 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrafting Interpretable Embeddings by Asking LLMs Questions
May 26, 2024Large language models (LLMs) have rapidly improved text embeddings for a growing array of natural-language processing tasks. However, their opaqueness and proliferation into scientific domains such as neuroscience have created a growing need for interpretability. Here, we ask whether we can obtain interpretable embeddings through LLM prompting. We introduce question-answering embeddings (QA-Emb), embeddings where each feature represents an answer to a yes/no question asked to an LLM. Training QA-Emb reduces to selecting a set of underlying questions rather than learning model weights. We use QA-Emb to flexibly generate interpretable models for predicting fMRI voxel responses to language stimuli. QA-Emb significantly outperforms an established interpretable baseline, and does so while requiring very few questions. This paves the way towards building flexible feature spaces that can concretize and evaluate our understanding of semantic brain representations. We additionally find that QA-Emb can be effectively approximated with an efficient model, and we explore broader applications in simple NLP tasks.
RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture
Jan 30, 2024There are two common ways in which developers are incorporating proprietary and domain-specific data when building applications of Large Language Models (LLMs): Retrieval-Augmented Generation (RAG) and Fine-Tuning. RAG augments the prompt with the external data, while fine-Tuning incorporates the additional knowledge into the model itself. However, the pros and cons of both approaches are not well understood. In this paper, we propose a pipeline for fine-tuning and RAG, and present the tradeoffs of both for multiple popular LLMs, including Llama2-13B, GPT-3.5, and GPT-4. Our pipeline consists of multiple stages, including extracting information from PDFs, generating questions and answers, using them for fine-tuning, and leveraging GPT-4 for evaluating the results. We propose metrics to assess the performance of different stages of the RAG and fine-Tuning pipeline. We conduct an in-depth study on an agricultural dataset. Agriculture as an industry has not seen much penetration of AI, and we study a potentially disruptive application - what if we could provide location-specific insights to a farmer? Our results show the effectiveness of our dataset generation pipeline in capturing geographic-specific knowledge, and the quantitative and qualitative benefits of RAG and fine-tuning. We see an accuracy increase of over 6 p.p. when fine-tuning the model and this is cumulative with RAG, which increases accuracy by 5 p.p. further. In one particular experiment, we also demonstrate that the fine-tuned model leverages information from across geographies to answer specific questions, increasing answer similarity from 47% to 72%. Overall, the results point to how systems built using LLMs can be adapted to respond and incorporate knowledge across a dimension that is critical for a specific industry, paving the way for further applications of LLMs in other industrial domains.
NumS: Scalable Array Programming for the Cloud
Jun 28, 2022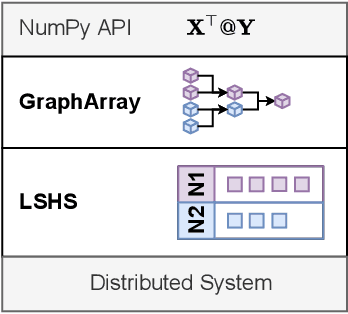

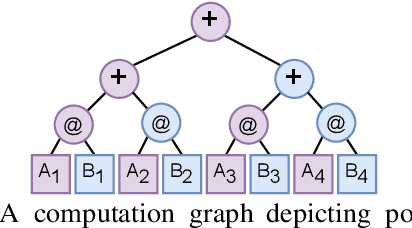
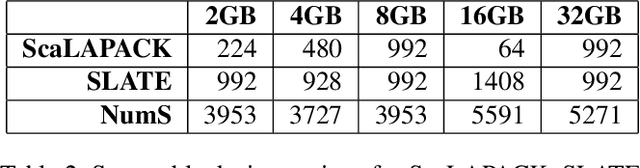
Scientists increasingly rely on Python tools to perform scalable distributed memory array operations using rich, NumPy-like expressions. However, many of these tools rely on dynamic schedulers optimized for abstract task graphs, which often encounter memory and network bandwidth-related bottlenecks due to sub-optimal data and operator placement decisions. Tools built on the message passing interface (MPI), such as ScaLAPACK and SLATE, have better scaling properties, but these solutions require specialized knowledge to use. In this work, we present NumS, an array programming library which optimizes NumPy-like expressions on task-based distributed systems. This is achieved through a novel scheduler called Load Simulated Hierarchical Scheduling (LSHS). LSHS is a local search method which optimizes operator placement by minimizing maximum memory and network load on any given node within a distributed system. Coupled with a heuristic for load balanced data layouts, our approach is capable of attaining communication lower bounds on some common numerical operations, and our empirical study shows that LSHS enhances performance on Ray by decreasing network load by a factor of 2x, requiring 4x less memory, and reducing execution time by 10x on the logistic regression problem. On terabyte-scale data, NumS achieves competitive performance to SLATE on DGEMM, up to 20x speedup over Dask on a key operation for tensor factorization, and a 2x speedup on logistic regression compared to Dask ML and Spark's MLlib.