 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSibylSense: Adaptive Rubric Learning via Memory Tuning and Adversarial Probing
Feb 24, 2026Designing aligned and robust rewards for open-ended generation remains a key barrier to RL post-training. Rubrics provide structured, interpretable supervision, but scaling rubric construction is difficult: expert rubrics are costly, prompted rubrics are often superficial or inconsistent, and fixed-pool discriminative rubrics can saturate and drift, enabling reward hacking. We present SibylSense, an inference-time learning approach that adapts a frozen rubric generator through a tunable memory bank of validated rubric items. Memory is updated via verifier-based item rewards measured by reference-candidate answer discriminative gaps from a handful of examples. SibylSense alternates memory tuning with a rubric-adversarial policy update that produces rubric-satisfying candidate answers, shrinking discriminative gaps and driving the rubric generator to capture new quality dimensions. Experiments on two open-ended tasks show that SibylSense yields more discriminative rubrics and improves downstream RL performance over static and non-adaptive baselines.
Enterprise AI Must Enforce Participant-Aware Access Control
Sep 18, 2025Large language models (LLMs) are increasingly deployed in enterprise settings where they interact with multiple users and are trained or fine-tuned on sensitive internal data. While fine-tuning enhances performance by internalizing domain knowledge, it also introduces a critical security risk: leakage of confidential training data to unauthorized users. These risks are exacerbated when LLMs are combined with Retrieval-Augmented Generation (RAG) pipelines that dynamically fetch contextual documents at inference time. We demonstrate data exfiltration attacks on AI assistants where adversaries can exploit current fine-tuning and RAG architectures to leak sensitive information by leveraging the lack of access control enforcement. We show that existing defenses, including prompt sanitization, output filtering, system isolation, and training-level privacy mechanisms, are fundamentally probabilistic and fail to offer robust protection against such attacks. We take the position that only a deterministic and rigorous enforcement of fine-grained access control during both fine-tuning and RAG-based inference can reliably prevent the leakage of sensitive data to unauthorized recipients. We introduce a framework centered on the principle that any content used in training, retrieval, or generation by an LLM is explicitly authorized for \emph{all users involved in the interaction}. Our approach offers a simple yet powerful paradigm shift for building secure multi-user LLM systems that are grounded in classical access control but adapted to the unique challenges of modern AI workflows. Our solution has been deployed in Microsoft Copilot Tuning, a product offering that enables organizations to fine-tune models using their own enterprise-specific data.
Direct Reasoning Optimization: LLMs Can Reward And Refine Their Own Reasoning for Open-Ended Tasks
Jun 16, 2025Recent advances in Large Language Models (LLMs) have showcased impressive reasoning abilities in structured tasks like mathematics and programming, largely driven by Reinforcement Learning with Verifiable Rewards (RLVR), which uses outcome-based signals that are scalable, effective, and robust against reward hacking. However, applying similar techniques to open-ended long-form reasoning tasks remains challenging due to the absence of generic, verifiable reward signals. To address this, we propose Direct Reasoning Optimization (DRO), a reinforcement learning framework for fine-tuning LLMs on open-ended, particularly long-form, reasoning tasks, guided by a new reward signal: the Reasoning Reflection Reward (R3). At its core, R3 selectively identifies and emphasizes key tokens in the reference outcome that reflect the influence of the model's preceding chain-of-thought reasoning, thereby capturing the consistency between reasoning and reference outcome at a fine-grained level. Crucially, R3 is computed internally using the same model being optimized, enabling a fully self-contained training setup. Additionally, we introduce a dynamic data filtering strategy based on R3 for open-ended reasoning tasks, reducing cost while improving downstream performance. We evaluate DRO on two diverse datasets -- ParaRev, a long-form paragraph revision task, and FinQA, a math-oriented QA benchmark -- and show that it consistently outperforms strong baselines while remaining broadly applicable across both open-ended and structured domains.
TerraTrace: Temporal Signature Land Use Mapping System
Feb 25, 2025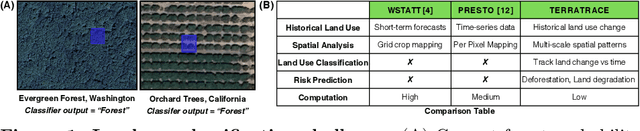
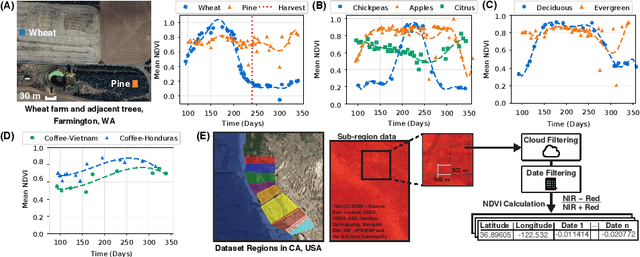
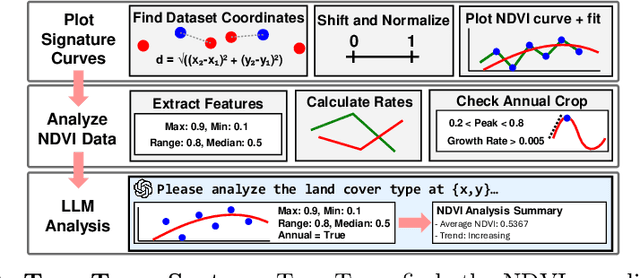

Understanding land use over time is critical to tracking events related to climate change, like deforestation. However, satellite-based remote sensing tools which are used for monitoring struggle to differentiate vegetation types in farms and orchards from forests. We observe that metrics such as the Normalized Difference Vegetation Index (NDVI), based on plant photosynthesis, have unique temporal signatures that reflect agricultural practices and seasonal cycles. We analyze yearly NDVI changes on 20 farms for 10 unique crops. Initial results show that NDVI curves are coherent with agricultural practices, are unique to each crop, consistent globally, and can differentiate farms from forests. We develop a novel longitudinal NDVI dataset for the state of California from 2020-2023 with 500~m resolution and over 70 million points. We use this to develop the TerraTrace platform, an end-to-end analytic tool that classifies land use using NDVI signatures and allows users to query the system through an LLM chatbot and graphical interface.
RLTHF: Targeted Human Feedback for LLM Alignment
Feb 19, 2025



Fine-tuning large language models (LLMs) to align with user preferences is challenging due to the high cost of quality human annotations in Reinforcement Learning from Human Feedback (RLHF) and the generalizability limitations of AI Feedback. To address these challenges, we propose RLTHF, a human-AI hybrid framework that combines LLM-based initial alignment with selective human annotations to achieve full-human annotation alignment with minimal effort. RLTHF identifies hard-to-annotate samples mislabeled by LLMs using a reward model's reward distribution and iteratively enhances alignment by integrating strategic human corrections while leveraging LLM's correctly labeled samples. Evaluations on HH-RLHF and TL;DR datasets show that RLTHF reaches full-human annotation-level alignment with only 6-7% of the human annotation effort. Furthermore, models trained on RLTHF's curated datasets for downstream tasks outperform those trained on fully human-annotated datasets, underscoring the effectiveness of RLTHF's strategic data curation.
Enabling Adoption of Regenerative Agriculture through Soil Carbon Copilots
Nov 25, 2024



Mitigating climate change requires transforming agriculture to minimize environ mental impact and build climate resilience. Regenerative agricultural practices enhance soil organic carbon (SOC) levels, thus improving soil health and sequestering carbon. A challenge to increasing regenerative agriculture practices is cheaply measuring SOC over time and understanding how SOC is affected by regenerative agricultural practices and other environmental factors and farm management practices. To address this challenge, we introduce an AI-driven Soil Organic Carbon Copilot that automates the ingestion of complex multi-resolution, multi-modal data to provide large-scale insights into soil health and regenerative practices. Our data includes extreme weather event data (e.g., drought and wildfire incidents), farm management data (e.g., cropland information and tillage predictions), and SOC predictions. We find that integrating public data and specialized models enables large-scale, localized analysis for sustainable agriculture. In comparisons of agricultural practices across California counties, we find evidence that diverse agricultural activity may mitigate the negative effects of tillage; and that while extreme weather conditions heavily affect SOC, composting may mitigate SOC loss. Finally, implementing role-specific personas empowers agronomists, farm consultants, policymakers, and other stakeholders to implement evidence-based strategies that promote sustainable agriculture and build climate resilience.
Wireless Spectrum in Rural Farmlands: Status, Challenges and Opportunities
Jul 05, 2024



Due to factors such as low population density and expansive geographical distances, network deployment falls behind in rural regions, leading to a broadband divide. Wireless spectrum serves as the blood and flesh of wireless communications. Shared white spaces such as those in the TVWS and CBRS spectrum bands offer opportunities to expand connectivity, innovate, and provide affordable access to high-speed Internet in under-served areas without additional cost to expensive licensed spectrum. However, the current methods to utilize these white spaces are inefficient due to very conservative models and spectrum policies, causing under-utilization of valuable spectrum resources. This hampers the full potential of innovative wireless technologies that could benefit farmers, small Internet Service Providers (ISPs) or Mobile Network Operators (MNOs) operating in rural regions. This study explores the challenges faced by farmers and service providers when using shared spectrum bands to deploy their networks while ensuring maximum system performance and minimizing interference with other users. Additionally, we discuss how spatiotemporal spectrum models, in conjunction with database-driven spectrum-sharing solutions, can enhance the allocation and management of spectrum resources, ultimately improving the efficiency and reliability of wireless networks operating in shared spectrum bands.
Injecting New Knowledge into Large Language Models via Supervised Fine-Tuning
Apr 02, 2024

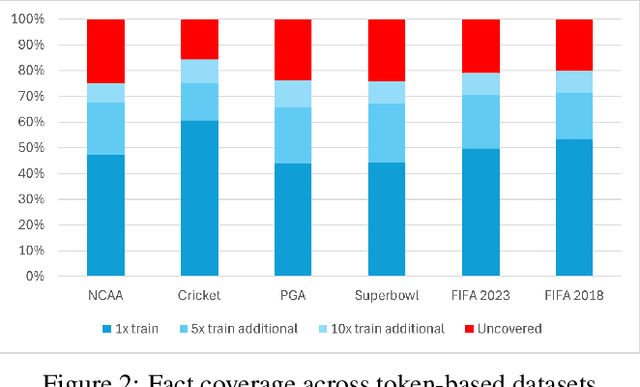

In recent years, Large Language Models (LLMs) have shown remarkable performance in generating human-like text, proving to be a valuable asset across various applications. However, adapting these models to incorporate new, out-of-domain knowledge remains a challenge, particularly for facts and events that occur after the model's knowledge cutoff date. This paper investigates the effectiveness of Supervised Fine-Tuning (SFT) as a method for knowledge injection in LLMs, specifically focusing on the domain of recent sporting events. We compare different dataset generation strategies -- token-based and fact-based scaling -- to create training data that helps the model learn new information. Our experiments on GPT-4 demonstrate that while token-based scaling can lead to improvements in Q&A accuracy, it may not provide uniform coverage of new knowledge. Fact-based scaling, on the other hand, offers a more systematic approach to ensure even coverage across all facts. We present a novel dataset generation process that leads to more effective knowledge ingestion through SFT, and our results show considerable performance improvements in Q&A tasks related to out-of-domain knowledge. This study contributes to the understanding of domain adaptation for LLMs and highlights the potential of SFT in enhancing the factuality of LLM responses in specific knowledge domains.
Long-Range Backscatter Connectivity via Spaceborne Synthetic Aperture Radar
Feb 15, 2024



SarComms is a new communication method that enables passive satellite backscatter connectivity using existing spaceborne synthetic aperture radar (SAR) signals. We demonstrate that SAR signals from the European Space Agency's Sentinel-1 satellite, used for imaging the Earth, can also be leveraged to enable ground-to-satellite connectivity. This paper presents the first cooperative, on-the-ground target that modulates SAR backscatter to send information bits and analyzes how to extract it from publicly available Sentinel-1 datasets. To demonstrate the system's feasibility, we evaluate the effectiveness of corner reflectors in the field, develop a deployment algorithm to optimize reflector placement and prototype modulating corner reflectors (both mechanically and electrically controlled) to change the amplitude of backscattered SAR signals.
RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture
Jan 30, 2024There are two common ways in which developers are incorporating proprietary and domain-specific data when building applications of Large Language Models (LLMs): Retrieval-Augmented Generation (RAG) and Fine-Tuning. RAG augments the prompt with the external data, while fine-Tuning incorporates the additional knowledge into the model itself. However, the pros and cons of both approaches are not well understood. In this paper, we propose a pipeline for fine-tuning and RAG, and present the tradeoffs of both for multiple popular LLMs, including Llama2-13B, GPT-3.5, and GPT-4. Our pipeline consists of multiple stages, including extracting information from PDFs, generating questions and answers, using them for fine-tuning, and leveraging GPT-4 for evaluating the results. We propose metrics to assess the performance of different stages of the RAG and fine-Tuning pipeline. We conduct an in-depth study on an agricultural dataset. Agriculture as an industry has not seen much penetration of AI, and we study a potentially disruptive application - what if we could provide location-specific insights to a farmer? Our results show the effectiveness of our dataset generation pipeline in capturing geographic-specific knowledge, and the quantitative and qualitative benefits of RAG and fine-tuning. We see an accuracy increase of over 6 p.p. when fine-tuning the model and this is cumulative with RAG, which increases accuracy by 5 p.p. further. In one particular experiment, we also demonstrate that the fine-tuned model leverages information from across geographies to answer specific questions, increasing answer similarity from 47% to 72%. Overall, the results point to how systems built using LLMs can be adapted to respond and incorporate knowledge across a dimension that is critical for a specific industry, paving the way for further applications of LLMs in other industrial domains.