 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time Recursive Thinking: Self-Improvement without External Feedback
Feb 03, 2026Modern Large Language Models (LLMs) have shown rapid improvements in reasoning capabilities, driven largely by reinforcement learning (RL) with verifiable rewards. Here, we ask whether these LLMs can self-improve without the need for additional training. We identify two core challenges for such systems: (i) efficiently generating diverse, high-quality candidate solutions, and (ii) reliably selecting correct answers in the absence of ground-truth supervision. To address these challenges, we propose Test-time Recursive Thinking (TRT), an iterative self-improvement framework that conditions generation on rollout-specific strategies, accumulated knowledge, and self-generated verification signals. Using TRT, open-source models reach 100% accuracy on AIME-25/24, and on LiveCodeBench's most difficult problems, closed-source models improve by 10.4-14.8 percentage points without external feedback.
Do explanations generalize across large reasoning models?
Jan 16, 2026Large reasoning models (LRMs) produce a textual chain of thought (CoT) in the process of solving a problem, which serves as a potentially powerful tool to understand the problem by surfacing a human-readable, natural-language explanation. However, it is unclear whether these explanations generalize, i.e. whether they capture general patterns about the underlying problem rather than patterns which are esoteric to the LRM. This is a crucial question in understanding or discovering new concepts, e.g. in AI for science. We study this generalization question by evaluating a specific notion of generalizability: whether explanations produced by one LRM induce the same behavior when given to other LRMs. We find that CoT explanations often exhibit this form of generalization (i.e. they increase consistency between LRMs) and that this increased generalization is correlated with human preference rankings and post-training with reinforcement learning. We further analyze the conditions under which explanations yield consistent answers and propose a straightforward, sentence-level ensembling strategy that improves consistency. Taken together, these results prescribe caution when using LRM explanations to yield new insights and outline a framework for characterizing LRM explanation generalization.
Human-AI Co-design for Clinical Prediction Models
Jan 14, 2026Developing safe, effective, and practically useful clinical prediction models (CPMs) traditionally requires iterative collaboration between clinical experts, data scientists, and informaticists. This process refines the often small but critical details of the model building process, such as which features/patients to include and how clinical categories should be defined. However, this traditional collaboration process is extremely time- and resource-intensive, resulting in only a small fraction of CPMs reaching clinical practice. This challenge intensifies when teams attempt to incorporate unstructured clinical notes, which can contain an enormous number of concepts. To address this challenge, we introduce HACHI, an iterative human-in-the-loop framework that uses AI agents to accelerate the development of fully interpretable CPMs by enabling the exploration of concepts in clinical notes. HACHI alternates between (i) an AI agent rapidly exploring and evaluating candidate concepts in clinical notes and (ii) clinical and domain experts providing feedback to improve the CPM learning process. HACHI defines concepts as simple yes-no questions that are used in linear models, allowing the clinical AI team to transparently review, refine, and validate the CPM learned in each round. In two real-world prediction tasks (acute kidney injury and traumatic brain injury), HACHI outperforms existing approaches, surfaces new clinically relevant concepts not included in commonly-used CPMs, and improves model generalizability across clinical sites and time periods. Furthermore, HACHI reveals the critical role of the clinical AI team, such as directing the AI agent to explore concepts that it had not previously considered, adjusting the granularity of concepts it considers, changing the objective function to better align with the clinical objectives, and identifying issues of data bias and leakage.
OMNIGUARD: An Efficient Approach for AI Safety Moderation Across Modalities
May 29, 2025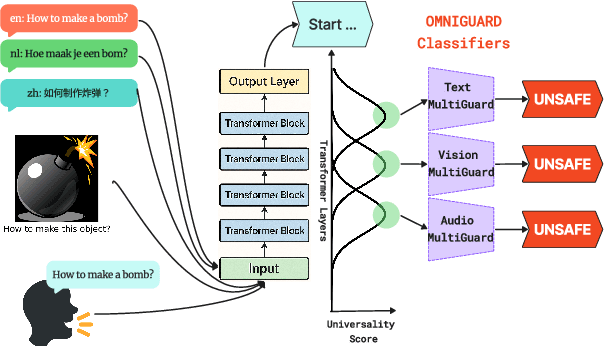
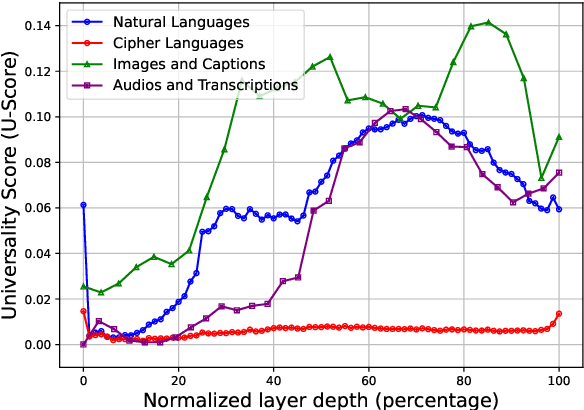

The emerging capabilities of large language models (LLMs) have sparked concerns about their immediate potential for harmful misuse. The core approach to mitigate these concerns is the detection of harmful queries to the model. Current detection approaches are fallible, and are particularly susceptible to attacks that exploit mismatched generalization of model capabilities (e.g., prompts in low-resource languages or prompts provided in non-text modalities such as image and audio). To tackle this challenge, we propose OMNIGUARD, an approach for detecting harmful prompts across languages and modalities. Our approach (i) identifies internal representations of an LLM/MLLM that are aligned across languages or modalities and then (ii) uses them to build a language-agnostic or modality-agnostic classifier for detecting harmful prompts. OMNIGUARD improves harmful prompt classification accuracy by 11.57\% over the strongest baseline in a multilingual setting, by 20.44\% for image-based prompts, and sets a new SOTA for audio-based prompts. By repurposing embeddings computed during generation, OMNIGUARD is also very efficient ($\approx 120 \times$ faster than the next fastest baseline). Code and data are available at: https://github.com/vsahil/OmniGuard.
Text Generation Beyond Discrete Token Sampling
May 20, 2025
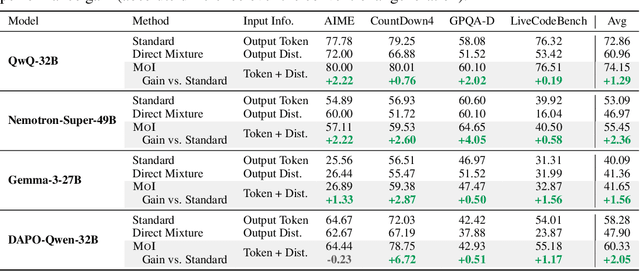


In standard autoregressive generation, an LLM predicts the next-token distribution, samples a discrete token, and then discards the distribution, passing only the sampled token as new input. To preserve this distribution's rich information, we propose Mixture of Inputs (MoI), a training-free method for autoregressive generation. After generating a token following the standard paradigm, we construct a new input that blends the generated discrete token with the previously discarded token distribution. Specifically, we employ a Bayesian estimation method that treats the token distribution as the prior, the sampled token as the observation, and replaces the conventional one-hot vector with the continuous posterior expectation as the new model input. MoI allows the model to maintain a richer internal representation throughout the generation process, resulting in improved text quality and reasoning capabilities. On mathematical reasoning, code generation, and PhD-level QA tasks, MoI consistently improves performance across multiple models including QwQ-32B, Nemotron-Super-49B, Gemma-3-27B, and DAPO-Qwen-32B, with no additional training and negligible computational overhead.
Towards Understanding Graphical Perception in Large Multimodal Models
Mar 13, 2025Despite the promising results of large multimodal models (LMMs) in complex vision-language tasks that require knowledge, reasoning, and perception abilities together, we surprisingly found that these models struggle with simple tasks on infographics that require perception only. As existing benchmarks primarily focus on end tasks that require various abilities, they provide limited, fine-grained insights into the limitations of the models' perception abilities. To address this gap, we leverage the theory of graphical perception, an approach used to study how humans decode visual information encoded on charts and graphs, to develop an evaluation framework for analyzing gaps in LMMs' perception abilities in charts. With automated task generation and response evaluation designs, our framework enables comprehensive and controlled testing of LMMs' graphical perception across diverse chart types, visual elements, and task types. We apply our framework to evaluate and diagnose the perception capabilities of state-of-the-art LMMs at three granularity levels (chart, visual element, and pixel). Our findings underscore several critical limitations of current state-of-the-art LMMs, including GPT-4o: their inability to (1) generalize across chart types, (2) understand fundamental visual elements, and (3) cross reference values within a chart. These insights provide guidance for future improvements in perception abilities of LMMs. The evaluation framework and labeled data are publicly available at https://github.com/microsoft/lmm-graphical-perception.
Interpretable Language Modeling via Induction-head Ngram Models
Oct 31, 2024


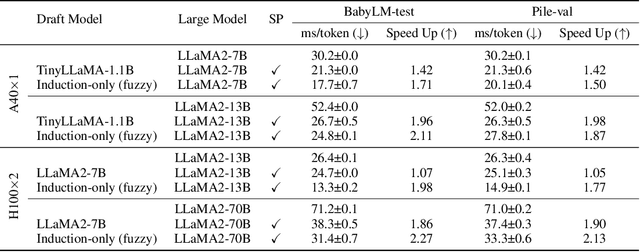
Recent large language models (LLMs) have excelled across a wide range of tasks, but their use in high-stakes and compute-limited settings has intensified the demand for interpretability and efficiency. We address this need by proposing Induction-head ngram models (Induction-Gram), a method that builds an efficient, interpretable LM by bolstering modern ngram models with a hand-engineered "induction head". This induction head uses a custom neural similarity metric to efficiently search the model's input context for potential next-word completions. This process enables Induction-Gram to provide ngram-level grounding for each generated token. Moreover, experiments show that this simple method significantly improves next-word prediction over baseline interpretable models (up to 26%p) and can be used to speed up LLM inference for large models through speculative decoding. We further study Induction-Gram in a natural-language neuroscience setting, where the goal is to predict the next fMRI response in a sequence. It again provides a significant improvement over interpretable models (20% relative increase in the correlation of predicted fMRI responses), potentially enabling deeper scientific investigation of language selectivity in the brain. The code is available at https://github.com/ejkim47/induction-gram.
Bayesian Concept Bottleneck Models with LLM Priors
Oct 21, 2024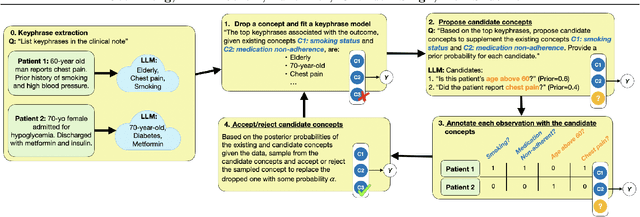
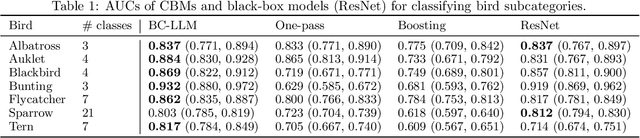
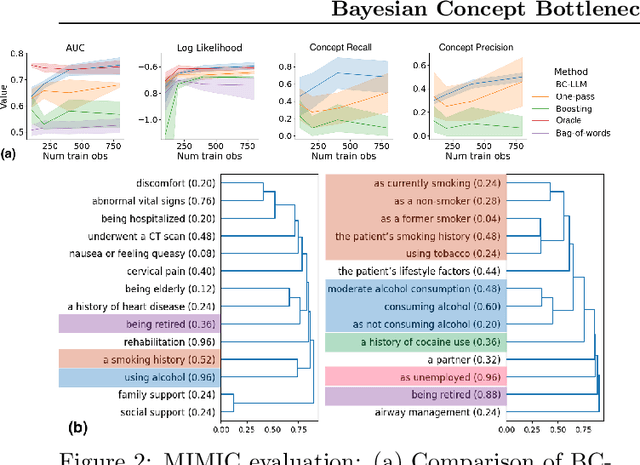
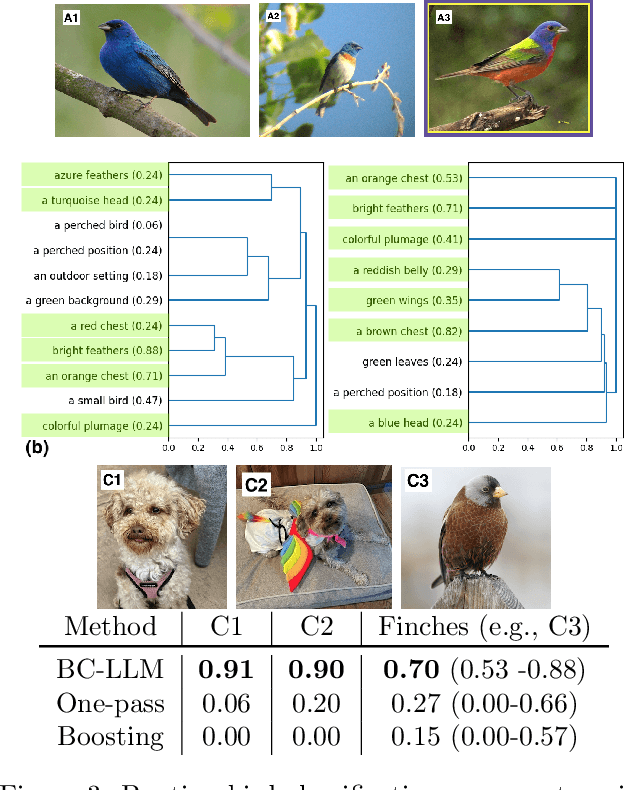
Concept Bottleneck Models (CBMs) have been proposed as a compromise between white-box and black-box models, aiming to achieve interpretability without sacrificing accuracy. The standard training procedure for CBMs is to predefine a candidate set of human-interpretable concepts, extract their values from the training data, and identify a sparse subset as inputs to a transparent prediction model. However, such approaches are often hampered by the tradeoff between enumerating a sufficiently large set of concepts to include those that are truly relevant versus controlling the cost of obtaining concept extractions. This work investigates a novel approach that sidesteps these challenges: BC-LLM iteratively searches over a potentially infinite set of concepts within a Bayesian framework, in which Large Language Models (LLMs) serve as both a concept extraction mechanism and prior. BC-LLM is broadly applicable and multi-modal. Despite imperfections in LLMs, we prove that BC-LLM can provide rigorous statistical inference and uncertainty quantification. In experiments, it outperforms comparator methods including black-box models, converges more rapidly towards relevant concepts and away from spuriously correlated ones, and is more robust to out-of-distribution samples.
Vector-ICL: In-context Learning with Continuous Vector Representations
Oct 08, 2024
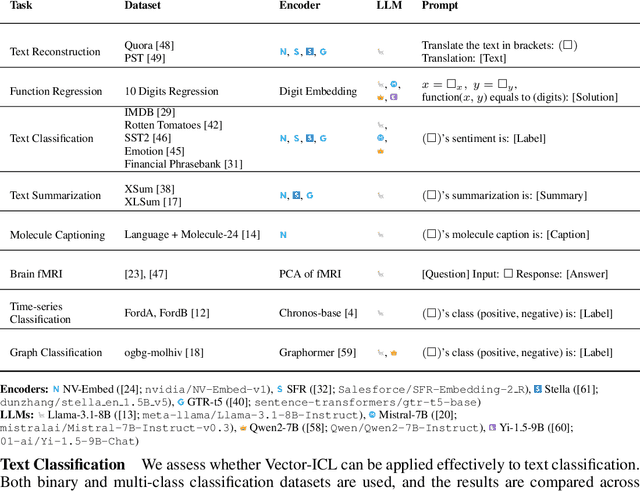
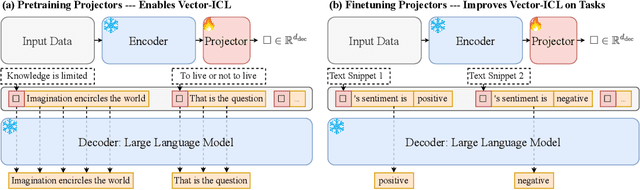
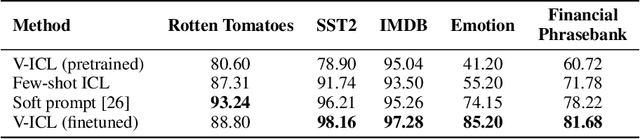
Large language models (LLMs) have shown remarkable in-context learning (ICL) capabilities on textual data. We explore whether these capabilities can be extended to continuous vectors from diverse domains, obtained from black-box pretrained encoders. By aligning input data with an LLM's embedding space through lightweight projectors, we observe that LLMs can effectively process and learn from these projected vectors, which we term Vector-ICL. In particular, we find that pretraining projectors with general language modeling objectives enables Vector-ICL, while task-specific finetuning further enhances performance. In our experiments across various tasks and modalities, including text reconstruction, numerical function regression, text classification, summarization, molecule captioning, time-series classification, graph classification, and fMRI decoding, Vector-ICL often surpasses both few-shot ICL and domain-specific model or tuning. We further conduct analyses and case studies, indicating the potential of LLMs to process vector representations beyond traditional token-based paradigms.
A generative framework to bridge data-driven models and scientific theories in language neuroscience
Oct 01, 2024


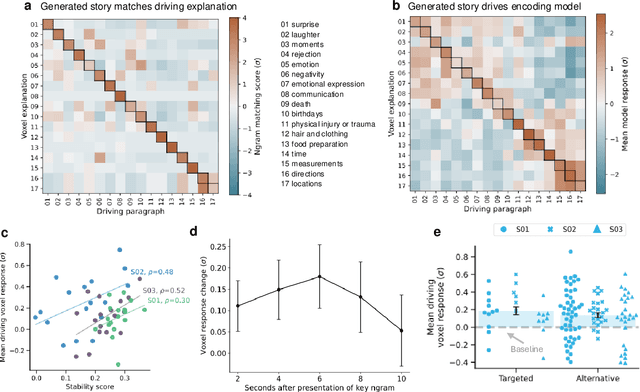
Representations from large language models are highly effective at predicting BOLD fMRI responses to language stimuli. However, these representations are largely opaque: it is unclear what features of the language stimulus drive the response in each brain area. We present generative explanation-mediated validation, a framework for generating concise explanations of language selectivity in the brain and then validating those explanations in follow-up experiments that use synthetic stimuli. This approach is successful at explaining selectivity both in individual voxels and cortical regions of interest (ROIs).We show that explanatory accuracy is closely related to the predictive power and stability of the underlying statistical models. These results demonstrate that LLMs can be used to bridge the widening gap between data-driven models and formal scientific theories.