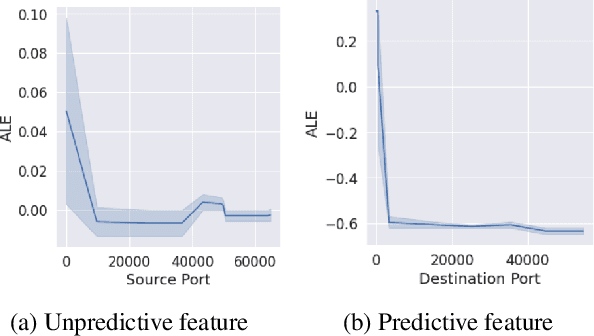
Automated machine learning (AutoML) systems aim to enable training machine learning (ML) models for non-ML experts. A shortcoming of these systems is that when they fail to produce a model with high accuracy, the user has no path to improve the model other than hiring a data scientist or learning ML -- this defeats the purpose of AutoML and limits its adoption. We introduce an interpretable data feedback solution for AutoML. Our solution suggests new data points for the user to label (without requiring a pool of unlabeled data) to improve the model's accuracy. Our solution analyzes how features influence the prediction among all ML models in an AutoML ensemble, and we suggest more data samples from feature ranges that have high variance in such analysis. Our evaluation shows that our solution can improve the accuracy of AutoML by 7-8% and significantly outperforms popular active learning solutions in data efficiency, all the while providing the added benefit of being interpretable.
Ekya: Continuous Learning of Video Analytics Models on Edge Compute Servers
Dec 19, 2020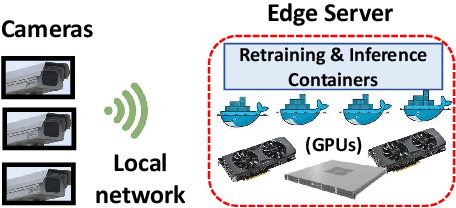
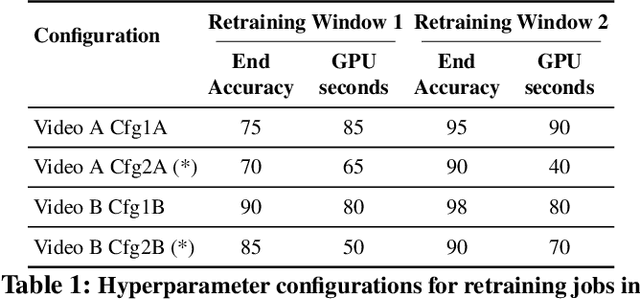
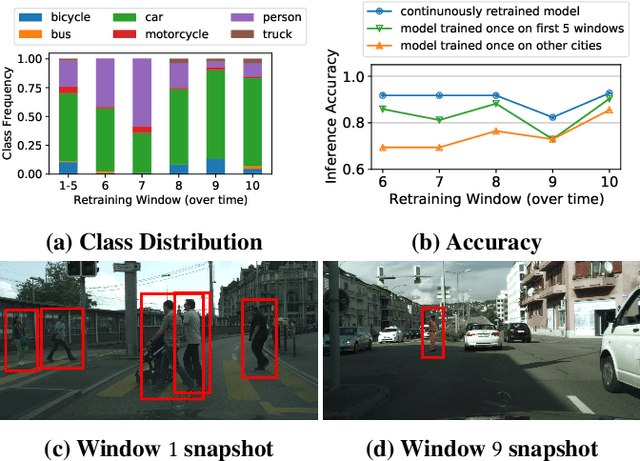

Video analytics applications use edge compute servers for the analytics of the videos (for bandwidth and privacy). Compressed models that are deployed on the edge servers for inference suffer from data drift, where the live video data diverges from the training data. Continuous learning handles data drift by periodically retraining the models on new data. Our work addresses the challenge of jointly supporting inference and retraining tasks on edge servers, which requires navigating the fundamental tradeoff between the retrained model's accuracy and the inference accuracy. Our solution Ekya balances this tradeoff across multiple models and uses a micro-profiler to identify the models that will benefit the most by retraining. Ekya's accuracy gain compared to a baseline scheduler is 29% higher, and the baseline requires 4x more GPU resources to achieve the same accuracy as Ekya.
Machine Learning Systems for Highly-Distributed and Rapidly-Growing Data
Oct 18, 2019


The usability and practicality of any machine learning (ML) applications are largely influenced by two critical but hard-to-attain factors: low latency and low cost. Unfortunately, achieving low latency and low cost is very challenging when ML depends on real-world data that are highly distributed and rapidly growing (e.g., data collected by mobile phones and video cameras all over the world). Such real-world data pose many challenges in communication and computation. For example, when training data are distributed across data centers that span multiple continents, communication among data centers can easily overwhelm the limited wide-area network bandwidth, leading to prohibitively high latency and high cost. In this dissertation, we demonstrate that the latency and cost of ML on highly-distributed and rapidly-growing data can be improved by one to two orders of magnitude by designing ML systems that exploit the characteristics of ML algorithms, ML model structures, and ML training/serving data. We support this thesis statement with three contributions. First, we design a system that provides both low-latency and low-cost ML serving (inferencing) over large-scale and continuously-growing datasets, such as videos. Second, we build a system that makes ML training over geo-distributed datasets as fast as training within a single data center. Third, we present a first detailed study and a system-level solution on a fundamental and largely overlooked problem: ML training over non-IID (i.e., not independent and identically distributed) data partitions (e.g., facial images collected by cameras varies according to the demographics of each camera's location).
The Non-IID Data Quagmire of Decentralized Machine Learning
Oct 01, 2019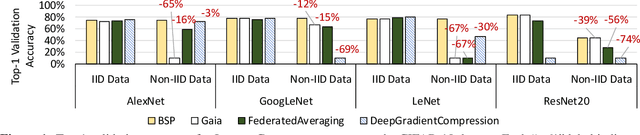
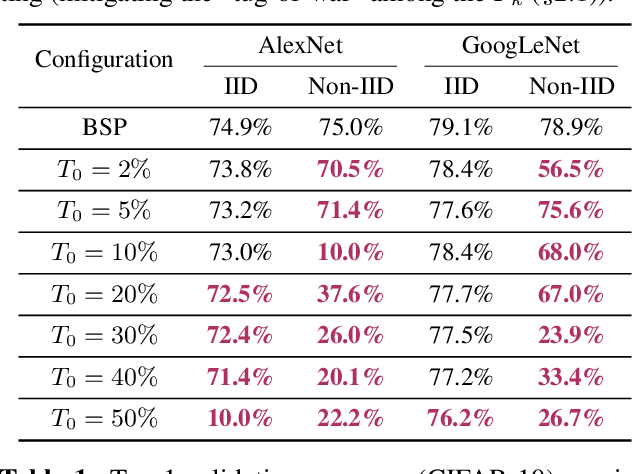
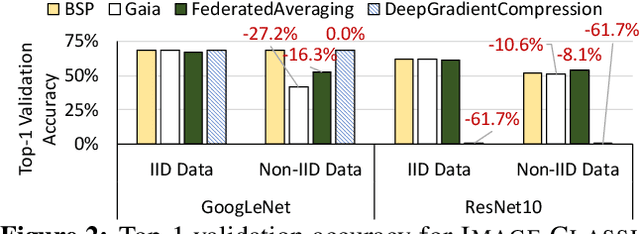

Many large-scale machine learning (ML) applications need to train ML models over decentralized datasets that are generated at different devices and locations. These decentralized datasets pose a fundamental challenge to ML because they are typically generated in very different contexts, which leads to significant differences in data distribution across devices/locations (i.e., they are not independent and identically distributed (IID)). In this work, we take a step toward better understanding this challenge, by presenting the first detailed experimental study of the impact of such non-IID data on the decentralized training of deep neural networks (DNNs). Our study shows that: (i) the problem of non-IID data partitions is fundamental and pervasive, as it exists in all ML applications, DNN models, training datasets, and decentralized learning algorithms in our study; (ii) this problem is particularly difficult for DNN models with batch normalization layers; and (iii) the degree of deviation from IID (the skewness) is a key determinant of the difficulty level of the problem. With these findings in mind, we present SkewScout, a system-level approach that adapts the communication frequency of decentralized learning algorithms to the (skew-induced) accuracy loss between data partitions. We also show that group normalization can recover much of the skew-induced accuracy loss of batch normalization.
Focus: Querying Large Video Datasets with Low Latency and Low Cost
Jan 10, 2018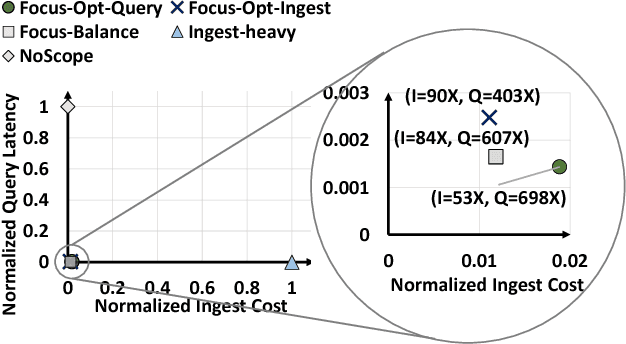
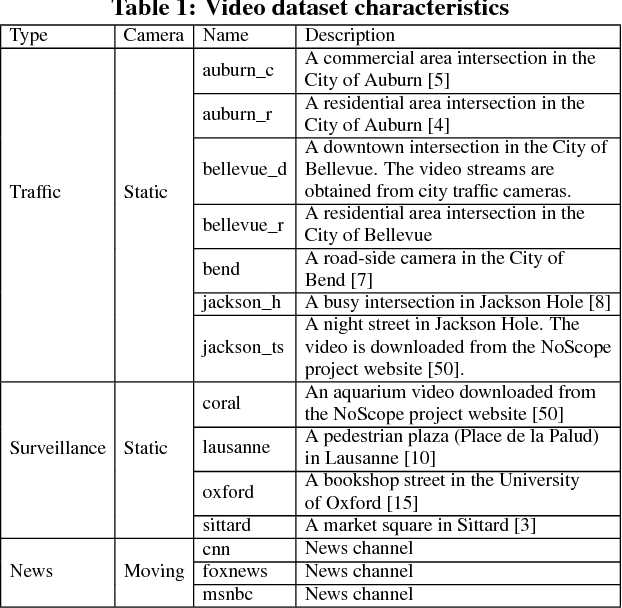
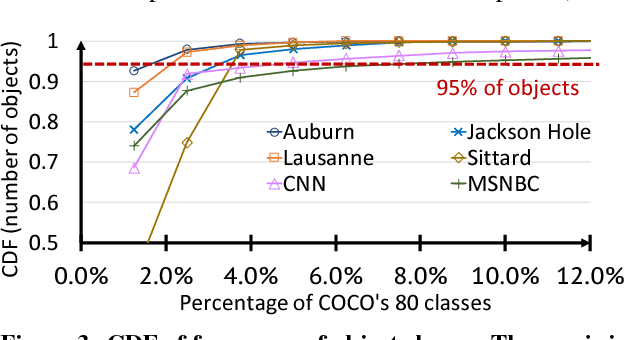
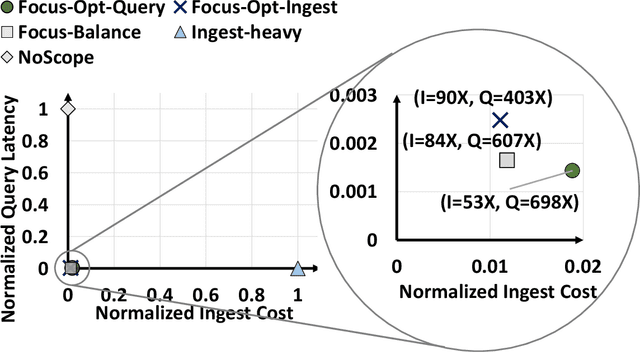
Large volumes of videos are continuously recorded from cameras deployed for traffic control and surveillance with the goal of answering "after the fact" queries: identify video frames with objects of certain classes (cars, bags) from many days of recorded video. While advancements in convolutional neural networks (CNNs) have enabled answering such queries with high accuracy, they are too expensive and slow. We build Focus, a system for low-latency and low-cost querying on large video datasets. Focus uses cheap ingestion techniques to index the videos by the objects occurring in them. At ingest-time, it uses compression and video-specific specialization of CNNs. Focus handles the lower accuracy of the cheap CNNs by judiciously leveraging expensive CNNs at query-time. To reduce query time latency, we cluster similar objects and hence avoid redundant processing. Using experiments on video streams from traffic, surveillance and news channels, we see that Focus uses 58X fewer GPU cycles than running expensive ingest processors and is 37X faster than processing all the video at query time.
D-SLATS: Distributed Simultaneous Localization and Time Synchronization
Nov 10, 2017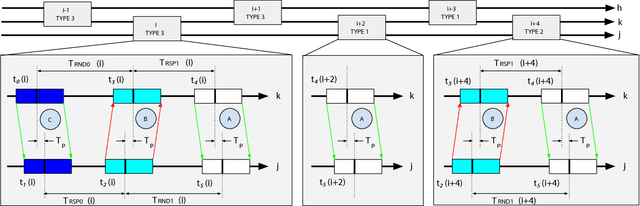

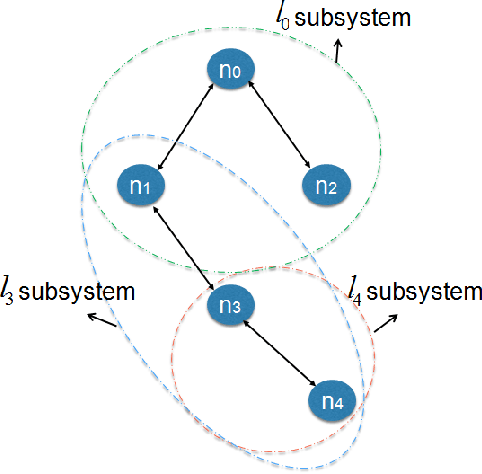

Through the last decade, we have witnessed a surge of Internet of Things (IoT) devices, and with that a greater need to choreograph their actions across both time and space. Although these two problems, namely time synchronization and localization, share many aspects in common, they are traditionally treated separately or combined on centralized approaches that results in an ineffcient use of resources, or in solutions that are not scalable in terms of the number of IoT devices. Therefore, we propose D-SLATS, a framework comprised of three different and independent algorithms to jointly solve time synchronization and localization problems in a distributed fashion. The First two algorithms are based mainly on the distributed Extended Kalman Filter (EKF) whereas the third one uses optimization techniques. No fusion center is required, and the devices only communicate with their neighbors. The proposed methods are evaluated on custom Ultra-Wideband communication Testbed and a quadrotor, representing a network of both static and mobile nodes. Our algorithms achieve up to three microseconds time synchronization accuracy and 30 cm localization error.