 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing the Universal Geometry of Embeddings
May 18, 2025We introduce the first method for translating text embeddings from one vector space to another without any paired data, encoders, or predefined sets of matches. Our unsupervised approach translates any embedding to and from a universal latent representation (i.e., a universal semantic structure conjectured by the Platonic Representation Hypothesis). Our translations achieve high cosine similarity across model pairs with different architectures, parameter counts, and training datasets. The ability to translate unknown embeddings into a different space while preserving their geometry has serious implications for the security of vector databases. An adversary with access only to embedding vectors can extract sensitive information about the underlying documents, sufficient for classification and attribute inference.
Universal Zero-shot Embedding Inversion
Mar 31, 2025Embedding inversion, i.e., reconstructing text given its embedding and black-box access to the embedding encoder, is a fundamental problem in both NLP and security. From the NLP perspective, it helps determine how much semantic information about the input is retained in the embedding. From the security perspective, it measures how much information is leaked by vector databases and embedding-based retrieval systems. State-of-the-art methods for embedding inversion, such as vec2text, have high accuracy but require (a) training a separate model for each embedding, and (b) a large number of queries to the corresponding encoder. We design, implement, and evaluate ZSInvert, a zero-shot inversion method based on the recently proposed adversarial decoding technique. ZSInvert is fast, query-efficient, and can be used for any text embedding without training an embedding-specific inversion model. We measure the effectiveness of ZSInvert on several embeddings and demonstrate that it recovers key semantic information about the corresponding texts.
Adversarial Hubness in Multi-Modal Retrieval
Dec 18, 2024Hubness is a phenomenon in high-dimensional vector spaces where a single point from the natural distribution is unusually close to many other points. This is a well-known problem in information retrieval that causes some items to accidentally (and incorrectly) appear relevant to many queries. In this paper, we investigate how attackers can exploit hubness to turn any image or audio input in a multi-modal retrieval system into an adversarial hub. Adversarial hubs can be used to inject universal adversarial content (e.g., spam) that will be retrieved in response to thousands of different queries, as well as for targeted attacks on queries related to specific, attacker-chosen concepts. We present a method for creating adversarial hubs and evaluate the resulting hubs on benchmark multi-modal retrieval datasets and an image-to-image retrieval system based on a tutorial from Pinecone, a popular vector database. For example, in text-caption-to-image retrieval, a single adversarial hub is retrieved as the top-1 most relevant image for more than 21,000 out of 25,000 test queries (by contrast, the most common natural hub is the top-1 response to only 102 queries). We also investigate whether techniques for mitigating natural hubness are an effective defense against adversarial hubs, and show that they are not effective against hubs that target queries related to specific concepts.
Controlled Generation of Natural Adversarial Documents for Stealthy Retrieval Poisoning
Oct 03, 2024Recent work showed that retrieval based on embedding similarity (e.g., for retrieval-augmented generation) is vulnerable to poisoning: an adversary can craft malicious documents that are retrieved in response to broad classes of queries. We demonstrate that previous, HotFlip-based techniques produce documents that are very easy to detect using perplexity filtering. Even if generation is constrained to produce low-perplexity text, the resulting documents are recognized as unnatural by LLMs and can be automatically filtered from the retrieval corpus. We design, implement, and evaluate a new controlled generation technique that combines an adversarial objective (embedding similarity) with a "naturalness" objective based on soft scores computed using an open-source, surrogate LLM. The resulting adversarial documents (1) cannot be automatically detected using perplexity filtering and/or other LLMs, except at the cost of significant false positives in the retrieval corpus, yet (2) achieve similar poisoning efficacy to easily-detectable documents generated using HotFlip, and (3) are significantly more effective than prior methods for energy-guided generation, such as COLD.
Soft Prompts Go Hard: Steering Visual Language Models with Hidden Meta-Instructions
Jul 12, 2024



We introduce a new type of indirect injection vulnerabilities in language models that operate on images: hidden "meta-instructions" that influence how the model interprets the image and steer the model's outputs to express an adversary-chosen style, sentiment, or point of view. We explain how to create meta-instructions by generating images that act as soft prompts. Unlike jailbreaking attacks and adversarial examples, the outputs resulting from these images are plausible and based on the visual content of the image, yet follow the adversary's (meta-)instructions. We describe the risks of these attacks, including misinformation and spin, evaluate their efficacy for multiple visual language models and adversarial meta-objectives, and demonstrate how they can "unlock" the capabilities of the underlying language models that are unavailable via explicit text instructions. Finally, we discuss defenses against these attacks.
Extracting Prompts by Inverting LLM Outputs
May 23, 2024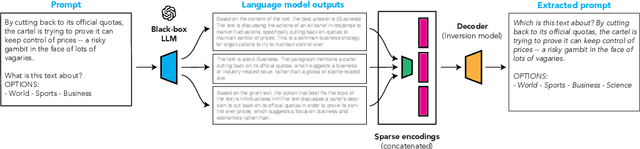


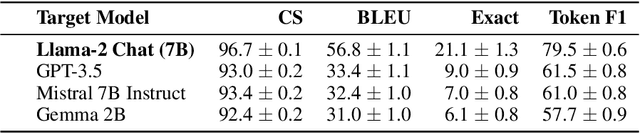
We consider the problem of language model inversion: given outputs of a language model, we seek to extract the prompt that generated these outputs. We develop a new black-box method, output2prompt, that learns to extract prompts without access to the model's logits and without adversarial or jailbreaking queries. In contrast to previous work, output2prompt only needs outputs of normal user queries. To improve memory efficiency, output2prompt employs a new sparse encoding techique. We measure the efficacy of output2prompt on a variety of user and system prompts and demonstrate zero-shot transferability across different LLMs.