Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Prompts by Inverting LLM Outputs
Paper and Code
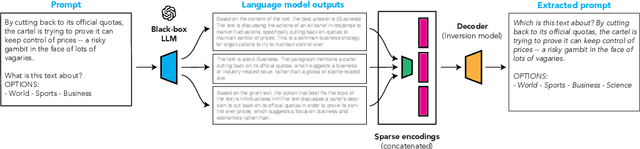


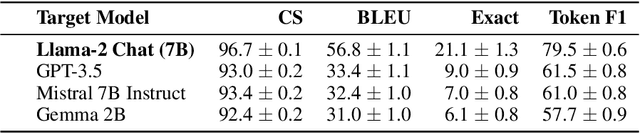
We consider the problem of language model inversion: given outputs of a language model, we seek to extract the prompt that generated these outputs. We develop a new black-box method, output2prompt, that learns to extract prompts without access to the model's logits and without adversarial or jailbreaking queries. In contrast to previous work, output2prompt only needs outputs of normal user queries. To improve memory efficiency, output2prompt employs a new sparse encoding techique. We measure the efficacy of output2prompt on a variety of user and system prompts and demonstrate zero-shot transferability across different LLMs.
View paper on