 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason in 13 Parameters
Feb 04, 2026Recent research has shown that language models can learn to \textit{reason}, often via reinforcement learning. Some work even trains low-rank parameterizations for reasoning, but conventional LoRA cannot scale below the model dimension. We question whether even rank=1 LoRA is necessary for learning to reason and propose TinyLoRA, a method for scaling low-rank adapters to sizes as small as one parameter. Within our new parameterization, we are able to train the 8B parameter size of Qwen2.5 to 91\% accuracy on GSM8K with only 13 trained parameters in bf16 (26 total bytes). We find this trend holds in general: we are able to recover 90\% of performance improvements while training $1000x$ fewer parameters across a suite of more difficult learning-to-reason benchmarks such as AIME, AMC, and MATH500. Notably, we are only able to achieve such strong performance with RL: models trained using SFT require $100-1000x$ larger updates to reach the same performance.
Approximating Language Model Training Data from Weights
Jun 18, 2025Modern language models often have open weights but closed training data. We formalize the problem of data approximation from model weights and propose several baselines and metrics. We develop a gradient-based approach that selects the highest-matching data from a large public text corpus and show its effectiveness at recovering useful data given only weights of the original and finetuned models. Even when none of the true training data is known, our method is able to locate a small subset of public Web documents can be used to train a model to close to the original model performance given models trained for both classification and supervised-finetuning. On the AG News classification task, our method improves performance from 65% (using randomly selected data) to 80%, approaching the expert benchmark of 88%. When applied to a model trained with SFT on MSMARCO web documents, our method reduces perplexity from 3.3 to 2.3, compared to an expert LLAMA model's perplexity of 2.0.
How much do language models memorize?
May 30, 2025We propose a new method for estimating how much a model ``knows'' about a datapoint and use it to measure the capacity of modern language models. Prior studies of language model memorization have struggled to disentangle memorization from generalization. We formally separate memorization into two components: \textit{unintended memorization}, the information a model contains about a specific dataset, and \textit{generalization}, the information a model contains about the true data-generation process. When we completely eliminate generalization, we can compute the total memorization, which provides an estimate of model capacity: our measurements estimate that GPT-style models have a capacity of approximately 3.6 bits per parameter. We train language models on datasets of increasing size and observe that models memorize until their capacity fills, at which point ``grokking'' begins, and unintended memorization decreases as models begin to generalize. We train hundreds of transformer language models ranging from $500K$ to $1.5B$ parameters and produce a series of scaling laws relating model capacity and data size to membership inference.
Harnessing the Universal Geometry of Embeddings
May 18, 2025We introduce the first method for translating text embeddings from one vector space to another without any paired data, encoders, or predefined sets of matches. Our unsupervised approach translates any embedding to and from a universal latent representation (i.e., a universal semantic structure conjectured by the Platonic Representation Hypothesis). Our translations achieve high cosine similarity across model pairs with different architectures, parameter counts, and training datasets. The ability to translate unknown embeddings into a different space while preserving their geometry has serious implications for the security of vector databases. An adversary with access only to embedding vectors can extract sensitive information about the underlying documents, sufficient for classification and attribute inference.
Universal Zero-shot Embedding Inversion
Mar 31, 2025Embedding inversion, i.e., reconstructing text given its embedding and black-box access to the embedding encoder, is a fundamental problem in both NLP and security. From the NLP perspective, it helps determine how much semantic information about the input is retained in the embedding. From the security perspective, it measures how much information is leaked by vector databases and embedding-based retrieval systems. State-of-the-art methods for embedding inversion, such as vec2text, have high accuracy but require (a) training a separate model for each embedding, and (b) a large number of queries to the corresponding encoder. We design, implement, and evaluate ZSInvert, a zero-shot inversion method based on the recently proposed adversarial decoding technique. ZSInvert is fast, query-efficient, and can be used for any text embedding without training an embedding-specific inversion model. We measure the effectiveness of ZSInvert on several embeddings and demonstrate that it recovers key semantic information about the corresponding texts.
DIRI: Adversarial Patient Reidentification with Large Language Models for Evaluating Clinical Text Anonymization
Oct 22, 2024Sharing protected health information (PHI) is critical for furthering biomedical research. Before data can be distributed, practitioners often perform deidentification to remove any PHI contained in the text. Contemporary deidentification methods are evaluated on highly saturated datasets (tools achieve near-perfect accuracy) which may not reflect the full variability or complexity of real-world clinical text and annotating them is resource intensive, which is a barrier to real-world applications. To address this gap, we developed an adversarial approach using a large language model (LLM) to re-identify the patient corresponding to a redacted clinical note and evaluated the performance with a novel De-Identification/Re-Identification (DIRI) method. Our method uses a large language model to reidentify the patient corresponding to a redacted clinical note. We demonstrate our method on medical data from Weill Cornell Medicine anonymized with three deidentification tools: rule-based Philter and two deep-learning-based models, BiLSTM-CRF and ClinicalBERT. Although ClinicalBERT was the most effective, masking all identified PII, our tool still reidentified 9% of clinical notes Our study highlights significant weaknesses in current deidentification technologies while providing a tool for iterative development and improvement.
Contextual Document Embeddings
Oct 03, 2024



Dense document embeddings are central to neural retrieval. The dominant paradigm is to train and construct embeddings by running encoders directly on individual documents. In this work, we argue that these embeddings, while effective, are implicitly out-of-context for targeted use cases of retrieval, and that a contextualized document embedding should take into account both the document and neighboring documents in context - analogous to contextualized word embeddings. We propose two complementary methods for contextualized document embeddings: first, an alternative contrastive learning objective that explicitly incorporates the document neighbors into the intra-batch contextual loss; second, a new contextual architecture that explicitly encodes neighbor document information into the encoded representation. Results show that both methods achieve better performance than biencoders in several settings, with differences especially pronounced out-of-domain. We achieve state-of-the-art results on the MTEB benchmark with no hard negative mining, score distillation, dataset-specific instructions, intra-GPU example-sharing, or extremely large batch sizes. Our method can be applied to improve performance on any contrastive learning dataset and any biencoder.
Soft Prompts Go Hard: Steering Visual Language Models with Hidden Meta-Instructions
Jul 12, 2024



We introduce a new type of indirect injection vulnerabilities in language models that operate on images: hidden "meta-instructions" that influence how the model interprets the image and steer the model's outputs to express an adversary-chosen style, sentiment, or point of view. We explain how to create meta-instructions by generating images that act as soft prompts. Unlike jailbreaking attacks and adversarial examples, the outputs resulting from these images are plausible and based on the visual content of the image, yet follow the adversary's (meta-)instructions. We describe the risks of these attacks, including misinformation and spin, evaluate their efficacy for multiple visual language models and adversarial meta-objectives, and demonstrate how they can "unlock" the capabilities of the underlying language models that are unavailable via explicit text instructions. Finally, we discuss defenses against these attacks.
Corpus Poisoning via Approximate Greedy Gradient Descent
Jun 07, 2024
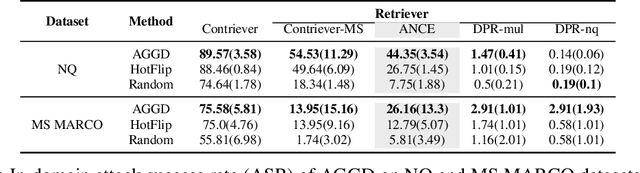


Dense retrievers are widely used in information retrieval and have also been successfully extended to other knowledge intensive areas such as language models, e.g., Retrieval-Augmented Generation (RAG) systems. Unfortunately, they have recently been shown to be vulnerable to corpus poisoning attacks in which a malicious user injects a small fraction of adversarial passages into the retrieval corpus to trick the system into returning these passages among the top-ranked results for a broad set of user queries. Further study is needed to understand the extent to which these attacks could limit the deployment of dense retrievers in real-world applications. In this work, we propose Approximate Greedy Gradient Descent (AGGD), a new attack on dense retrieval systems based on the widely used HotFlip method for efficiently generating adversarial passages. We demonstrate that AGGD can select a higher quality set of token-level perturbations than HotFlip by replacing its random token sampling with a more structured search. Experimentally, we show that our method achieves a high attack success rate on several datasets and using several retrievers, and can generalize to unseen queries and new domains. Notably, our method is extremely effective in attacking the ANCE retrieval model, achieving attack success rates that are 17.6\% and 13.37\% higher on the NQ and MS MARCO datasets, respectively, compared to HotFlip. Additionally, we demonstrate AGGD's potential to replace HotFlip in other adversarial attacks, such as knowledge poisoning of RAG systems.\footnote{Code can be find in \url{https://github.com/JinyanSu1/AGGD}}
Crafting Interpretable Embeddings by Asking LLMs Questions
May 26, 2024Large language models (LLMs) have rapidly improved text embeddings for a growing array of natural-language processing tasks. However, their opaqueness and proliferation into scientific domains such as neuroscience have created a growing need for interpretability. Here, we ask whether we can obtain interpretable embeddings through LLM prompting. We introduce question-answering embeddings (QA-Emb), embeddings where each feature represents an answer to a yes/no question asked to an LLM. Training QA-Emb reduces to selecting a set of underlying questions rather than learning model weights. We use QA-Emb to flexibly generate interpretable models for predicting fMRI voxel responses to language stimuli. QA-Emb significantly outperforms an established interpretable baseline, and does so while requiring very few questions. This paves the way towards building flexible feature spaces that can concretize and evaluate our understanding of semantic brain representations. We additionally find that QA-Emb can be effectively approximated with an efficient model, and we explore broader applications in simple NLP tasks.